Ostatnio widziałem 2 dobre artykuły na temat LLM+KG do złożonego wnioskowania logicznego
Ostatnio widziałem 2 dobre artykuły na temat LLM+KG do złożonego wnioskowania logicznego
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Trudności wnioskowania w grafach wiedzy
Grafy wiedzy (KG) jako podstawowy nośnik wiedzy ustrukturyzowanej, borykają się z trzema głównymi problemami:
- Złożoność: eksplozja kombinatoryczna operacji wielo-skokowych, przecięć i sum, negacji itp.
- Niekompletność: rzeczywiste KG powszechnie zawierają szumy i braki
- Generalizacja: tradycyjne metody osadzania z trudem przenoszą się między zbiorami danych
Tradycyjne rozwiązania (takie jak Query2Box, BetaE) polegają na geometrycznej przestrzeni osadzania, modelując operacje logiczne jako operacje wektorowe/pudełkowe, ale podczas głębokiego wnioskowania dochodzi do poważnej utraty informacji. Jak sprawić, by model rozumiał zarówno strukturę logiczną, jak i elastycznie wnioskował? Rozwój dużych modeli językowych (LLM) oferuje nowe podejście.
 Rysunek 1: Rozkład łańcucha zapytań i proces wnioskowania LLM w LARK. Złożone zapytania wielooperacyjne są rozkładane na zapytania podrzędne jednooperacyjne, rozwiązywane krok po kroku.
Rysunek 1: Rozkład łańcucha zapytań i proces wnioskowania LLM w LARK. Złożone zapytania wielooperacyjne są rozkładane na zapytania podrzędne jednooperacyjne, rozwiązywane krok po kroku.
II. Rozwiązanie: Dziedzictwo i ewolucja dwóch generacji metod
LARK (2023) —— Praca pionierska
Rysunek 2: Strategie dekompozycji dla 14 typów zapytań. 3p jest rozkładane na 3 projekcje, 3i jest rozkładane na 3 projekcje + 1 przecięcie.
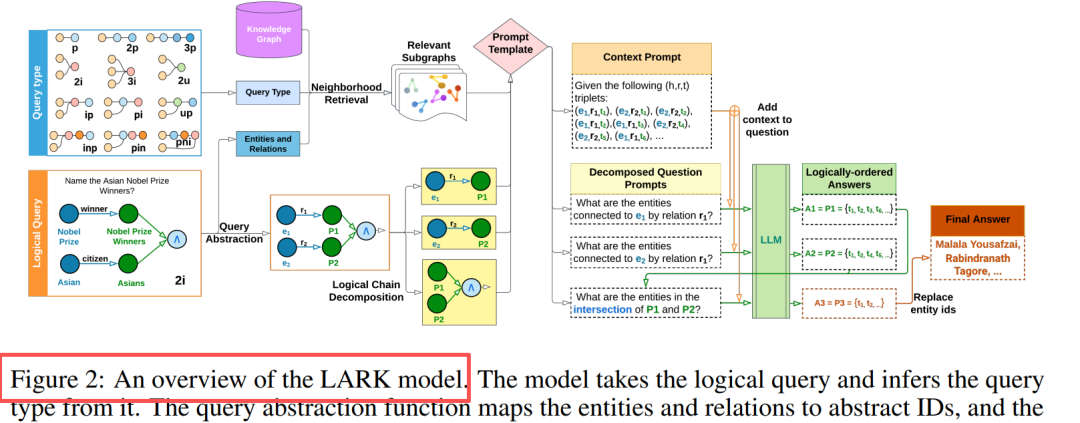 Kluczowa innowacja: abstrakcja zapytań + dekompozycja łańcucha logicznego
Kluczowa innowacja: abstrakcja zapytań + dekompozycja łańcucha logicznego
Komponenty Abstrakcja zapytań zastępowanie encji/relacji identyfikatorami, eliminacja halucynacji, poprawa generalizacji Wyszukiwanie sąsiedztwa przeszukiwanie w głąb k-hop (k=3), ekstrakcja powiązanych podgrafów Dekompozycja łańcuchowa zapytania wielooperacyjne → sekwencja zapytań podrzędnych jednooperacyjnych Wnioskowanie sekwencyjne buforowanie wyników pośrednich, logiczne uporządkowanie zastępowanie symboli zastępczych Kluczowy wniosek: LLM dobrze radzą sobie z prostymi zapytaniami, dekompozycja złożonych zapytań poprawia wydajność o 20%-33%.
