Нещодавно побачив 2 чудові статті про LLM+KG для складних логічних висновків
Нещодавно побачив 2 чудові статті про LLM+KG для складних логічних висновків
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Складність міркувань на основі графа знань
Граф знань (KG) як основний носій структурованих знань стикається з трьома основними проблемами:
- Складність: комбінаторний вибух операцій, таких як багатострибкові міркування, перетин і об'єднання, заперечення тощо.
- Неповнота: реальні KG зазвичай мають шум і пропуски
- Узагальнення: традиційні методи вбудовування важко переносяться між наборами даних
Традиційні рішення (такі як Query2Box, BetaE) покладаються на геометричний простір вбудовування для моделювання логічних операцій як векторних/коробкових операцій, але вони зазнають серйозних втрат інформації під час глибоких міркувань. Як змусити модель розуміти як логічну структуру, так і гнучко міркувати? Підйом великих мовних моделей (LLM) запропонував нові ідеї.
 Рисунок 1: Розкладання ланцюжка запитів LARK і процес міркування LLM. Розкладання складних запитів з кількома операціями на підзапити з однією операцією та поступове їх вирішення.
Рисунок 1: Розкладання ланцюжка запитів LARK і процес міркування LLM. Розкладання складних запитів з кількома операціями на підзапити з однією операцією та поступове їх вирішення.
II. Рішення: Спадщина та еволюція двох поколінь методів
LARK (2023) —— новаторська робота
Рисунок 2: Стратегії розкладання для 14 типів запитів. 3p розкладається на 3 проекції, 3i розкладається на 3 проекції + 1 перетин.
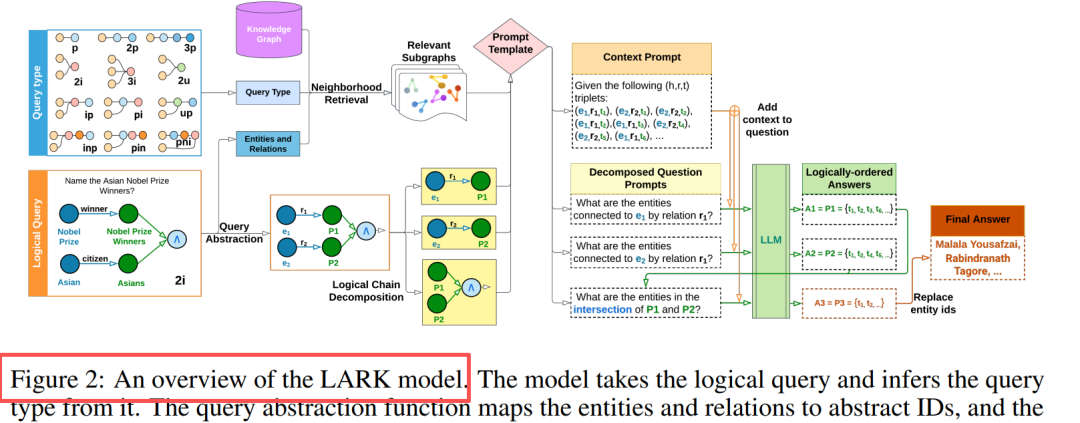 Основні інновації: абстракція запитів + розкладання логічного ланцюжка
Основні інновації: абстракція запитів + розкладання логічного ланцюжка
Компонентний дизайн Абстракція запитів Заміна сутностей/відношень на ID, усунення галюцинацій, покращення узагальнення Пошук сусідів k-hop пошук у глибину (k=3), вилучення відповідного підграфа Ланцюгове розкладання Запити з кількома операціями → послідовність підзапитів з однією операцією Послідовне міркування Кешування проміжних результатів, логічна впорядкована заміна заповнювачів Ключове розуміння: LLM чудово справляються з простими запитами, продуктивність покращується на 20%-33% після розкладання складних запитів.
