Искате ли да разберете интелигентния агент Codex? Не пропускайте този задълбочен анализ!
Искате ли да разберете интелигентния агент Codex? Не пропускайте този задълбочен анализ!
OpenAI току-що направи нещо "необичайно".
Обикновено OpenAI пуска по-силни модели (като o1), но този път те публикуваха задълбочен технически блог «Unrolling the Codex agent loop», като не само предоставиха с отворен код основната логика на Codex CLI, но и стъпка по стъпка разглобиха как точно работи един зрял кодов интелигентен агент (Coding Agent).

В настоящия момент, когато Claude Code и Cursor лудо трупат фенове, тази статия на OpenAI не е просто показване на мускули, а по-скоро "ръководство за избягване на грешки за архитекти на агенти". Независимо дали искате да използвате добре AI инструменти за програмиране, или искате сами да разработите агент, тази статия си заслужава да бъде прочетена дума по дума.
Целият текст е над 8300 думи, четенето ще отнеме около 20 минути.
Първо, какво е Codex CLI?
Codex CLI е инструмент за кодиране на Agent с отворен код, произведен от OpenAI, който може да работи на локален компютър или да бъде инсталиран в редактор на код. Поддържа VS Code, Cursor, Windsurf и др.
Адрес с отворен код: https://github.com/openai/codex
А Agent Loop (цикъл на агента), който ще бъде представен този път, е основната логика на Codex CLI: той е отговорен за координирането на потребителя, модела и извикванията на модела, за да се изпълняват взаимодействия между ценни инструменти.
Agent Loop (цикъл на интелигентния агент)
Моделите са само компоненти, Agent (интелигентният агент) може да съставлява продукт.
В основата на всеки AI Agent е така нареченият "цикъл на интелигентния агент (Agent Loop)". Схемата на цикъла на интелигентния агент е показана по-долу:
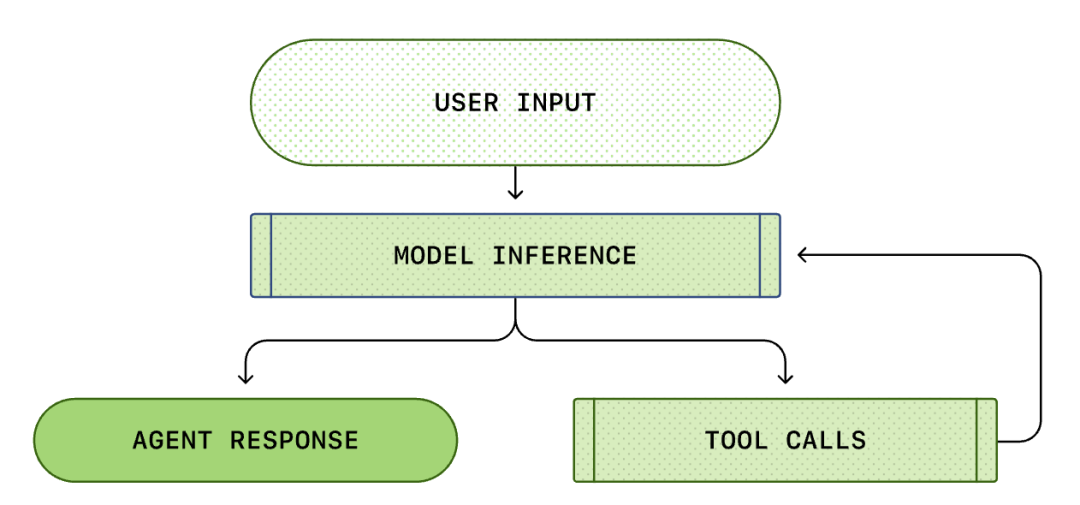
Обикновено смятаме, че AI програмирането е: "Аз питам, той отговаря". Но в Codex CLI това е сложен безкраен цикличен процес...
Един стандартен Agent Loop включва следните стъпки:
- Потребителски инструкции: Набор от текстови инструкции, въведени от потребителя (например "преструктурирайте тази функция").
- Извод на модела: Моделът решава дали да отговори директно, или да извика инструмент (Tool Call).
- Извикване на инструмент: Ако моделът реши да извика list files или run shell, CLI ще изпълни тези команди локално.
- Наблюдение (Observation): Резултатите от изпълнението на инструмента (код, грешки, списък с файлове) се улавят.
- Цикъл: Тези резултати се добавят към историята на разговорите и отново се подават на модела. След като види резултатите, моделът решава следващата стъпка.
- Прекратяване: Докато моделът не прецени, че задачата е завършена, и не изведе окончателен отговор.
