Vil du forstå Codex-agenten? Du må ikke gå glip af denne dybdegående analyse!
Vil du forstå Codex-agenten? Du må ikke gå glip af denne dybdegående analyse!
OpenAI har lige gjort noget "usædvanligt".
Normalt ville OpenAI frigive stærkere modeller (som o1), men denne gang udgav de et dybdegående teknisk blogindlæg, 《Unrolling the Codex agent loop》, som ikke kun open-sourcede kernelogikken i Codex CLI, men også trin for trin dekonstruerede, hvordan en moden kodeagent (Coding Agent) rent faktisk kører.

I en tid, hvor Claude Code og Cursor vinder fans i et rasende tempo, er denne artikel fra OpenAI ikke kun en muskelfleksion, men også en "guide til at undgå faldgruber for Agent-arkitekter". Uanset om du vil bruge AI-programmeringsværktøjer godt, eller du vil udvikle din egen Agent, er denne artikel værd at studere ord for ord.
Hele teksten er 8300+ ord lang, og det tager cirka 20 minutter at læse.
Først, hvad er Codex CLI?
Codex CLI er et open source-kodningsagentværktøj produceret af OpenAI, der kan køre på en lokal computer eller installeres i en kodeeditor. Understøtter VS Code, Cursor, Windsurf osv.
Open source-adresse: https://github.com/openai/codex
Og Agent Loop (agent-loop), der skal introduceres i dag, er kernelogikken i Codex CLI: ansvarlig for at koordinere brugeren, modellen og modelkald for at udføre interaktioner mellem værdifulde værktøjer.
Agent Loop (intelligent agent-loop)
Modeller er kun komponenter, agenter (intelligente agenter) kan udgøre produkter.
Kernen i hver AI-agent er den såkaldte "agent-loop (Agent Loop)". Diagrammet over agent-loop er som følger:
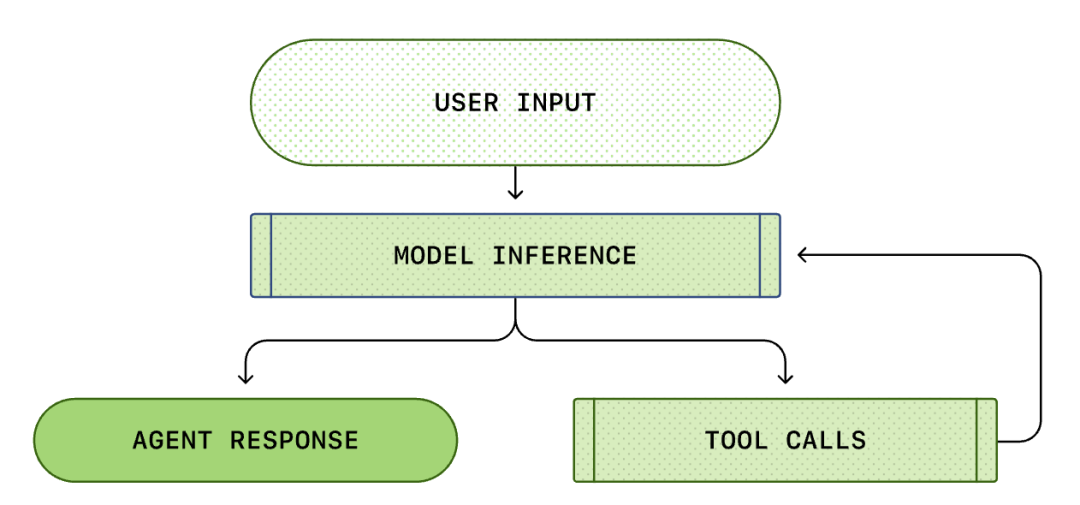
Vi tror normalt, at AI-programmering er: "Jeg spørger, den svarer". Men inde i Codex CLI er dette en kompleks uendelig loop-proces...
En standard Agent Loop indeholder følgende trin:
- Brugerinstruktioner: Et sæt tekstinstruktioner indtastet af brugeren (f.eks. "refaktor denne funktion").
- Modelinferens: Modellen bestemmer, om den skal svare direkte eller kalde et værktøj (Tool Call).
- Værktøjskald: Hvis modellen beslutter at kalde list files eller run shell, vil CLI'en udføre disse kommandoer lokalt.
- Observation: Resultaterne af værktøjets udførelse (kode, fejl, filliste) er fanget.
- Loop: Disse resultater tilføjes til dialoghistorikken og føres tilbage til modellen. Efter at modellen har set resultaterne, bestemmer den det næste trin.
- Afslutning: Indtil modellen mener, at opgaven er fuldført, udsender den det endelige svar.
