Recentemente, ho visto 2 ottimi articoli su LLM+KG per il ragionamento logico complesso
Recentemente, ho visto 2 ottimi articoli su LLM+KG per il ragionamento logico complesso
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Le difficoltà del ragionamento sui grafi di conoscenza
I grafi di conoscenza (KG), in quanto principali vettori di conoscenza strutturata, affrontano tre principali problemi:
- Complessità: esplosione combinatoria di operazioni come il ragionamento multi-hop, intersezioni e unioni, negazioni, ecc.
- Incompletezza: i KG del mondo reale presentano comunemente rumore e lacune
- Generalizzazione: i metodi di embedding tradizionali sono difficili da trasferire tra dataset
Le soluzioni tradizionali (come Query2Box, BetaE) si basano su spazi di embedding geometrici, modellando le operazioni logiche come operazioni vettoriali/di box, ma subiscono una grave perdita di informazioni durante il ragionamento profondo. Come fare in modo che il modello comprenda sia la struttura logica che il ragionamento flessibile? L'ascesa dei modelli linguistici di grandi dimensioni (LLM) offre un nuovo approccio.
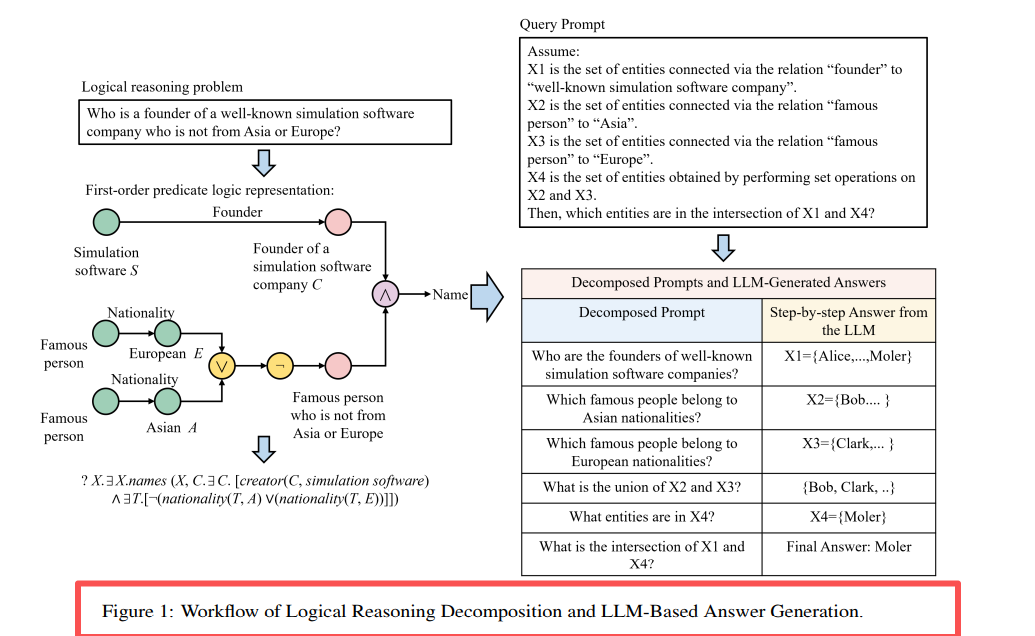
 Figura 1: Decomposizione della catena di query e flusso di ragionamento LLM di LARK. Scompone query complesse multi-operazione in sottoquery a operazione singola, risolvendo gradualmente.
Figura 1: Decomposizione della catena di query e flusso di ragionamento LLM di LARK. Scompone query complesse multi-operazione in sottoquery a operazione singola, risolvendo gradualmente.
II. Soluzione: eredità ed evoluzione di due generazioni di metodi
LARK (2023) —— Opera pionieristica
Figura 2: Strategie di decomposizione per 14 tipi di query. 3p è scomposto in 3 proiezioni, 3i è scomposto in 3 proiezioni + 1 intersezione.
