Codex-Agent verstehen? Diese tiefgehende Analyse ist ein Muss!
Codex-Agent verstehen? Diese tiefgehende Analyse ist ein Muss!
OpenAI hat gerade etwas "Ungewöhnliches" getan.
Normalerweise veröffentlicht OpenAI stärkere Modelle (wie o1), aber dieses Mal haben sie einen tiefgehenden technischen Blogbeitrag 《Unrolling the Codex agent loop》 veröffentlicht, in dem sie nicht nur die Kernlogik des Codex CLI Open Source gemacht haben, sondern auch Schritt für Schritt aufgeschlüsselt haben, wie ein ausgereifter Code-Agent (Coding Agent) tatsächlich funktioniert.

In der aktuellen Zeit, in der Claude Code und Cursor verrückt viele Fans gewinnen, ist dieser Artikel von OpenAI nicht nur eine Zurschaustellung von Muskeln, sondern auch ein "Leitfaden zur Vermeidung von Fallstricken für Agent-Architekten". Egal, ob Sie KI-Programmiertools gut nutzen oder selbst einen Agenten entwickeln möchten, dieser Artikel ist es wert, Wort für Wort studiert zu werden.
Der vollständige Text umfasst mehr als 8300 Wörter und die Lektüre dauert etwa 20 Minuten.
Zuerst, was ist Codex CLI?
Codex CLI ist ein von OpenAI produziertes Open-Source-Codierungs-Agent-Tool, das auf einem lokalen Computer oder in einem Code-Editor installiert werden kann. Es unterstützt VS Code, Cursor, Windsurf usw.
Open-Source-Adresse: https://github.com/openai/codex
Der Agent Loop (Agentenschleife), der hier vorgestellt wird, ist die Kernlogik von Codex CLI: Er ist verantwortlich für die Koordination von Benutzern, Modellen und Modellaufrufen, um die Interaktion zwischen wertvollen Tools auszuführen.
Agent Loop (Agentenschleife)
Modelle sind nur Komponenten, Agenten machen das Produkt aus.
Der Kern jedes KI-Agenten ist die sogenannte "Agentenschleife (Agent Loop)". Das schematische Diagramm der Agentenschleife ist wie folgt:
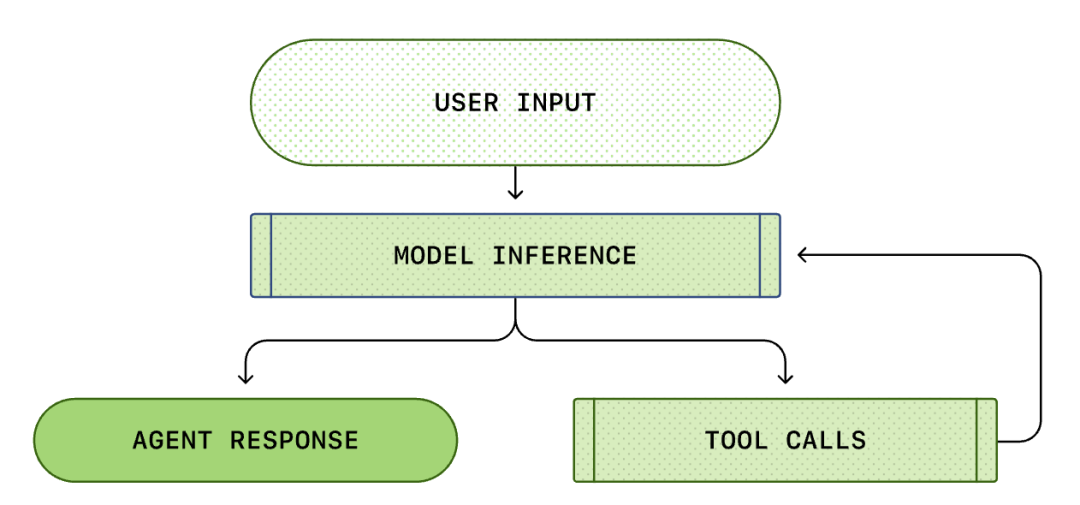
Wir denken normalerweise, dass KI-Programmierung bedeutet: "Ich frage, es antwortet". Aber innerhalb von Codex CLI ist dies ein komplexer, unendlicher Schleifenprozess...
Eine Standard-Agentenschleife umfasst die folgenden Schritte:
- Benutzeranweisungen: Eine Reihe von Textanweisungen, die vom Benutzer eingegeben werden (z. B. "Refaktorieren Sie diese Funktion").
