Недавно сам видео 2 добра рада о сложеном логичком закључивању помоћу LLM+KG
Недавно сам видео 2 добра рада о сложеном логичком закључивању помоћу LLM+KG
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Изазови закључивања у графовима знања
Графови знања (KG) као основни носачи структурираног знања, суочавају се са три главне болне тачке:
- Сложеност: Комбинаторна експлозија операција као што су закључивање у више корака, пресек, унија, негација итд.
- Непотпуност: Стварни KG-ови генерално имају шум и недостатке
- Генерализација: Традиционалне методе уграђивања тешко се преносе између скупова података
Традиционална решења (као што су Query2Box, BetaE) ослањају се на геометријски уграђени простор, моделирајући логичке операције као векторске/кутијасте операције, али губитак информација је озбиљан приликом дубоког закључивања. Како омогућити моделу да разуме логичку структуру и да флексибилно закључује? Успон великих језичких модела (LLM) пружа нове идеје.
 Слика 1: LARK-ова декомпозиција ланца упита и процес закључивања LLM-а. Декомпонује сложене упите са више операција у под-упите са једном операцијом и постепено их решава.
Слика 1: LARK-ова декомпозиција ланца упита и процес закључивања LLM-а. Декомпонује сложене упите са више операција у под-упите са једном операцијом и постепено их решава.
II. Решење: Наслеђе и еволуција две генерације метода
LARK (2023) —— Пионирски рад
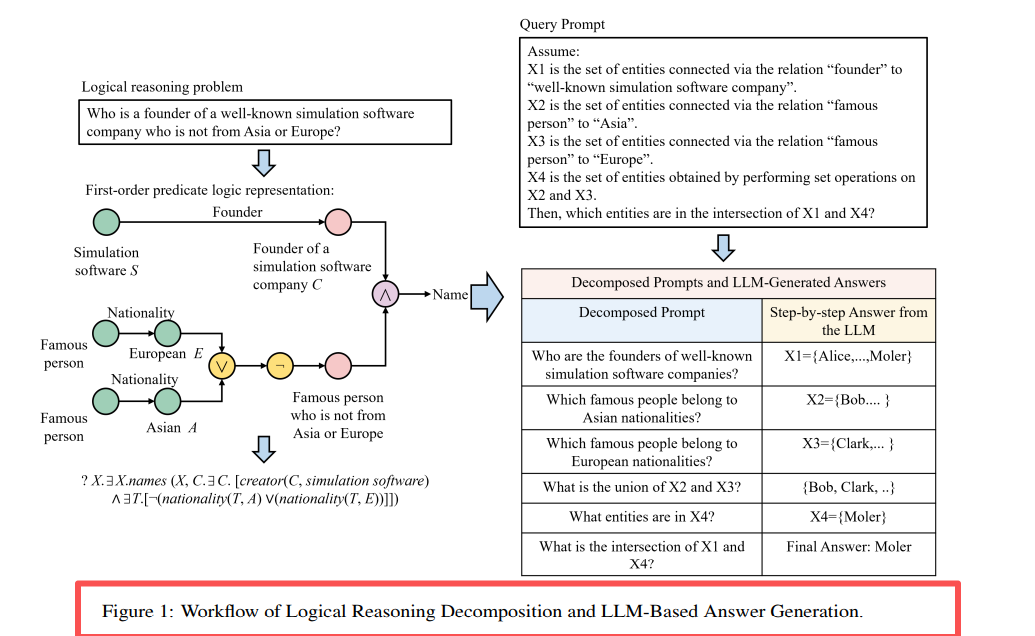
Слика 2: Стратегије декомпозиције за 14 типова упита. 3p се дели на 3 пројекције, 3i се дели на 3 пројекције + 1 пресек.
