സമീപകാലത്ത്, LLM+KG ഉപയോഗിച്ച് സങ്കീർണ്ണമായ ലോജിക്കൽ ന്യായവാദം നടത്തുന്ന രണ്ട് മികച്ച പ്രബന്ധങ്ങൾ കണ്ടു
സമീപകാലത്ത്, LLM+KG ഉപയോഗിച്ച് സങ്കീർണ്ണമായ ലോജിക്കൽ ന്യായവാദം നടത്തുന്ന രണ്ട് മികച്ച പ്രബന്ധങ്ങൾ കണ്ടു.
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. വിജ്ഞാന ഗ്രാഫ് ന്യായവാദത്തിന്റെ വിഷമതകൾ
വിജ്ഞാന ഗ്രാഫ് (KG) ഘടനാപരമായ വിജ്ഞാനത്തിന്റെ പ്രധാന വാഹകനെന്ന നിലയിൽ മൂന്ന് പ്രധാന പ്രശ്നങ്ങൾ നേരിടുന്നു:
- സങ്കീർണ്ണത: മൾട്ടി-ഹോപ്പ് ന്യായവാദം, ചേരുവകൾ, യൂണിയനുകൾ, നിഷേധങ്ങൾ തുടങ്ങിയ പ്രവർത്തനങ്ങളുടെ സംയോജന സ്ഫോടനം.
- അപൂർണ്ണത: യഥാർത്ഥ ലോകത്തിലെ KG-കളിൽ പൊതുവെ ശബ്ദവും കുറവുകളും ഉണ്ട്.
- സാമാന്യവൽക്കരണം: പരമ്പരാഗത എംബെഡിംഗ് രീതികൾക്ക് ഡാറ്റാ സെറ്റുകൾക്കിടയിൽ മാറാൻ കഴിയില്ല.
Query2Box, BetaE പോലുള്ള പരമ്പരാഗത സ്കീമുകൾ ജ്യാമിതീയ എംബെഡിംഗ് സ്പേസിനെ ആശ്രയിക്കുന്നു, വെക്റ്റർ/ബോക്സ് പ്രവർത്തനങ്ങളായി ലോജിക്കൽ പ്രവർത്തനങ്ങളെ മോഡൽ ചെയ്യുന്നു, എന്നാൽ ആഴത്തിലുള്ള ന്യായവാദത്തിൽ വിവരങ്ങൾ ഗണ്യമായി നഷ്ടപ്പെടുന്നു. മോഡലിന് ലോജിക്കൽ ഘടന മനസ്സിലാക്കാനും ഫലപ്രദമായി ന്യായവാദം നടത്താനും എങ്ങനെ കഴിയും? വലിയ ഭാഷാ മോഡലുകളുടെ (LLM) ഉയർച്ച ഒരു പുതിയ ചിന്താഗതി നൽകുന്നു.
 ചിത്രം 1: LARK-ന്റെ അന്വേഷണ ശൃംഖല വിഭജനവും LLM ന്യായവാദ പ്രക്രിയയും. സങ്കീർണ്ണമായ മൾട്ടി-ഓപ്പറേഷൻ അന്വേഷണങ്ങളെ സിംഗിൾ-ഓപ്പറേഷൻ ഉപ-അന്വേഷണങ്ങളായി വിഭജിച്ച് ക്രമേണ പരിഹരിക്കുന്നു.
ചിത്രം 1: LARK-ന്റെ അന്വേഷണ ശൃംഖല വിഭജനവും LLM ന്യായവാദ പ്രക്രിയയും. സങ്കീർണ്ണമായ മൾട്ടി-ഓപ്പറേഷൻ അന്വേഷണങ്ങളെ സിംഗിൾ-ഓപ്പറേഷൻ ഉപ-അന്വേഷണങ്ങളായി വിഭജിച്ച് ക്രമേണ പരിഹരിക്കുന്നു.
II. പരിഹാരം: രണ്ട് തലമുറ രീതികളുടെ പാരമ്പര്യവും പരിണാമവും
LARK (2023) - ഒരു തുടക്കം
ചിത്രം 2: 14 തരം അന്വേഷണങ്ങളുടെ വിഘടന തന്ത്രം. 3p എന്നത് 3 പ്രൊജക്ഷനുകളായി വിഭജിക്കുന്നു, 3i എന്നത് 3 പ്രൊജക്ഷനുകളായും 1 ഇന്റർസെക്ഷനായും വിഭജിക്കുന്നു.