- Modellinferenz: Das Modell entscheidet, ob es direkt antwortet oder ein Tool aufruft (Tool Call).
- Tool-Aufruf: Wenn das Modell beschließt, list files oder run shell aufzurufen, führt die CLI diese Befehle lokal aus.
- Beobachtung (Observation): Die Ergebnisse der Tool-Ausführung (Code, Fehler, Dateiliste) werden erfasst.
- Schleife: Diese Ergebnisse werden dem Gesprächsverlauf hinzugefügt und erneut dem Modell zugeführt. Nachdem das Modell die Ergebnisse gesehen hat, entscheidet es über den nächsten Schritt.
- Beenden: Bis das Modell die Aufgabe als abgeschlossen betrachtet und die endgültige Antwort ausgibt.
Der gesamte Prozess von der "Benutzereingabe" bis zur "Agentenantwort" wird als eine Gesprächsrunde bezeichnet (in Codex als Thread bezeichnet).
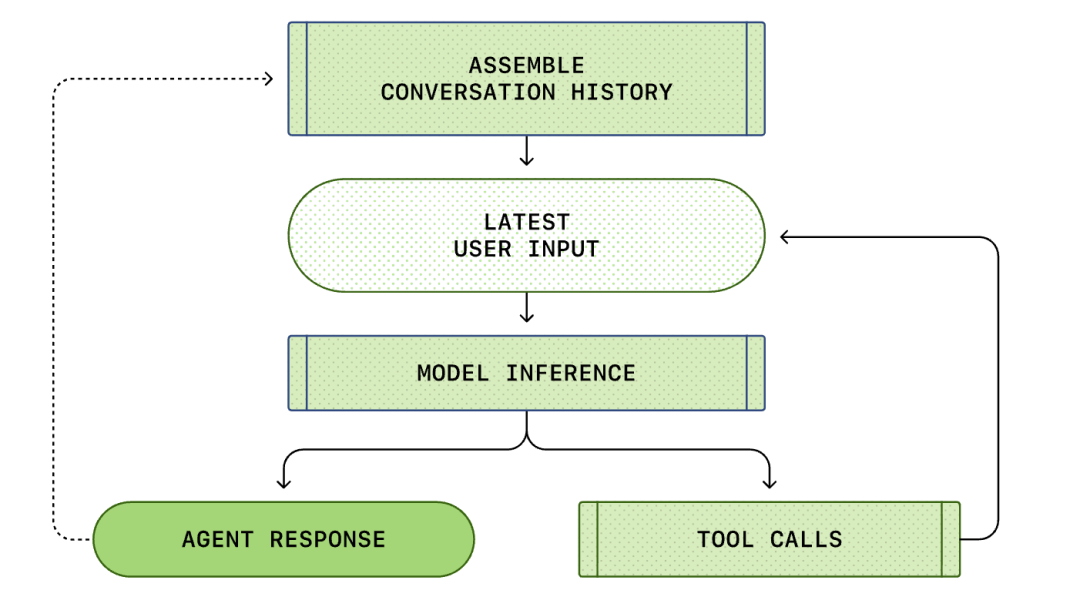
Im Laufe des Gesprächs nimmt auch die Länge des Prompts zu, der für die Modellinferenz verwendet wird. Diese Länge ist wichtig, da jedes Modell ein Kontextfenster hat, das die maximale Anzahl von Token darstellt, die das Modell in einem einzigen Inferenzaufruf verwenden kann.
Modellinferenz
Codex CLI sendet HTTP-Anforderungen an die Responses API, um eine Modellinferenz durchzuführen. Codex verwendet die Responses API, um die Agentenschleife anzutreiben.
Was ist die Responses API?
Die Responses API ist eine neue Generation von Agent-Entwicklungsschnittstellen, die von OpenAI im März 2025 eingeführt wurde, um Dialog-, Tool-Aufruf- und Multimodalitätsverarbeitungsfunktionen zu vereinheitlichen und Entwicklern eine flexiblere und leistungsfähigere Erfahrung beim Erstellen von KI-Anwendungen zu bieten.
Der von Codex CLI verwendete Responses API-Endpunkt ist konfigurierbar und kann mit jedem Endpunkt verwendet werden, der die Responses API implementiert.
