Récemment, j'ai vu 2 bons articles sur l'inférence logique complexe LLM+KG
Récemment, j'ai vu 2 bons articles sur l'inférence logique complexe LLM+KG
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Les difficultés de l'inférence sur les graphes de connaissances
Les graphes de connaissances (KG), en tant que porteurs centraux de connaissances structurées, sont confrontés à trois principaux problèmes :
- Complexité : explosion combinatoire des opérations multi-sauts, d'intersection et d'union, de négation, etc.
- Incomplétude : le bruit et les lacunes sont omniprésents dans les KG du monde réel
- Généralisation : les méthodes d'intégration traditionnelles sont difficiles à transférer entre les ensembles de données
Les solutions traditionnelles (telles que Query2Box, BetaE) reposent sur l'espace d'intégration géométrique, modélisant les opérations logiques comme des opérations vectorielles/de boîte, mais avec une perte d'informations importante lors de l'inférence en profondeur. Comment faire en sorte que le modèle comprenne à la fois la structure logique et puisse raisonner de manière flexible ? L'essor des grands modèles de langage (LLM) offre une nouvelle approche.
 Figure 1 : Décomposition de la chaîne de requête et processus d'inférence LLM de LARK. Décomposer les requêtes complexes multi-opérations en sous-requêtes à opération unique et les résoudre progressivement.
Figure 1 : Décomposition de la chaîne de requête et processus d'inférence LLM de LARK. Décomposer les requêtes complexes multi-opérations en sous-requêtes à opération unique et les résoudre progressivement.
II. Solution : Héritage et évolution des méthodes de deux générations
LARK (2023) —— Un travail pionnier
Figure 2 : Stratégies de décomposition pour 14 types de requêtes. 3p est divisé en 3 projections, 3i est divisé en 3 projections + 1 intersection.
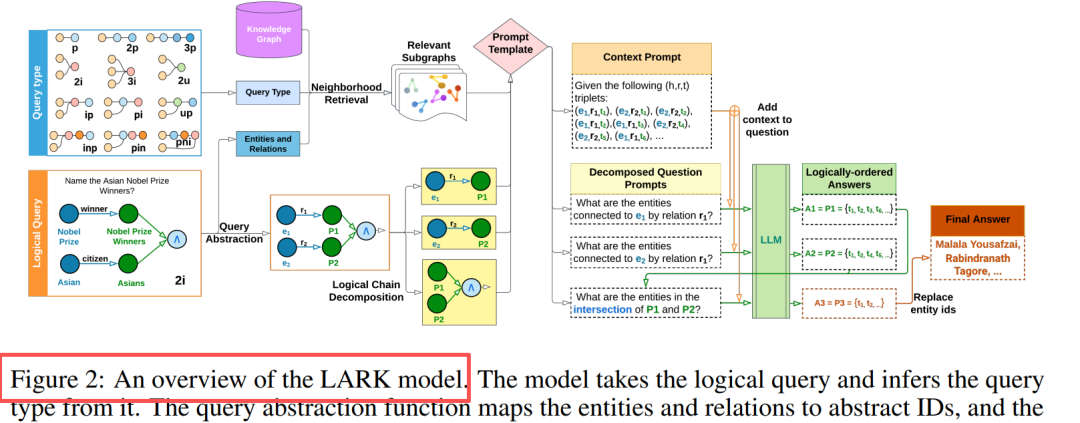 Innovation principale : abstraction de requête + décomposition de chaîne logique
Innovation principale : abstraction de requête + décomposition de chaîne logique
Conception des composants Abstraction de requête : remplacement des entités/relations par des ID, élimination des hallucinations, amélioration de la généralisation Récupération de voisinage : parcours en profondeur d'abord k-hop (k=3), extraction du sous-graphe pertinent Décomposition en chaîne : requête multi-opérations → séquence de sous-requêtes à opération unique Inférence séquentielle : mise en cache des résultats intermédiaires, remplacement ordonné logique des espaces réservés Observation clé : les LLM excellent dans les requêtes simples, les performances s'améliorent de 20 à 33 % après la décomposition des requêtes complexes.
