Недавно увидел 2 хорошие статьи об LLM+KG для сложных логических рассуждений
Недавно увидел 2 хорошие статьи об LLM+KG для сложных логических рассуждений
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Трудности логического вывода в графах знаний
Граф знаний (KG) как основной носитель структурированных знаний сталкивается с тремя основными проблемами:
- Сложность: комбинаторный взрыв многошаговых рассуждений, операций пересечения и объединения, отрицания и т. д.
- Неполнота: реальные KG обычно содержат шум и пропуски
- Обобщаемость: традиционные методы встраивания с трудом переносятся между наборами данных
Традиционные решения (такие как Query2Box, BetaE) полагаются на геометрическое пространство встраивания, моделируя логические операции как векторные/коробочные операции, но при глубоком рассуждении происходит значительная потеря информации. Как сделать так, чтобы модель понимала логическую структуру и могла гибко рассуждать? Появление больших языковых моделей (LLM) предлагает новый подход.
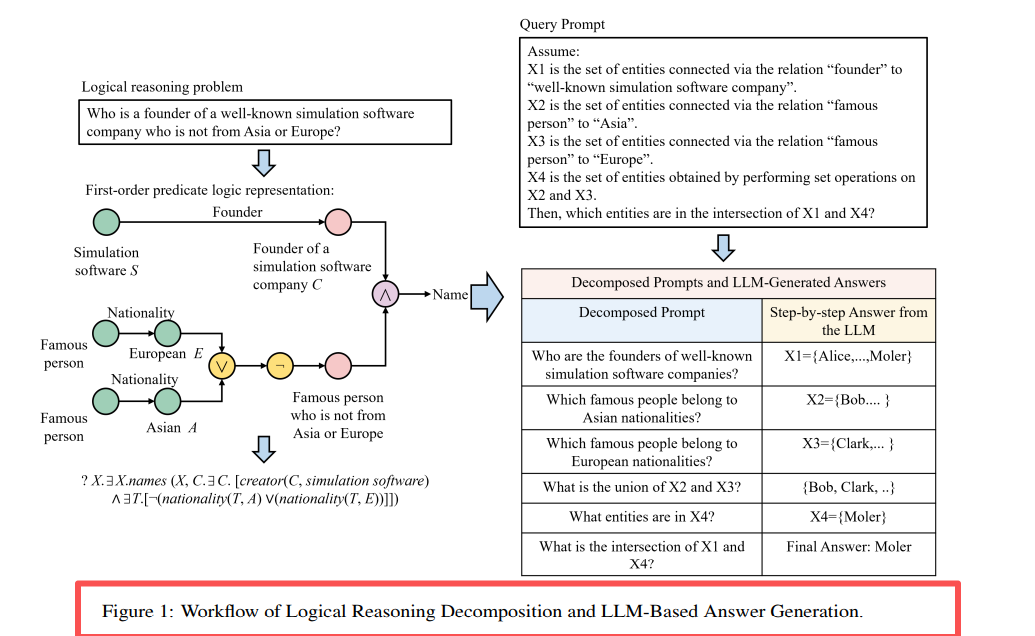
 Рисунок 1: Разложение цепочки запросов и процесс рассуждений LLM в LARK. Разложение сложного многооперационного запроса на однооперационные подзапросы с постепенным решением.
Рисунок 1: Разложение цепочки запросов и процесс рассуждений LLM в LARK. Разложение сложного многооперационного запроса на однооперационные подзапросы с постепенным решением.
II. Решение: Наследие и эволюция двух поколений методов
LARK (2023) —— Пионерская работа
Рисунок 2: Стратегии разложения для 14 типов запросов. 3p разбивается на 3 проекции, 3i разбивается на 3 проекции + 1 пересечение.
