Recentemente, vi 2 bons artigos sobre LLM+KG para raciocínio lógico complexo
Recentemente, vi 2 bons artigos sobre LLM+KG para raciocínio lógico complexo
-
LARK https://arxiv.org/abs/2305.01157 Raciocínio Lógico Complexo sobre Grafos de Conhecimento usando Grandes Modelos de Linguagem (Complex Logical Reasoning over Knowledge Graphs using Large Language Models)
-
ROG https://arxiv.org/abs/2512.19092 Um Método Baseado em Grande Modelo de Linguagem para Raciocínio Lógico Complexo sobre Grafos de Conhecimento (A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs)
I. O Dilema do Raciocínio em Grafos de Conhecimento
O grafo de conhecimento (KG), como o principal portador de conhecimento estruturado, enfrenta três grandes desafios:
- Complexidade: explosão combinatória de operações como raciocínio multi-hop, interseção e união, negação, etc.
- Incompletude: KGs do mundo real geralmente têm ruído e estão incompletos
- Generalização: métodos de incorporação tradicionais são difíceis de transferir entre conjuntos de dados
As soluções tradicionais (como Query2Box, BetaE) dependem de espaços de incorporação geométrica, modelando operações lógicas como operações de vetores/caixas, mas sofrem de séria perda de informação durante o raciocínio profundo. Como fazer com que o modelo entenda a estrutura lógica e possa raciocinar de forma flexível? A ascensão dos grandes modelos de linguagem (LLM) oferece uma nova abordagem.
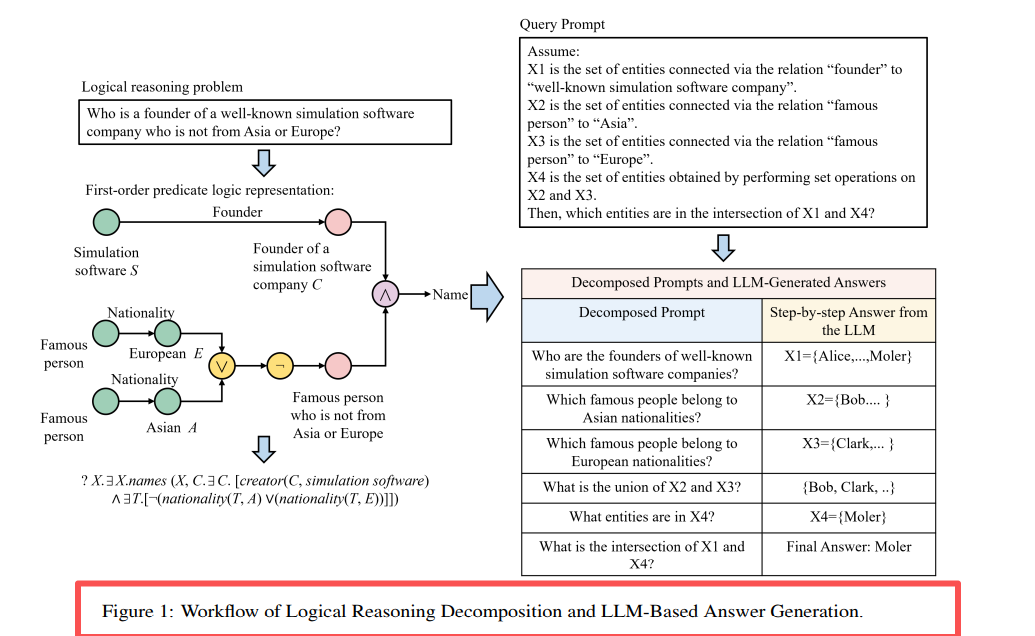
 Figura 1: Decomposição da cadeia de consulta e fluxo de raciocínio do LLM do LARK. Decompondo consultas complexas de múltiplas operações em subconsultas de operação única, resolvendo-as gradualmente.
Figura 1: Decomposição da cadeia de consulta e fluxo de raciocínio do LLM do LARK. Decompondo consultas complexas de múltiplas operações em subconsultas de operação única, resolvendo-as gradualmente.
II. Solução: Herança e Evolução de Métodos de Duas Gerações
LARK (2023) —— Trabalho Pioneiro
Figura 2: Estratégias de decomposição para 14 tipos de consulta. 3p é dividido em 3 projeções, 3i é dividido em 3 projeções + 1 interseção.
