เร็วๆ นี้ ได้เห็นงานวิจัย LLM+KG ที่ดี 2 ฉบับเกี่ยวกับการให้เหตุผลเชิงตรรกะที่ซับซ้อน
เร็วๆ นี้ ได้เห็นงานวิจัย LLM+KG ที่ดี 2 ฉบับเกี่ยวกับการให้เหตุผลเชิงตรรกะที่ซับซ้อน
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
หนึ่ง ความยากลำบากของการให้เหตุผลเชิงกราฟความรู้
กราฟความรู้ (KG) ในฐานะที่เป็นพาหะหลักของความรู้ที่มีโครงสร้าง เผชิญกับปัญหาหลัก 3 ประการ:
- ความซับซ้อน: การให้เหตุผลแบบหลายขั้นตอน, เซตตัดและเซตรวม, การปฏิเสธ และการดำเนินการอื่นๆ ที่รวมกันแบบทวีคูณ
- ความไม่สมบูรณ์: KG ในโลกแห่งความเป็นจริงมักมีสัญญาณรบกวนและการขาดหายไป
- ความสามารถในการทั่วไป: วิธีการฝังแบบดั้งเดิมยากที่จะถ่ายโอนข้ามชุดข้อมูล
โซลูชันแบบดั้งเดิม (เช่น Query2Box, BetaE) อาศัยพื้นที่ฝังเชิงเรขาคณิต โดยสร้างแบบจำลองการดำเนินการทางตรรกะเป็นการดำเนินการเวกเตอร์/กล่อง แต่การสูญเสียข้อมูลอย่างรุนแรงในการให้เหตุผลเชิงลึก จะทำอย่างไรให้โมเดลเข้าใจทั้งโครงสร้างเชิงตรรกะและสามารถให้เหตุผลได้อย่างยืดหยุ่น? การเกิดขึ้นของแบบจำลองภาษาขนาดใหญ่ (LLM) ได้นำเสนอแนวคิดใหม่
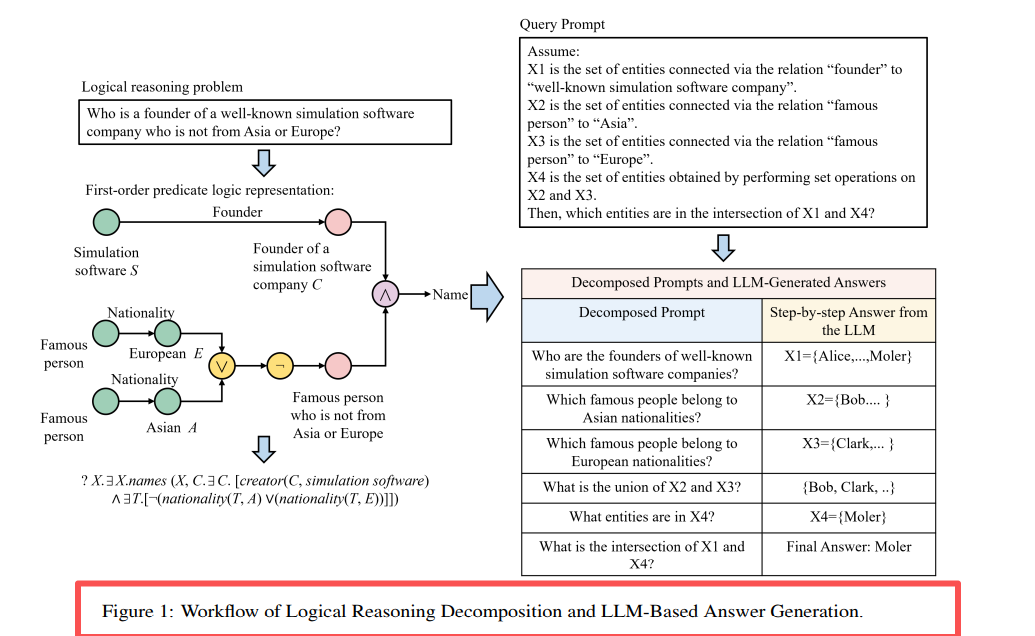
 รูปที่ 1: การสลายห่วงโซ่การสืบค้นและการประมวลผล LLM ของ LARK แยกการสืบค้นแบบหลายการดำเนินการที่ซับซ้อนออกเป็นการสืบค้นย่อยแบบการดำเนินการเดียว และแก้ไขปัญหาทีละขั้นตอน
รูปที่ 1: การสลายห่วงโซ่การสืบค้นและการประมวลผล LLM ของ LARK แยกการสืบค้นแบบหลายการดำเนินการที่ซับซ้อนออกเป็นการสืบค้นย่อยแบบการดำเนินการเดียว และแก้ไขปัญหาทีละขั้นตอน
สอง โซลูชัน: การสืบทอดและวิวัฒนาการของวิธีการสองรุ่น
LARK (2023) —— งานบุกเบิก