Hele processen fra "brugerinput" til "intelligent agent-respons" kaldes en runde af dialogen (i Codex kaldet en tråd).
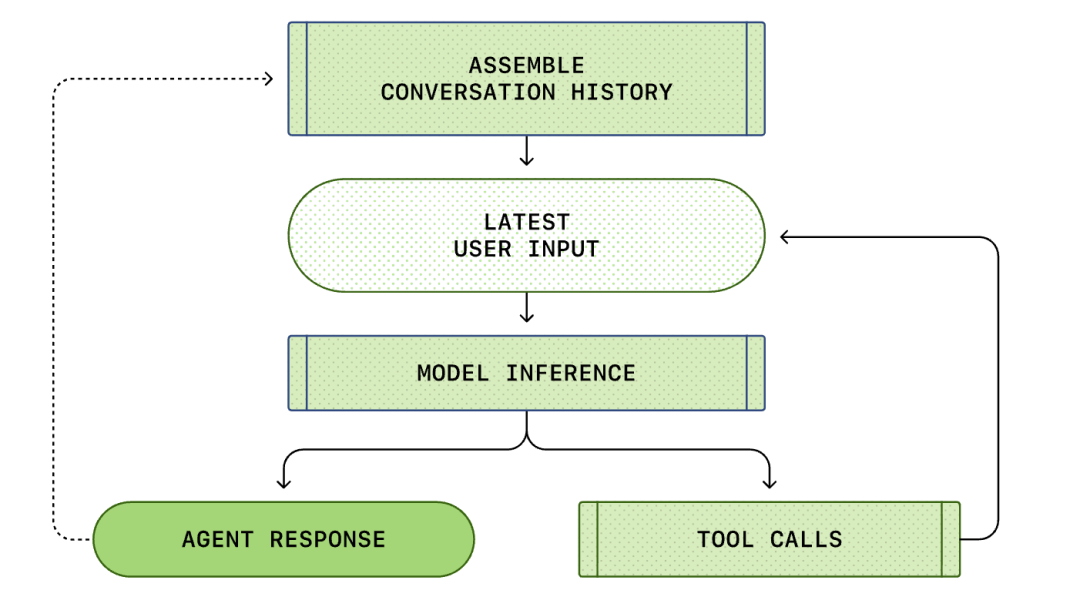
Efterhånden som dialogen skrider frem, vil længden af prompten (Prompt), der bruges til at ræsonnere modellen, også stige. Denne længde er vigtig, fordi hver model har et kontekstvindue, der repræsenterer det maksimale antal tokens, som modellen kan bruge i et enkelt inferenskald.
Modelinferens
Codex CLI sender HTTP-anmodninger til Responses API for modelinferens. Codex bruger Responses API til at drive agent-loop.
Hvad er Responses API?
Responses API er en ny generation af intelligent agent-udviklingsgrænseflade lanceret af OpenAI i marts 2025, der har til formål at forene dialog, værktøjskald og multimodale behandlingsmuligheder for at give udviklere en mere fleksibel og kraftfuld AI-applikationskonstruktionsoplevelse.
Codex CLI's Responses API-endepunkt kan konfigureres og kan bruges med ethvert endepunkt, der implementerer Responses API.
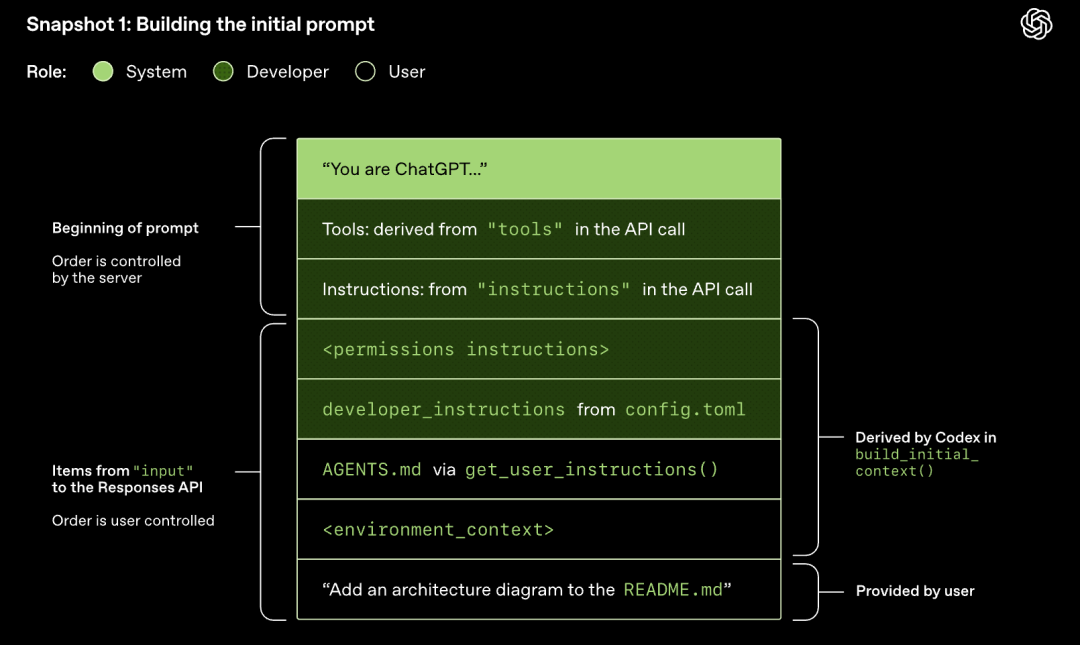
Modellen sampler (genererer svar)
HTTP-anmodningen, der sendes til Responses API, starter den første "runde" i Codex-dialogen. Serveren returnerer svaret streamet via Server-Sent Events (SSE).