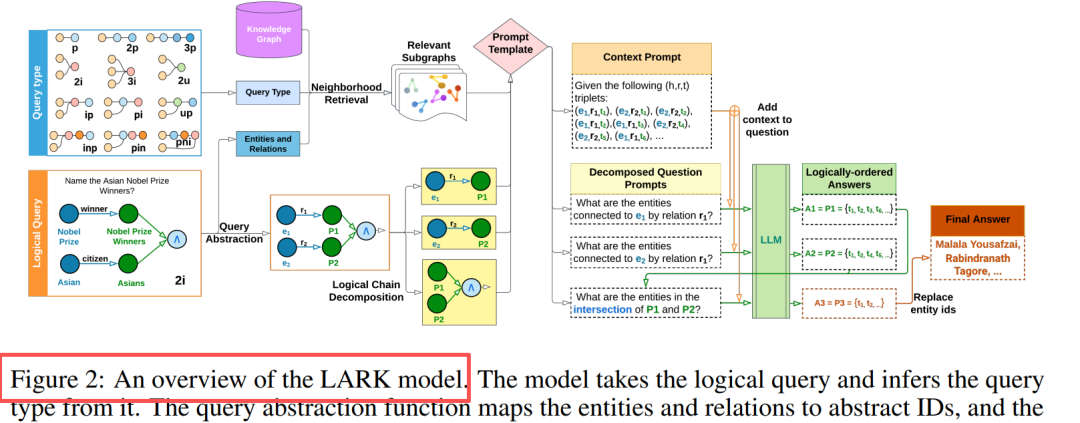 Inovação central: Abstração de consulta + Decomposição de cadeia lógica
Inovação central: Abstração de consulta + Decomposição de cadeia lógica
Design de componentes Abstração de consulta Substituição de entidades/relações por ID, eliminando alucinações, melhorando a generalização Recuperação de vizinhança Busca em profundidade k-hop (k=3), extraindo subgrafos relacionados Decomposição em cadeia Consulta de múltiplas operações → Sequência de subconsultas de operação única Raciocínio sequencial Armazenando em cache resultados intermediários, substituindo marcadores de posição logicamente ordenados Insight chave: LLMs são bons em consultas simples, o desempenho melhora em 20%-33% após a decomposição de consultas complexas.
ROG (2025) —— Versão Avançada
 Herdando a estrutura LARK, adicionando mecanismo de consenso do Agente:
Herdando a estrutura LARK, adicionando mecanismo de consenso do Agente:
ROG = Núcleo LARK + Colaboração Multi-Agente + Reforço da Cadeia de Pensamento
Explicação das melhorias
Design do Agente
Agente = Base de conhecimento + LLM, tomada de decisão por consenso multi-agente
Aprimoramento CoT
Modelos de prompt de cadeia de pensamento mais claros
Adaptação doméstica
Baseado em ChatGLM+Neo4j, voltado para áreas verticais como energia elétrica
 Modelo de fluxo de dados do ROG
Modelo de fluxo de dados do ROG
Aumento de desempenho: No FB15k, a consulta ip (projeção após interseção) MRR aumentou de 29,3→62,0, um aumento de 111%!
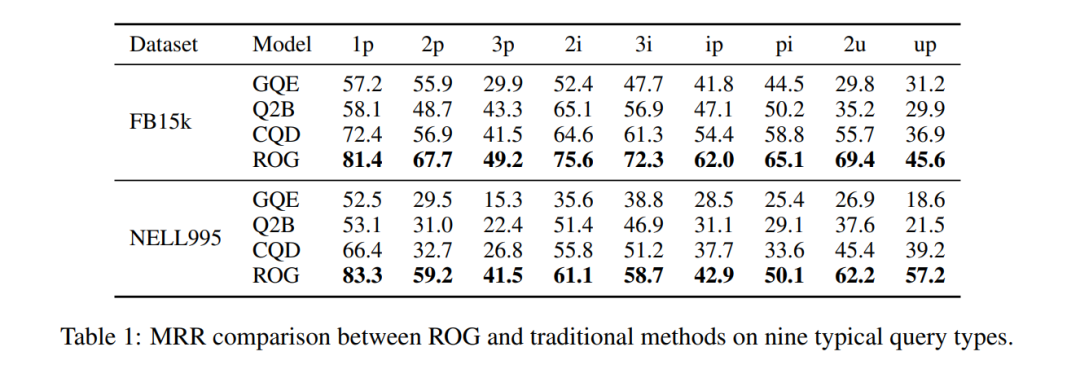 Tabela 1: Comparação MRR do conjunto de dados FB15k. ROG lidera em todos os aspectos, com a melhoria mais significativa nas consultas compostas.
Tabela 1: Comparação MRR do conjunto de dados FB15k. ROG lidera em todos os aspectos, com a melhoria mais significativa nas consultas compostas.
III. Estabelecimento de Paradigma e Direções Futuras
Os artigos de duas gerações validam conjuntamente um paradigma:
"Recuperação Aprimorada + Decomposição de Consulta + Raciocínio LLM" é um caminho eficaz para o raciocínio lógico complexo de KG.
Tendências chave:
- A abstração é crucial —— Removendo o ruído semântico, focando na estrutura lógica
- A estratégia de decomposição determina o limite superior —— A decomposição em cadeia é mais confiável do que ponta a ponta
- A capacidade do modelo continua a ser liberada —— Do Llama2-7B ao ChatGLM, o progresso da base traz ganhos significativos
Embora o mecanismo de Agente do ROG melhore a interpretabilidade, a principal inovação está na otimização de engenharia, e não em avanços teóricos. As direções futuras podem estar em: estratégias de decomposição dinâmica (adaptando-se à complexidade da consulta), fusão de KG multimodal e verificação de domínio aberto em maior escala.