รูปที่ 2: กลยุทธ์การสลายประเภทการสืบค้น 14 ประเภท 3p ถูกแยกออกเป็น 3 การฉายภาพ, 3i ถูกแยกออกเป็น 3 การฉายภาพ + 1 เซตตัด
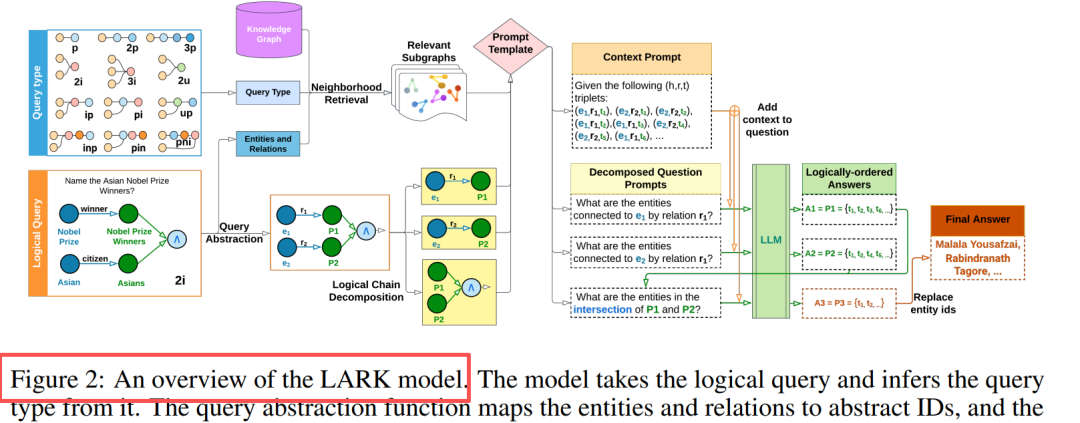 นวัตกรรมหลัก: การนามธรรมของการสืบค้น + การสลายห่วงโซ่เชิงตรรกะ
นวัตกรรมหลัก: การนามธรรมของการสืบค้น + การสลายห่วงโซ่เชิงตรรกะ
การออกแบบส่วนประกอบ การนามธรรมของการสืบค้น การแทนที่เอนทิตี/ความสัมพันธ์ด้วย ID, ขจัดภาพหลอน, ปรับปรุงความสามารถในการทั่วไป การดึงข้อมูลเพื่อนบ้าน การสำรวจแบบ Depth-First k-hop (k=3), ดึงกราฟย่อยที่เกี่ยวข้อง การสลายห่วงโซ่ การสืบค้นแบบหลายการดำเนินการ → ลำดับการสืบค้นย่อยแบบการดำเนินการเดียว การให้เหตุผลตามลำดับ แคชผลลัพธ์กลาง, การแทนที่ตัวยึดตำแหน่งตามลำดับเชิงตรรกะ ข้อมูลเชิงลึกที่สำคัญ: LLM เก่งในการสืบค้นอย่างง่าย ประสิทธิภาพเพิ่มขึ้น 20%-33% หลังจากแยกการสืบค้นที่ซับซ้อน
ROG (2025) —— เวอร์ชันขั้นสูง
 สืบทอดเฟรมเวิร์ก LARK เพิ่มกลไกฉันทามติของ Agent:
สืบทอดเฟรมเวิร์ก LARK เพิ่มกลไกฉันทามติของ Agent:
ROG = แกนหลักของ LARK + การทำงานร่วมกันของหลาย Agent + การเสริมสร้างห่วงโซ่ความคิด
คำอธิบายการปรับปรุง
การออกแบบ Agent
Agent = ฐานความรู้ + LLM, การตัดสินใจฉันทามติของหลาย Agent
การเสริมสร้าง CoT
เทมเพลตการแจ้งเตือนห่วงโซ่ความคิดที่ชัดเจนยิ่งขึ้น
การปรับให้เข้ากับผลิตภัณฑ์ในประเทศ
อิงตาม ChatGLM+Neo4j, มุ่งเน้นไปที่สาขาแนวตั้ง เช่น พลังงานไฟฟ้า
 แบบจำลองการไหลของข้อมูลของ ROG
แบบจำลองการไหลของข้อมูลของ ROG
การกระโดดของประสิทธิภาพ: บน FB15k, การสืบค้น ip (การฉายภาพหลังจากการตัด) MRR จาก 29.3→62.0, เพิ่มขึ้น 111%!