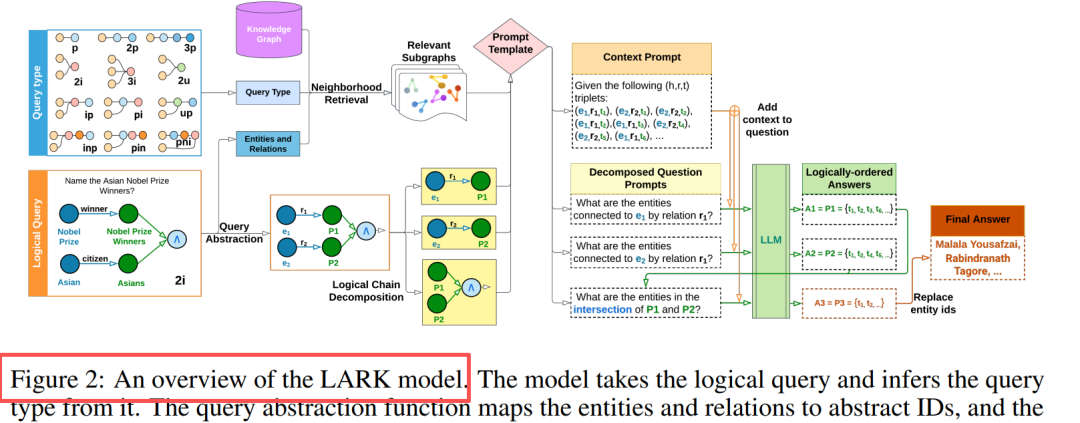 പ്രധാന കണ്ടുപിടുത്തം: അന്വേഷണ അബ്സ്ട്രാക്ഷൻ + ലോജിക്കൽ ശൃംഖല വിഭജനം
പ്രധാന കണ്ടുപിടുത്തം: അന്വേഷണ അബ്സ്ട്രാക്ഷൻ + ലോജിക്കൽ ശൃംഖല വിഭജനം
ഘടക രൂപകൽപ്പന: അന്വേഷണ അബ്സ്ട്രാക്ഷൻ: എന്റിറ്റി/റിലേഷൻ ഐഡി ഉപയോഗിച്ച് മാറ്റിസ്ഥാപിക്കുക, മിഥ്യാബോധം ഇല്ലാതാക്കുക, സാമാന്യവൽക്കരണം മെച്ചപ്പെടുത്തുക. നെയിബർഹുഡ് വീണ്ടെടുക്കൽ: k-hop ഡെപ്ത് ഫസ്റ്റ് ട്രാവേഴ്സൽ (k=3), അനുബന്ധ സബ്ഗ്രാഫ് എക്സ്ട്രാക്റ്റ് ചെയ്യുക. ചെയിൻ വിഭജനം: മൾട്ടി-ഓപ്പറേഷൻ അന്വേഷണങ്ങൾ → സിംഗിൾ-ഓപ്പറേഷൻ ഉപ-അന്വേഷണ ശ്രേണി. സീക്വൻഷ്യൽ ന്യായവാദം: ഇന്റർമീഡിയറ്റ് ഫലങ്ങൾ കാഷെ ചെയ്യുക, ലോജിക്കൽ ഓർഡർ അനുസരിച്ച് പ്ലേസ്ഹോൾഡറുകൾ മാറ്റിസ്ഥാപിക്കുക. പ്രധാന ഉൾക്കാഴ്ച: LLM-ന് ലളിതമായ അന്വേഷണങ്ങളിൽ കഴിവുണ്ട്, സങ്കീർണ്ണമായ അന്വേഷണങ്ങൾ വിഭജിച്ച ശേഷം പ്രകടനം 20%-33% വരെ മെച്ചപ്പെടുന്നു.