Целият процес от "потребителско въвеждане" до "отговор на интелигентния агент" се нарича рунд на разговор (в Codex се нарича нишка).
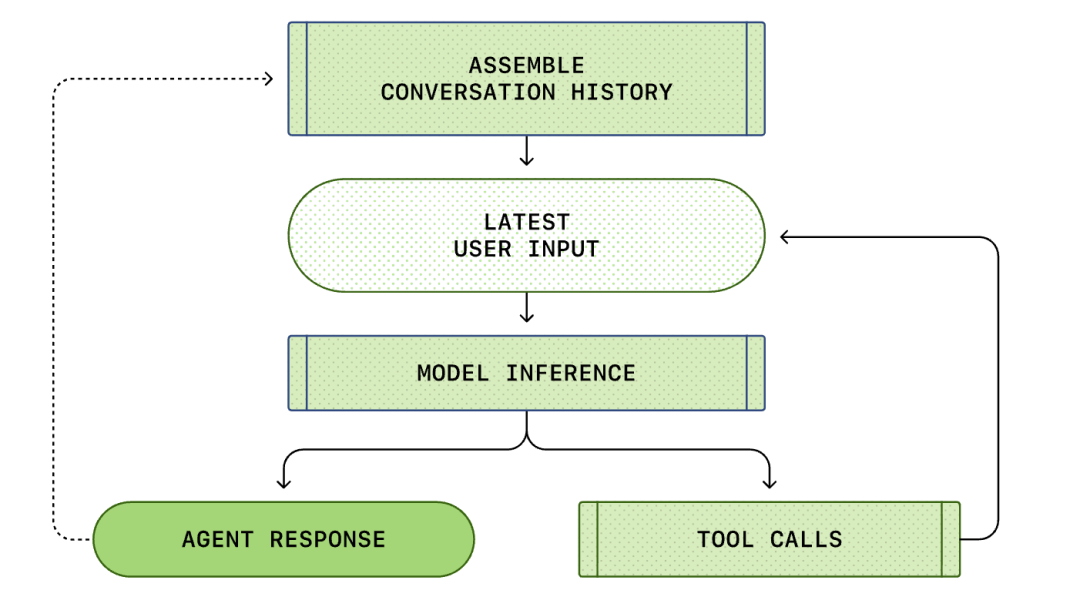
С напредването на разговора се увеличава и дължината на подканата (Prompt), използвана за разсъждения на модела. Тази дължина е важна, защото всеки модел има контекстен прозорец, който представлява максималния брой токени, които моделът може да използва в едно извикване за разсъждения.
Извод на модела
Codex CLI изпраща HTTP заявка към Responses API за извършване на извод на модела. Codex използва Responses API, за да управлява цикъла на агента.
Какво е Responses API?
Responses API е ново поколение интерфейс за разработка на интелигентни агенти, пуснат от OpenAI през март 2025 г., който има за цел да обедини възможностите за диалог, извикване на инструменти и мултимодално обработване, за да предостави на разработчиците по-гъвкаво и мощно изживяване при изграждане на AI приложения.
Използваният от Codex CLI краен пункт на Responses API е конфигурируем и може да се използва с всеки краен пункт, който реализира Responses API.
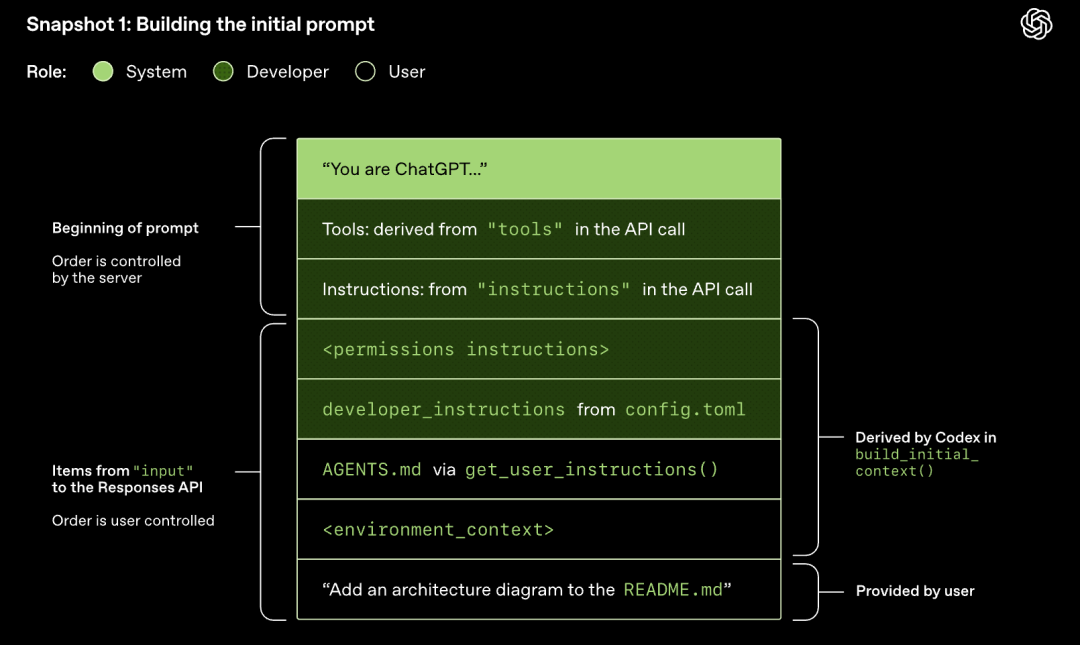
Моделът извършва семплиране (генериране на отговор)
HTTP заявката, инициирана към Responses API, ще стартира първия "рунд" в разговора на Codex. Сървърът ще върне отговор поточно чрез Server-Sent Events (SSE).