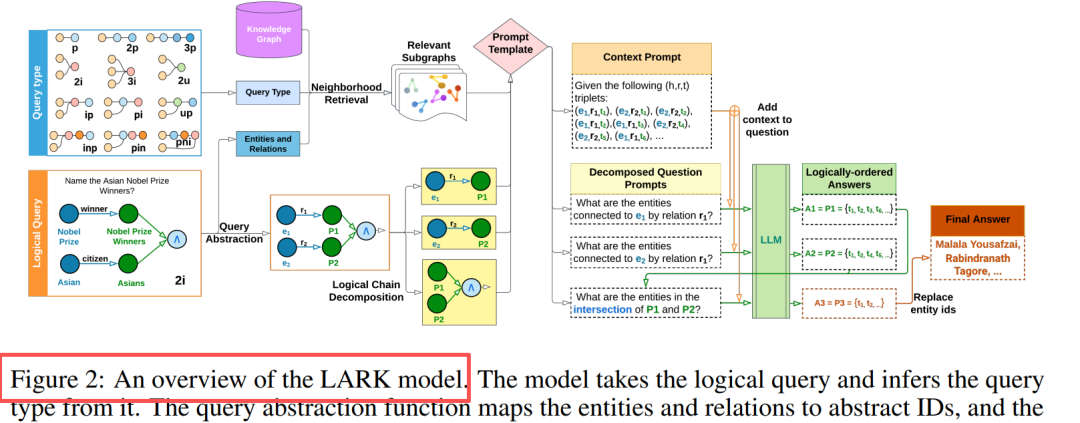 Основные инновации: Абстракция запросов + Разложение логической цепочки
Основные инновации: Абстракция запросов + Разложение логической цепочки
Компонентный дизайн Абстракция запросов Замена сущностей/отношений на ID, устранение галлюцинаций, повышение обобщаемости Поиск окрестностей k-hop поиск в глубину (k=3), извлечение связанных подграфов Цепочечное разложение Многооперационный запрос → Последовательность однооперационных подзапросов Последовательное рассуждение Кэширование промежуточных результатов, логически упорядоченная замена заполнителей Ключевое наблюдение: LLM хорошо справляются с простыми запросами, производительность повышается на 20-33% после разложения сложных запросов.
ROG (2025) —— Продвинутая версия
 Наследует фреймворк LARK, добавляет механизм консенсуса Agent:
Наследует фреймворк LARK, добавляет механизм консенсуса Agent:
ROG = Ядро LARK + Многоагентное сотрудничество + Усиление цепочки рассуждений
Пояснения к улучшениям
Дизайн Agent
Агент = База знаний + LLM, многоагентное принятие решений на основе консенсуса
Улучшение CoT
Более четкие шаблоны подсказок для цепочки рассуждений
Адаптация к отечественным разработкам
На базе ChatGLM+Neo4j, ориентирована на вертикальные области, такие как энергетика
 Модель потока данных ROG
Модель потока данных ROG
Скачок в производительности: На FB15k, MRR для ip запросов (проекция после пересечения) увеличился с 29.3→62.0, улучшение на 111%!
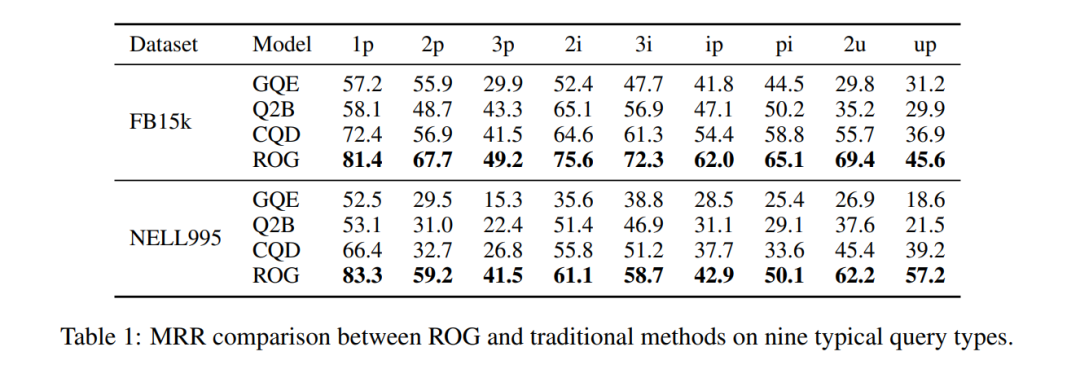 Таблица 1: Сравнение MRR набора данных FB15k. ROG лидирует по всем показателям, наиболее значительное улучшение для составных запросов.
Таблица 1: Сравнение MRR набора данных FB15k. ROG лидирует по всем показателям, наиболее значительное улучшение для составных запросов.
III. Установление парадигмы и будущие направления
Два поколения статей совместно подтверждают парадигму:
"Расширение поиска + Разложение запросов + LLM рассуждения" - эффективный путь для сложных логических рассуждений KG.
Ключевые тенденции:
- Абстракция имеет решающее значение —— Отделение семантического шума, сосредоточение на логической структуре
- Стратегия разложения определяет верхний предел —— Цепочечное разложение надежнее, чем сквозное
- Возможности модели продолжают раскрываться —— От Llama2-7B до ChatGLM, прогресс базовой модели приносит значительные выгоды
Механизм Agent в ROG усиливает интерпретируемость, но основная инновация заключается в инженерной оптимизации, а не в теоретическом прорыве. Будущие направления могут заключаться в: динамических стратегиях разложения (адаптация к сложности запросов), слиянии мультимодальных KG и проверке в более широком масштабе открытого домена.