ROG (2025) - ഒരു വിപുലമായ പതിപ്പ്
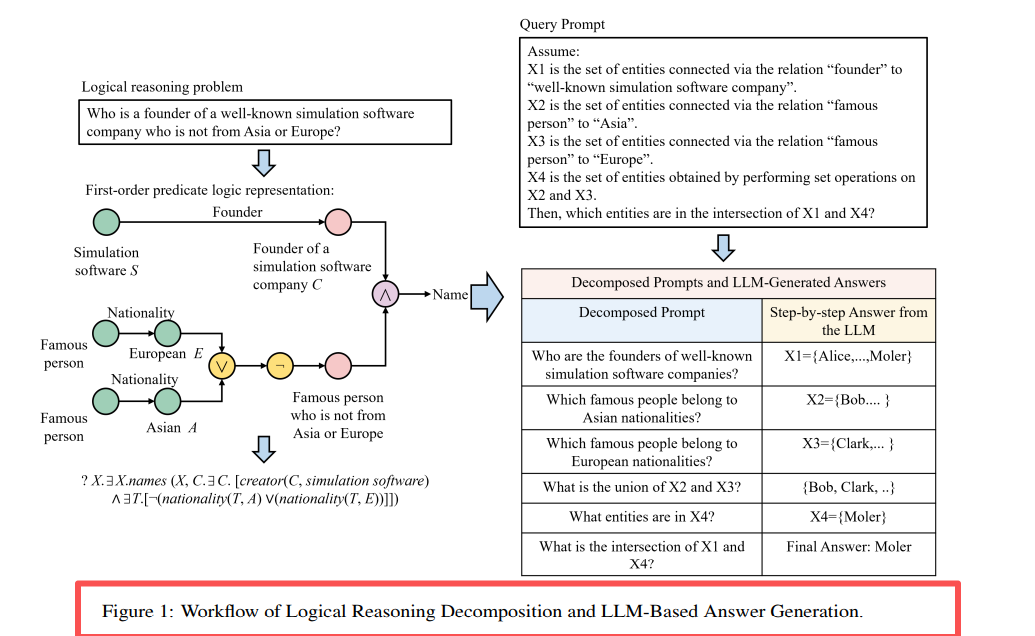 LARK ചട്ടക്കൂട് പിന്തുടരുന്നു, ഒരു പുതിയ ഏജന്റ് സമവായ സംവിധാനം ചേർക്കുന്നു:
LARK ചട്ടക്കൂട് പിന്തുടരുന്നു, ഒരു പുതിയ ഏജന്റ് സമവായ സംവിധാനം ചേർക്കുന്നു:
ROG = LARK കോർ + മൾട്ടി-ഏജന്റ് സഹകരണം + ചിന്താ ശൃംഖല ശക്തിപ്പെടുത്തൽ
മെച്ചപ്പെടുത്തലുകൾ വിശദീകരിക്കുന്നു: ഏജന്റ് ഡിസൈൻ: ഇന്റലിജന്റ് ബോഡി = വിജ്ഞാന അടിത്തറ + LLM, മൾട്ടി-ഏജന്റ് സമവായ തീരുമാനം. CoT മെച്ചപ്പെടുത്തൽ: കൂടുതൽ വ്യക്തമായ ചിന്താ ശൃംഖല പ്രോംപ്റ്റ് ടെംപ്ലേറ്റ്. ആഭ്യന്തരവൽക്കരണ അഡാപ്റ്റേഷൻ: ChatGLM+Neo4j അടിസ്ഥാനമാക്കി, പവർ പോലുള്ള ലംബ മേഖലകൾക്കായി.
 ROG-യുടെ ഡാറ്റാ ഫ്ലോ മോഡൽ
ROG-യുടെ ഡാറ്റാ ഫ്ലോ മോഡൽ
പ്രകടന മുന്നേറ്റം: FB15k-ൽ, ip അന്വേഷണങ്ങൾ (ഇന്റർസെക്ഷന് ശേഷം പ്രൊജക്ഷൻ) MRR 29.3-ൽ നിന്ന് 62.0 ആയി ഉയർന്നു, 111% വർദ്ധനവ്!