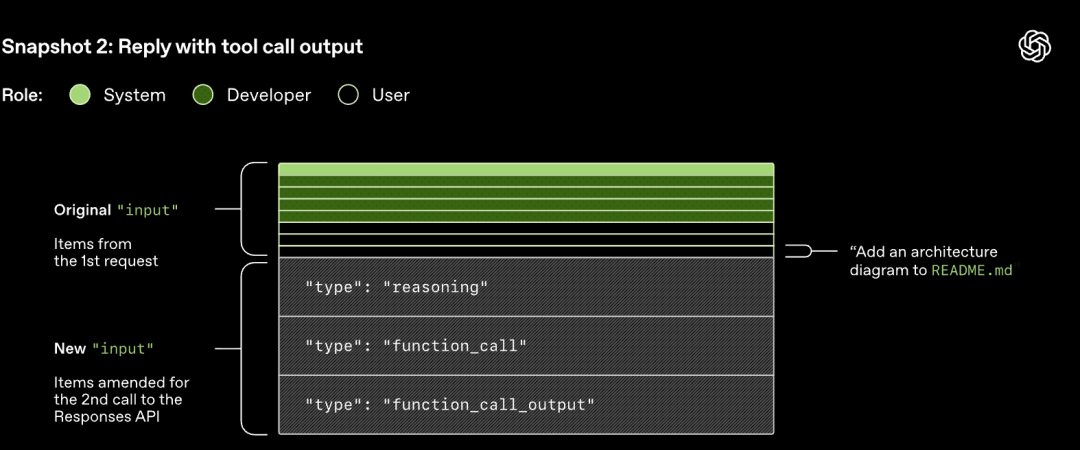
Bemærk, at den forrige rundes prompt er et præcist præfiks for den nye prompt. Dette design kan forbedre effektiviteten af efterfølgende anmodninger betydeligt - prompt-cachemekanismen kan bruges.

Virkningen af, at prompten fortsætter med at forlænges, efterhånden som runderne stiger
1. Med hensyn til ydeevne
- Stigende omkostninger ved model sampling: Den kontinuerlige forlængelse af prompten vil øge omkostningerne ved model sampling, fordi samplingprocessen skal behandle flere data, hvilket resulterer i en stigning i beregningsmængden.
- Reduceret cacheeffektivitet: Efterhånden som prompten fortsætter med at forlænges med stigende runder, øges vanskeligheden ved præcis præfiksmatchning, og sandsynligheden for cache-hit reduceres.
2. Med hensyn til kontekstvinduestyring
- Kontekstvinduet er let at udtømme: Den kontinuerlige forlængelse af prompten vil få antallet af tokens i dialogen til at stige hurtigt, og når først tærsklen for kontekstvinduet er overskredet, kan det føre til, at kontekstvinduet er udtømt.
- Stigende behov for komprimeringsoperationer: For at undgå udtømning af kontekstvinduet er det nødvendigt at komprimere dialogen, når antallet af tokens overstiger tærsklen.
3. Med hensyn til risikoen for cache-miss
- Flere operationer er lette at udløse cache-miss: Hvis ændringer i tilgængelige værktøjer, målmodel, sandkassekonfiguration osv. er involveret på grund af forlængelsen af prompten, vil det yderligere øge risikoen for cache-miss.
- MCP-værktøjer øger kompleksiteten: MCP-serveren kan dynamisk ændre listen over leverede værktøjer, og respons på relaterede meddelelser i lange samtaler kan føre til cache-miss.
Referenceoplysninger: 《Unrolling the Codex agent loop》Kilde: OpenAI