ROG (2025) —— Version avancée
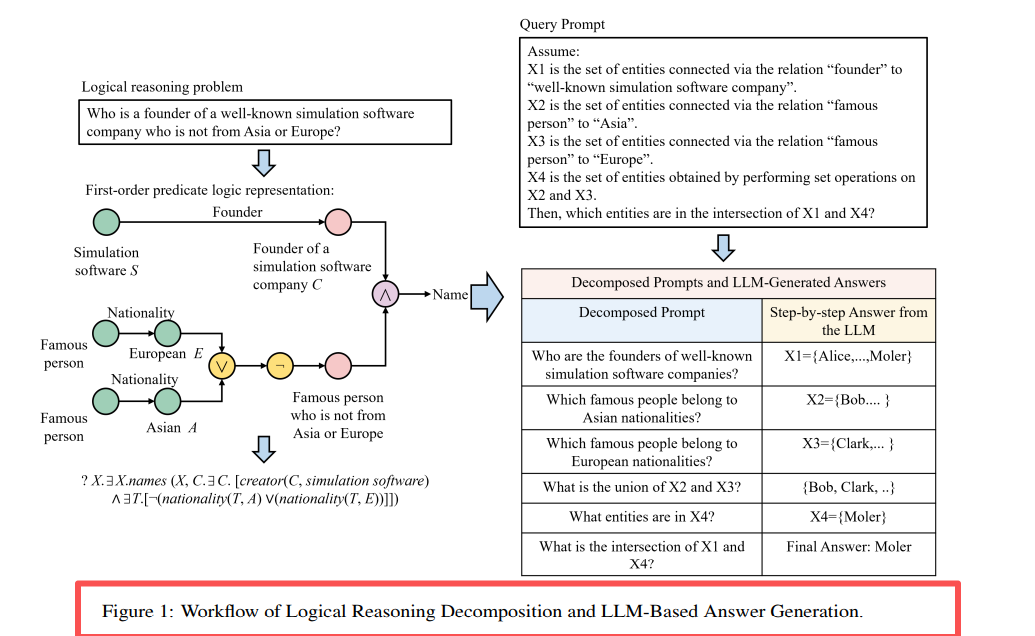 Hérite du framework LARK, ajoutant un mécanisme de consensus d'Agent :
Hérite du framework LARK, ajoutant un mécanisme de consensus d'Agent :
ROG = Noyau LARK + Collaboration multi-Agent + Renforcement de la chaîne de pensée
Explication des améliorations
Conception d'Agent : Agent = Base de connaissances + LLM, prise de décision par consensus multi-Agent
Amélioration CoT : modèles d'invite de chaîne de pensée plus clairs
Adaptation domestique : basé sur ChatGLM+Neo4j, ciblant les domaines verticaux tels que l'électricité
 Modèle de flux de données de ROG
Modèle de flux de données de ROG
Saut de performance : sur FB15k, la MRR de la requête ip (projection après intersection) passe de 29,3 → 62,0, soit une augmentation de 111 % !
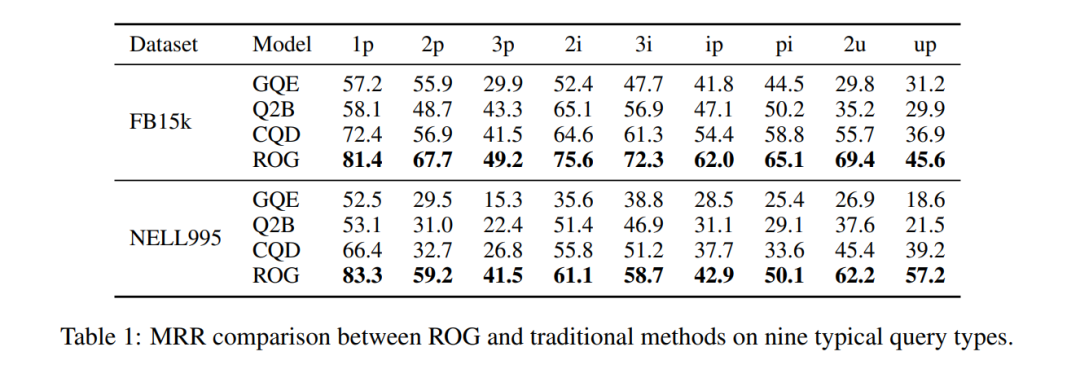 Tableau 1 : Comparaison MRR de l'ensemble de données FB15k. ROG est globalement en tête, avec l'amélioration la plus significative pour les requêtes composites.
Tableau 1 : Comparaison MRR de l'ensemble de données FB15k. ROG est globalement en tête, avec l'amélioration la plus significative pour les requêtes composites.
III. Établissement du paradigme et orientations futures
Les articles des deux générations valident conjointement un paradigme :
"Récupération augmentée + Décomposition de requête + Inférence LLM" est une voie efficace pour l'inférence logique complexe KG.
Tendances clés :
- L'abstraction est cruciale —— Supprimer le bruit sémantique, se concentrer sur la structure logique
- La stratégie de décomposition détermine la limite supérieure —— La décomposition en chaîne est plus fiable que l'approche de bout en bout
- La capacité du modèle continue de se libérer —— De Llama2-7B à ChatGLM, les progrès de la base apportent des gains significatifs
Bien que le mécanisme d'Agent de ROG améliore l'interprétabilité, l'innovation principale réside dans l'optimisation de l'ingénierie plutôt que dans une percée théorique. Les orientations futures pourraient résider dans : les stratégies de décomposition dynamique (complexité de requête auto-adaptative), la fusion KG multimodale et la validation de domaine ouvert à plus grande échelle.