ROG (2025) —— Wersja zaawansowana
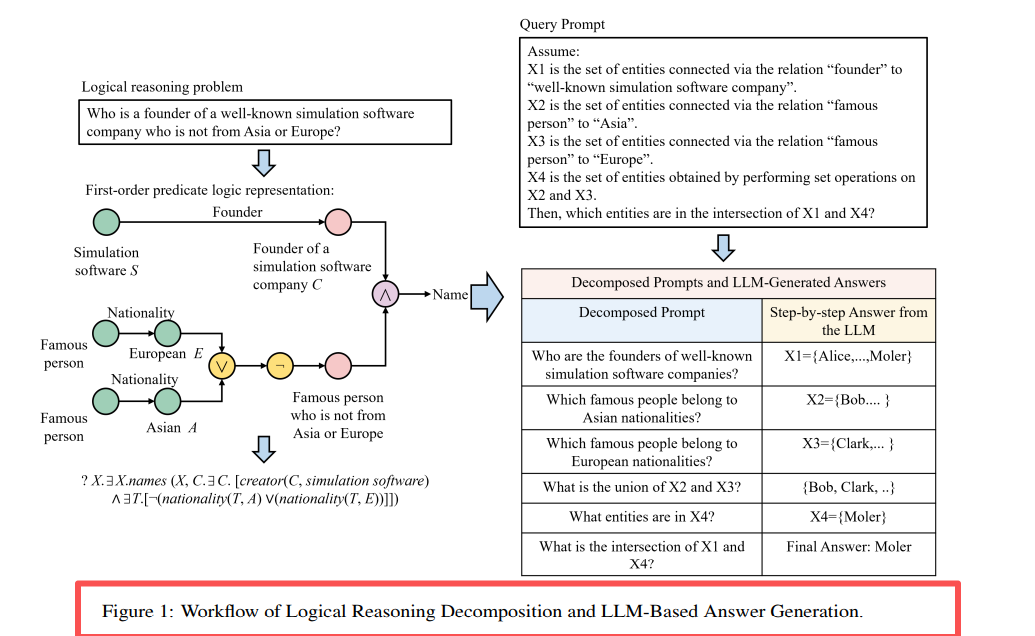 Dziedziczy ramy LARK, dodaje mechanizm konsensusu Agentów:
Dziedziczy ramy LARK, dodaje mechanizm konsensusu Agentów:
ROG = rdzeń LARK + współpraca wielu Agentów + wzmocnienie łańcucha myślowego
Wyjaśnienie ulepszeń
Projekt Agenta
Agent = baza wiedzy + LLM, decyzje oparte na konsensusie wielu Agentów
Wzmocnienie CoT
Bardziej wyraźne szablony podpowiedzi łańcucha myślowego
Dopasowanie do krajowych standardów
Oparte na ChatGLM+Neo4j, skierowane do pionowych dziedzin, takich jak energetyka
 Model przepływu danych ROG
Model przepływu danych ROG
Skok wydajności: na FB15k, zapytanie ip (projekcja po przecięciu) MRR wzrosło z 29.3→62.0, poprawa o 111%!
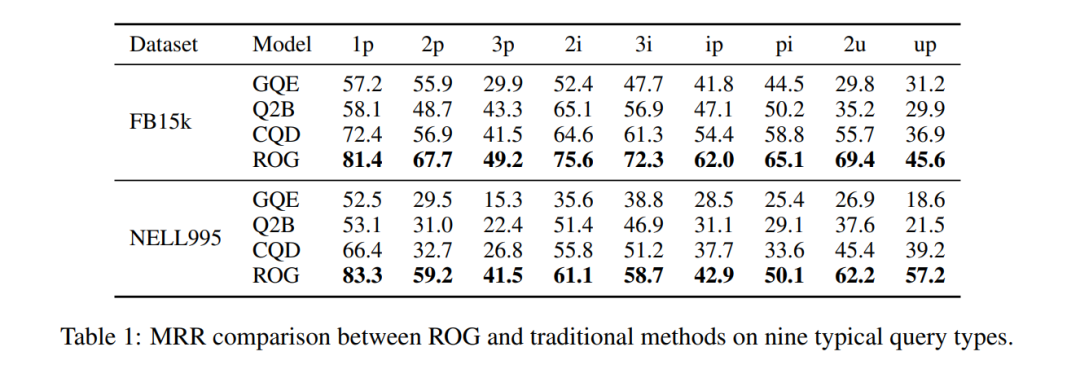 Tabela 1: Porównanie MRR zbioru danych FB15k. ROG jest wszechstronnie lepszy, a poprawa jest najbardziej znacząca w przypadku zapytań złożonych.
Tabela 1: Porównanie MRR zbioru danych FB15k. ROG jest wszechstronnie lepszy, a poprawa jest najbardziej znacząca w przypadku zapytań złożonych.
III. Ustanowienie paradygmatu i przyszłe kierunki
Dwie generacje artykułów wspólnie zweryfikowały paradygmat:
"Wyszukiwanie rozszerzone + dekompozycja zapytań + wnioskowanie LLM" to skuteczna ścieżka do złożonego wnioskowania logicznego KG.
Kluczowe trendy:
- Abstrakcja jest kluczowa —— oddzielenie szumu semantycznego, skupienie się na strukturze logicznej
- Strategia dekompozycji determinuje górną granicę —— dekompozycja łańcuchowa jest bardziej niezawodna niż end-to-end
- Zdolności modelu są stale uwalniane —— od Llama2-7B do ChatGLM, postęp bazy przynosi znaczące korzyści
Mechanizm Agentów ROG wzmacnia co prawda interpretowalność, ale kluczowa innowacja polega na optymalizacji inżynieryjnej, a nie przełomie teoretycznym. Przyszłe kierunki mogą obejmować: dynamiczne strategie dekompozycji (adaptacyjne do złożoności zapytań), fuzję multimodalnych KG oraz weryfikację w większej skali w otwartej domenie.