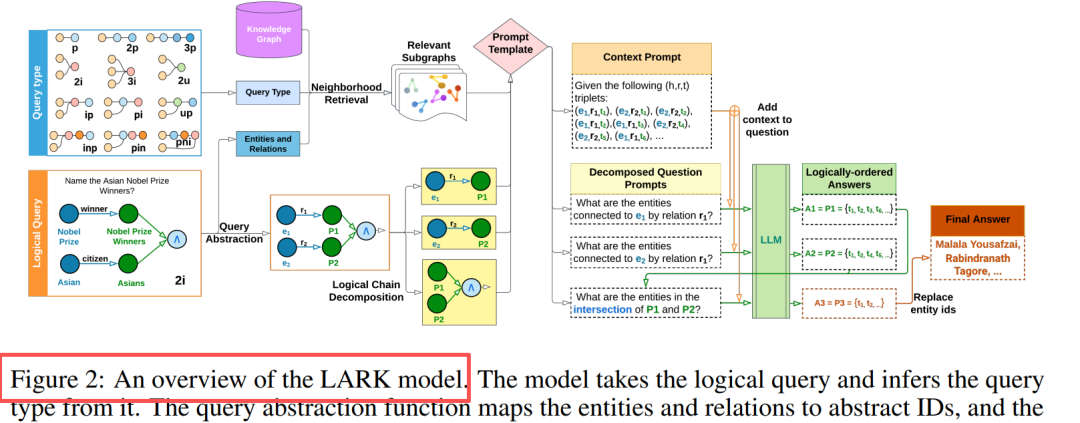 Основна иновација: Апстракција упита + Декомпозиција логичког ланца
Основна иновација: Апстракција упита + Декомпозиција логичког ланца
Дизајн компоненти Апстракција упита: Замена ентитета/односа са ID-овима, елиминисање халуцинација, побољшање генерализације Претрага суседства: k-hop претрага у дубину (k=3), издвајање релевантних подграфова Ланчана декомпозиција: Упити са више операција → Низ под-упита са једном операцијом Секвенцијално закључивање: Кеширање међурезултата, логички уређено Замена резервисаних места: Кључни увид: LLM је добар у једноставним упитима, перформансе се побољшавају за 20%-33% након декомпозиције сложених упита.
ROG (2025) —— Напредна верзија
 Наслеђује LARK оквир, додајући механизам консензуса Agent-а:
Наслеђује LARK оквир, додајући механизам консензуса Agent-а:
ROG = LARK језгро + Колаборација више Agent-а + Појачање ланца мисли
Објашњење побољшања
Дизајн Agent-а: Интелигентни агент = База знања + LLM, консензус одлучивање више Agent-а
CoT појачање: Јаснији шаблони за подстицање ланца мисли
Локална адаптација: Засновано на ChatGLM+Neo4j, оријентисано на вертикалне области као што је електроенергетика
 ROG модел протока података
ROG модел протока података
Скок перформанси: На FB15k, ip упит (пројекција након пресека) MRR са 29.3→62.0, повећање од 111%!
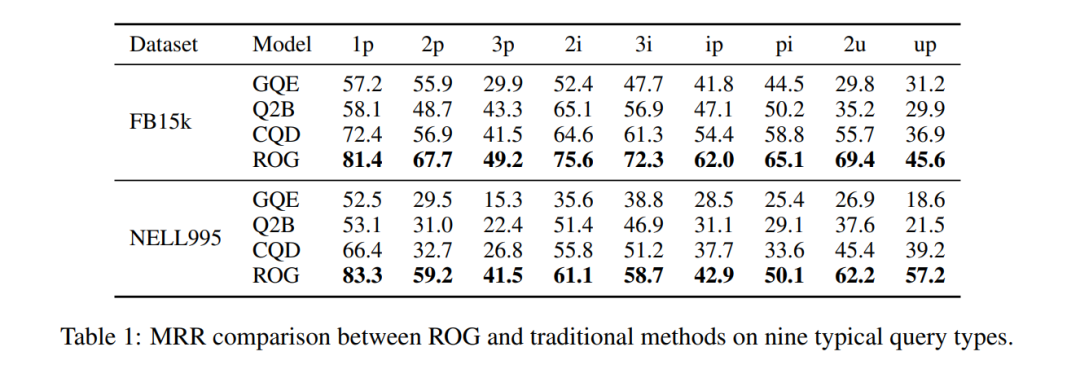 Табела 1: Поређење MRR-а на скупу података FB15k. ROG је свеобухватно водећи, а побољшање је најзначајније за сложене упите.
Табела 1: Поређење MRR-а на скупу података FB15k. ROG је свеобухватно водећи, а побољшање је најзначајније за сложене упите.
III. Успостављање парадигме и будући правци
Два рада заједно потврђују парадигму:
"Појачано претраживање + Декомпозиција упита + LLM закључивање" је ефикасан пут за сложено логичко закључивање KG-а.
Кључни трендови:
- Апстракција је кључна —— Уклањање семантичког шума, фокусирање на логичку структуру
- Стратегија декомпозиције одређује горњу границу —— Ланчана декомпозиција је поузданија од краја до краја
- Способност модела се континуирано ослобађа —— Од Llama2-7B до ChatGLM, напредак основног модела доноси значајне добитке
Иако ROG-ов механизам Agent-а побољшава објашњивост, основна иновација лежи у инжењерској оптимизацији, а не у теоријском продору. Будући правци могу бити: стратегије динамичке декомпозиције (адаптибилна сложеност упита), фузија мултимодалних KG-ова и већа верификација у отвореном домену.