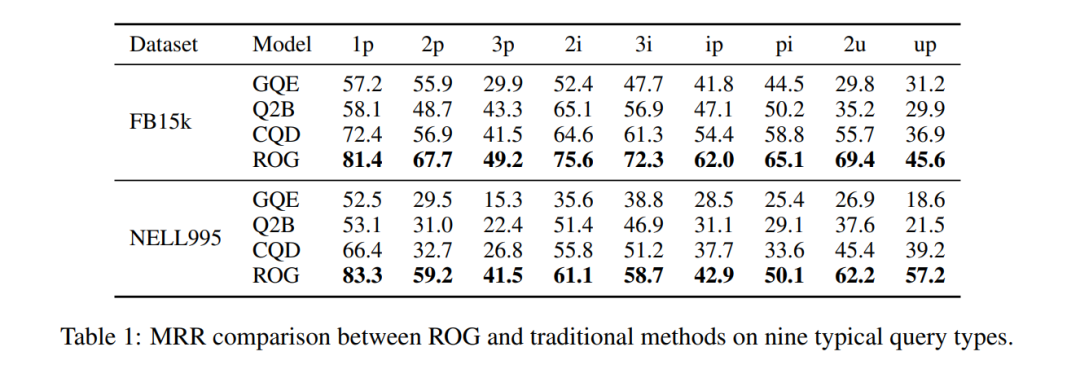 ตารางที่ 1: การเปรียบเทียบ MRR ของชุดข้อมูล FB15k ROG เป็นผู้นำอย่างครอบคลุม การปรับปรุงที่สำคัญที่สุดคือการสืบค้นแบบผสม
ตารางที่ 1: การเปรียบเทียบ MRR ของชุดข้อมูล FB15k ROG เป็นผู้นำอย่างครอบคลุม การปรับปรุงที่สำคัญที่สุดคือการสืบค้นแบบผสม
สาม การสร้างกระบวนทัศน์และทิศทางในอนาคต
งานวิจัยสองรุ่นได้ตรวจสอบกระบวนทัศน์ร่วมกัน:
"การเสริมสร้างการดึงข้อมูล + การสลายการสืบค้น + การให้เหตุผล LLM" เป็นเส้นทางที่มีประสิทธิภาพสำหรับการให้เหตุผลเชิงตรรกะที่ซับซ้อนของ KG
แนวโน้มที่สำคัญ:
- การนามธรรมเป็นสิ่งสำคัญยิ่ง —— ขจัดสัญญาณรบกวนทางความหมาย, มุ่งเน้นไปที่โครงสร้างเชิงตรรกะ
- กลยุทธ์การสลายตัวกำหนดขีดจำกัดบน —— การสลายห่วงโซ่น่าเชื่อถือมากกว่าแบบ End-to-End
- ความสามารถของโมเดลยังคงถูกปลดปล่อย —— จาก Llama2-7B ถึง ChatGLM, ความก้าวหน้าของฐานนำมาซึ่งผลประโยชน์ที่สำคัญ
แม้ว่ากลไก Agent ของ ROG จะช่วยเพิ่มความสามารถในการอธิบายได้ แต่สิ่งประดิษฐ์หลักอยู่ที่การเพิ่มประสิทธิภาพทางวิศวกรรมมากกว่าการพัฒนาทางทฤษฎี ทิศทางในอนาคตอาจอยู่ที่: กลยุทธ์การสลายตัวแบบไดนามิก (ปรับให้เข้ากับความซับซ้อนของการสืบค้น), การรวม KG แบบหลายรูปแบบ และการตรวจสอบโดเมนเปิดขนาดใหญ่ขึ้น