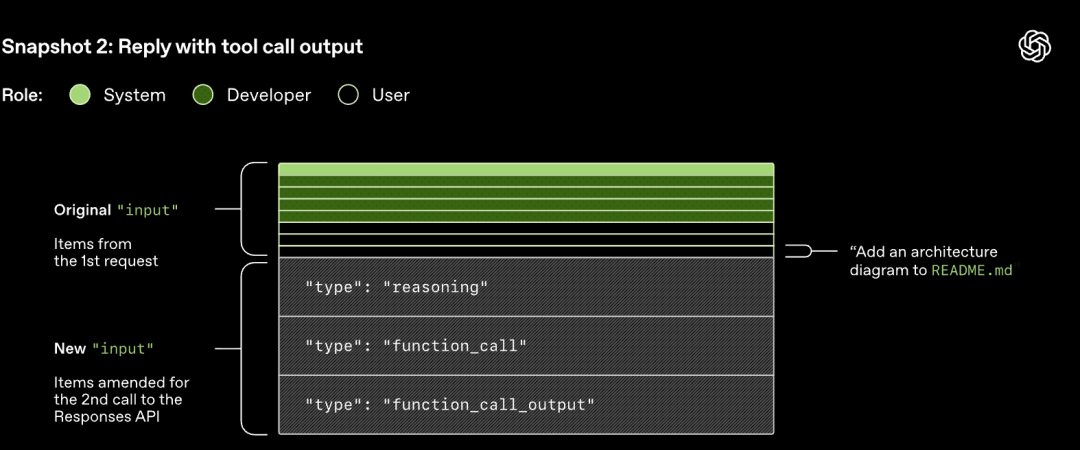
Обърнете внимание, че подканата от предишния рунд е точен префикс на новата подкана. Този дизайн може значително да подобри ефективността на последващите заявки - може да се използва механизъм за кеширане на подкани.

Въздействието от непрекъснатото удължаване на подканата с увеличаването на рундовете
1. По отношение на производителността
- Увеличаване на разходите за семплиране на модела: Непрекъснатото удължаване на подканата ще увеличи разходите за семплиране на модела, тъй като процесът на семплиране трябва да обработва повече данни, което води до увеличаване на изчислителната работа.
- Намаляване на ползите от кеширането: С непрекъснатото удължаване на подканата с увеличаването на рундовете, трудността при точно съвпадение на префиксите се увеличава и вероятността за попадение в кеша намалява.
2. По отношение на управлението на контекстния прозорец
- Контекстният прозорец лесно се изчерпва: Непрекъснатото удължаване на подканата ще доведе до бързо увеличаване на броя на маркерите в разговора и след като се надхвърли прагът на контекстния прозорец, това може да доведе до изчерпване на контекстния прозорец.
- Увеличаване на необходимостта от операции за компресиране: За да се избегне изчерпването на контекстния прозорец, е необходимо да се компресира разговорът, когато броят на маркерите надвиши прага.
3. По отношение на риска от пропуски в кеша
- Различни операции лесно предизвикват пропуски в кеша: Ако удължаването на подканата включва промени в наличните инструменти на модела, целевия модел, конфигурацията на пясъчната кутия и други операции, това допълнително ще увеличи риска от пропуски в кеша.
- MCP инструментите увеличават сложността: MCP сървърът може динамично да променя списъка с предоставени инструменти, а отговорът на съответните известия в дълги разговори ще доведе до пропуски в кеша.
Справка: «Unrolling the Codex agent loop» Източник: OpenAI