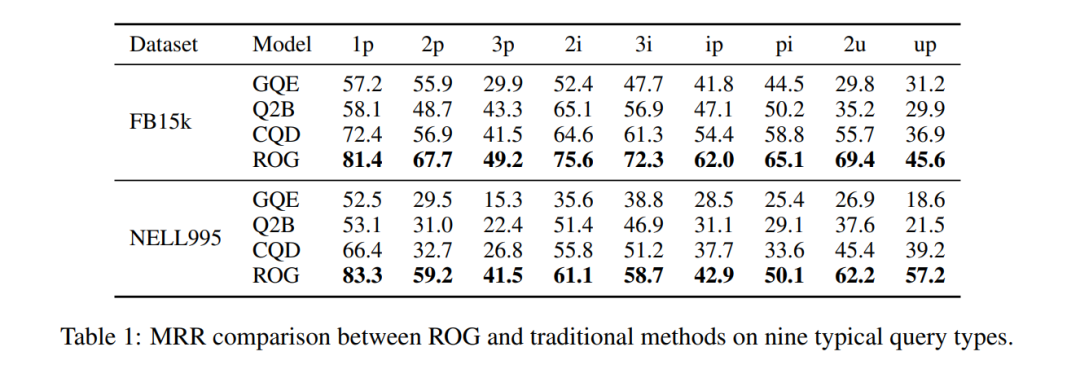 പട്ടിക 1: FB15k ഡാറ്റാ സെറ്റ് MRR താരതമ്യം. ROG സമഗ്രമായി മുന്നിലാണ്, സംയുക്ത അന്വേഷണങ്ങളിൽ ഏറ്റവും വലിയ മെച്ചപ്പെടുത്തൽ.
പട്ടിക 1: FB15k ഡാറ്റാ സെറ്റ് MRR താരതമ്യം. ROG സമഗ്രമായി മുന്നിലാണ്, സംയുക്ത അന്വേഷണങ്ങളിൽ ഏറ്റവും വലിയ മെച്ചപ്പെടുത്തൽ.
III. മാതൃക സ്ഥാപിക്കലും ഭാവി ദിശയും
രണ്ട് തലമുറ പ്രബന്ധങ്ങളും ഒരു മാതൃക സ്ഥിരീകരിക്കുന്നു:
"വീണ്ടെടുക്കൽ മെച്ചപ്പെടുത്തൽ + അന്വേഷണ വിഭജനം + LLM ന്യായവാദം" എന്നത് KG സങ്കീർണ്ണമായ ലോജിക്കൽ ന്യായവാദത്തിനുള്ള ഫലപ്രദമായ മാർഗ്ഗമാണ്.
പ്രധാന ട്രെൻഡുകൾ:
- അബ്സ്ട്രാക്ഷൻ നിർണായകമാണ് - സെമാന്റിക് ശബ്ദം ഒഴിവാക്കുക, ലോജിക്കൽ ഘടനയിൽ ശ്രദ്ധ കേന്ദ്രീകരിക്കുക.
- വിഘടന തന്ത്രം പരിധി നിർണ്ണയിക്കുന്നു - ചെയിൻ വിഭജനം എൻഡ്-ടു-എൻഡിനേക്കാൾ വിശ്വസനീയമാണ്.
- മോഡൽ ശേഷി തുടർച്ചയായി പുറത്തുവിടുന്നു - Llama2-7B മുതൽ ChatGLM വരെ, അടിസ്ഥാനപരമായ പുരോഗതി ഗണ്യമായ നേട്ടങ്ങൾ നൽകുന്നു.
ROG-യുടെ ഏജന്റ് മെക്കാനിസം വ്യാഖ്യാനം മെച്ചപ്പെടുത്തുമെങ്കിലും, പ്രധാന കണ്ടുപിടുത്തം സൈദ്ധാന്തിക മുന്നേറ്റത്തേക്കാൾ എഞ്ചിനീയറിംഗ് ഒപ്റ്റിമൈസേഷനിലാണ്. ഭാവി ദിശകൾ ഇവയായിരിക്കാം: ഡൈനാമിക് വിഘടന തന്ത്രങ്ങൾ (അന്വേഷണ സങ്കീർണ്ണതയ്ക്ക് അനുയോജ്യം), മൾട്ടിമോഡൽ KG ഫ്യൂഷൻ, വലിയ തോതിലുള്ള ഓപ്പൺ ഡൊമെയ്ൻ സ്ഥിരീകരണം.