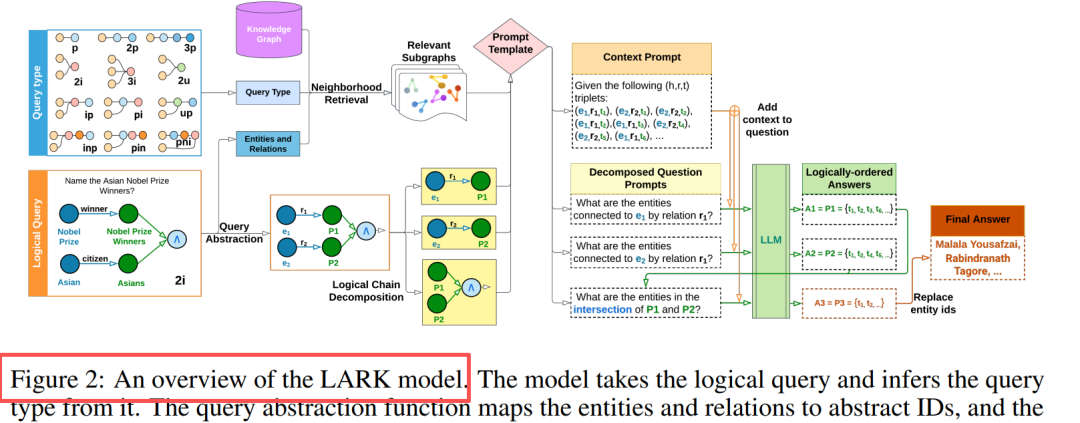 Innovazione principale: astrazione della query + decomposizione della catena logica
Innovazione principale: astrazione della query + decomposizione della catena logica
Design dei componenti:
- Astrazione della query: sostituzione di entità/relazioni con ID, eliminando le allucinazioni e migliorando la generalizzazione
- Ricerca di vicinato: attraversamento in profondità k-hop (k=3), estrazione di sottografi correlati
- Decomposizione a catena: query multi-operazione → sequenza di sottoquery a operazione singola
- Ragionamento sequenziale: memorizzazione nella cache dei risultati intermedi, sostituzione ordinata logica dei segnaposto
Insight chiave: gli LLM eccellono nelle query semplici, la scomposizione di query complesse aumenta le prestazioni del 20%-33%.
ROG (2025) —— Versione avanzata
 Eredita il framework LARK, aggiungendo un meccanismo di consenso Agent:
Eredita il framework LARK, aggiungendo un meccanismo di consenso Agent:
ROG = Nucleo LARK + Collaborazione multi-Agent + Rafforzamento della catena di pensiero
Spiegazione dei miglioramenti:
- Design dell'Agent: Agente = Knowledge Base + LLM, decisione di consenso multi-Agent
- Potenziamento CoT: modelli di prompt della catena di pensiero più chiari
- Adattamento nazionale: basato su ChatGLM+Neo4j, orientato a settori verticali come l'energia elettrica
 Modello di flusso di dati di ROG
Modello di flusso di dati di ROG
Salto di prestazioni: su FB15k, la query ip (proiezione dopo l'intersezione) MRR è passata da 29,3→62,0, con un aumento del 111%!
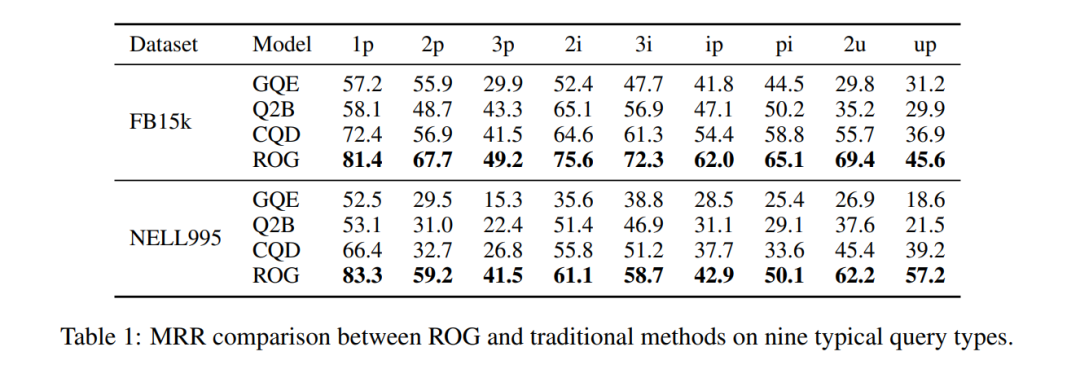 Tabella 1: Confronto MRR del dataset FB15k. ROG è completamente leader, con il miglioramento più significativo nelle query composte.
Tabella 1: Confronto MRR del dataset FB15k. ROG è completamente leader, con il miglioramento più significativo nelle query composte.
III. Stabilimento del paradigma e direzioni future
Due generazioni di articoli hanno convalidato congiuntamente un paradigma:
"Ricerca potenziata + Decomposizione della query + Ragionamento LLM" è un percorso efficace per il ragionamento logico complesso KG.
Tendenze chiave:
- L'astrazione è fondamentale —— Eliminare il rumore semantico, concentrandosi sulla struttura logica
- La strategia di decomposizione determina il limite superiore —— La scomposizione a catena è più affidabile dell'end-to-end
- La capacità del modello continua a essere rilasciata —— Da Llama2-7B a ChatGLM, il progresso della base porta a guadagni significativi
Il meccanismo Agent di ROG migliora l'interpretabilità, ma l'innovazione principale risiede nell'ottimizzazione ingegneristica piuttosto che nella svolta teorica. Le direzioni future potrebbero riguardare: strategie di decomposizione dinamiche (adattive alla complessità della query), fusione KG multimodale e convalida open-domain su scala più ampia.