ROG (2025) —— розширена версія
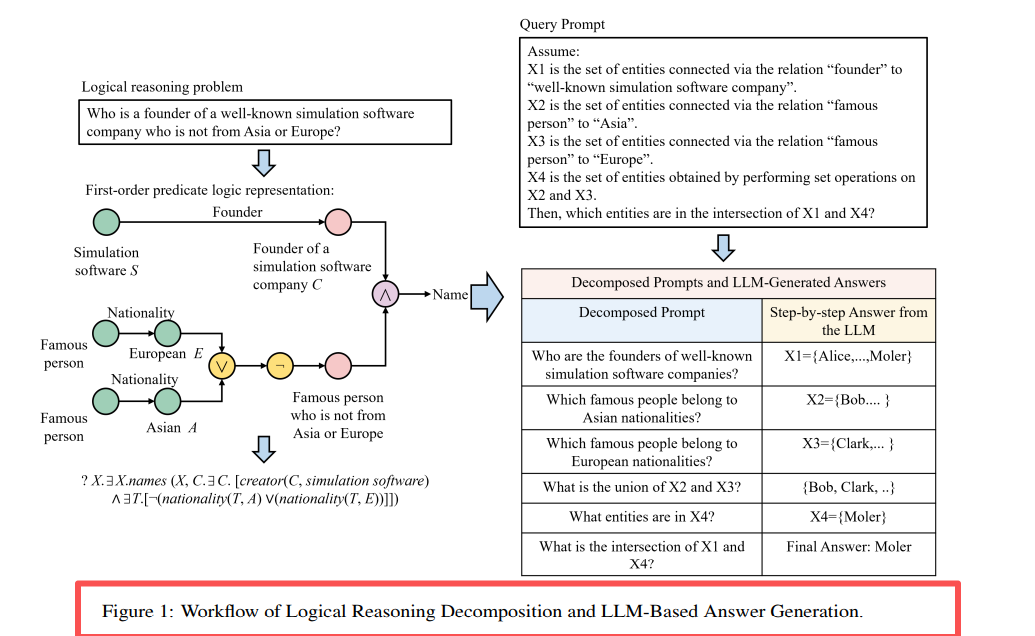 Успадковує фреймворк LARK, додає механізм консенсусу Agent:
Успадковує фреймворк LARK, додає механізм консенсусу Agent:
ROG = ядро LARK + співпраця кількох Agent + посилення ланцюжка думок
Пояснення покращень
Дизайн Agent
Інтелектуальний агент = база знань + LLM, консенсусне рішення кількох Agent
Посилення CoT
Більш чіткий шаблон підказок ланцюжка думок
Локальна адаптація
На основі ChatGLM+Neo4j, орієнтований на вертикальні області, такі як електроенергетика
 Модель потоку даних ROG
Модель потоку даних ROG
Стрибок продуктивності: на FB15k запит ip (проекція після перетину) MRR збільшився з 29,3→62,0, покращення на 111%!
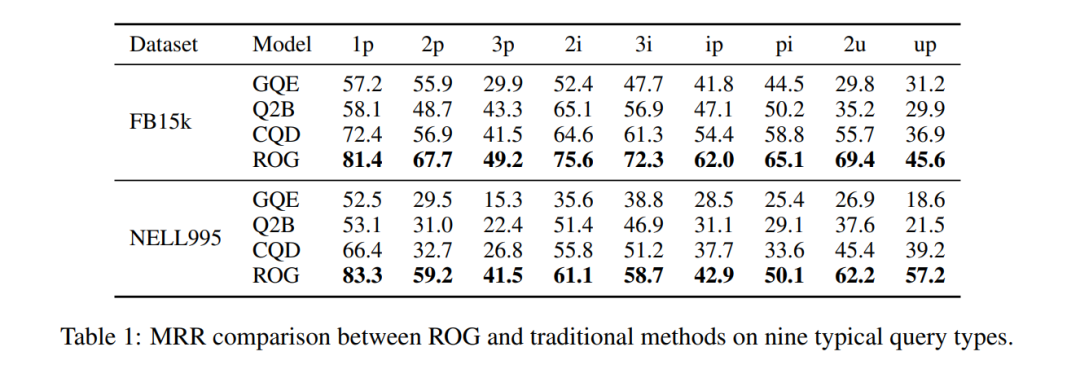 Таблиця 1: Порівняння MRR набору даних FB15k. ROG лідирує у всьому, покращення для складених запитів є найбільш значним.
Таблиця 1: Порівняння MRR набору даних FB15k. ROG лідирує у всьому, покращення для складених запитів є найбільш значним.
III. Встановлення парадигми та майбутні напрямки
Дві статті разом підтверджують парадигму:
"Посилення пошуку + розкладання запитів + міркування LLM" є ефективним шляхом для складних логічних міркувань KG.
Ключові тенденції:
- Абстракція має вирішальне значення —— відокремлення семантичного шуму, зосередження на логічній структурі
- Стратегія розкладання визначає верхню межу —— ланцюгове розкладання є більш надійним, ніж наскрізне
- Можливості моделі продовжують розширюватися —— від Llama2-7B до ChatGLM, прогрес базової моделі приносить значні переваги
Механізм Agent ROG покращує інтерпретованість, але основна інновація полягає в інженерній оптимізації, а не в теоретичному прориві. Майбутні напрямки можуть полягати в: стратегіях динамічного розкладання (адаптивна складність запитів), злитті мультимодальних KG і великомасштабній перевірці у відкритому домені.