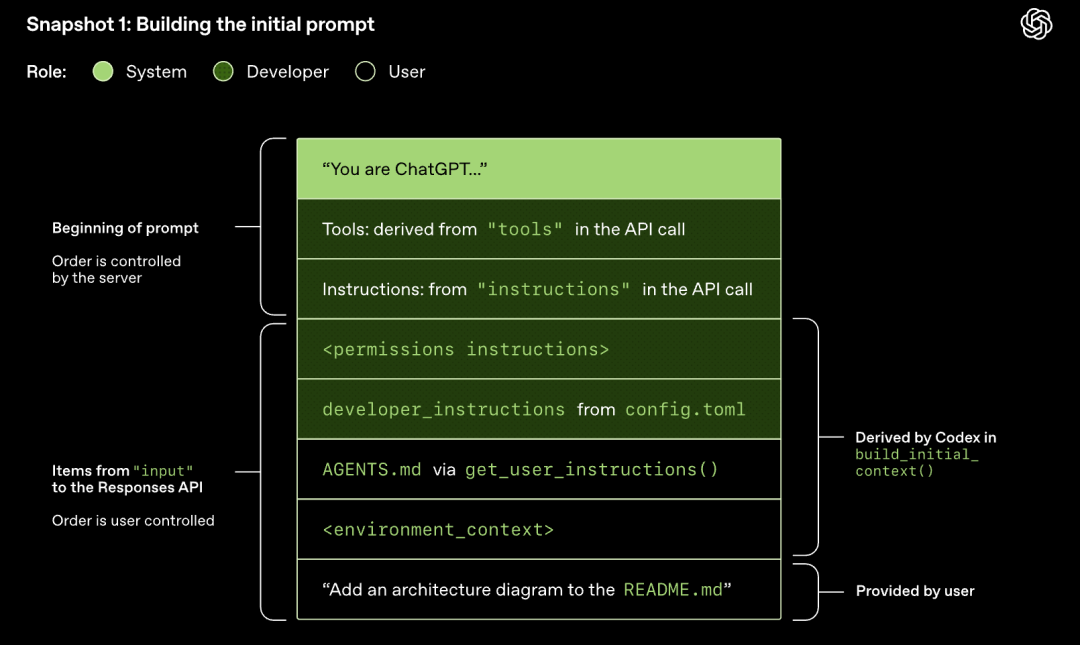
Modell nimmt Stichproben (generiert Antworten)
Die an die Responses API gesendete HTTP-Anforderung startet die erste "Runde" (turn) im Codex-Dialog. Der Server gibt die Antwort über Server-Sent Events (SSE) im Stream zurück.
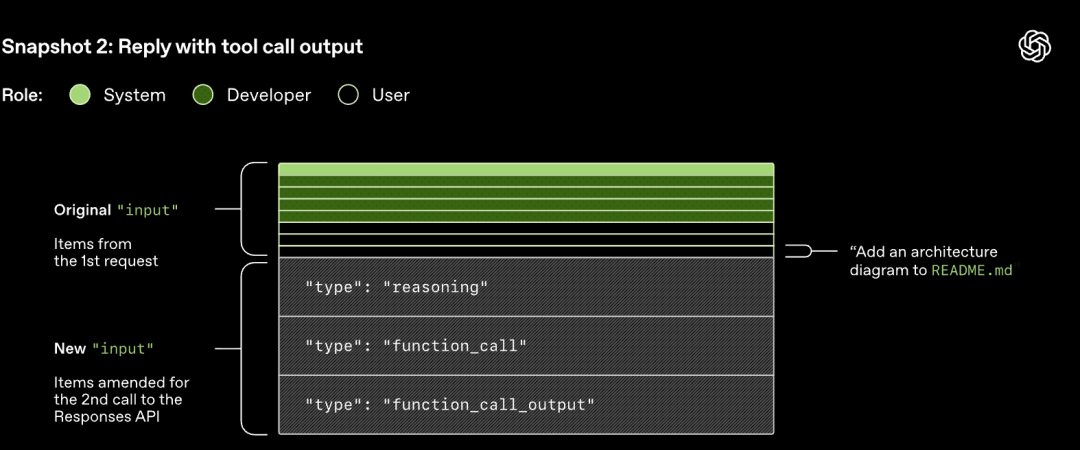
Beachten Sie, dass der Prompt der vorherigen Runde ein exaktes Präfix des neuen Prompts ist. Dieses Design kann die Effizienz nachfolgender Anforderungen erheblich verbessern - es kann ein Prompt-Caching-Mechanismus verwendet werden.

Auswirkungen der kontinuierlichen Verlängerung des Prompts mit zunehmender Anzahl von Runden
1. Leistungsaspekte
- Erhöhte Kosten für die Modellstichprobe: Die kontinuierliche Verlängerung des Prompts führt zu einem Anstieg der Kosten für die Modellstichprobe, da der Stichprobenprozess mehr Daten verarbeiten muss, was zu einer Erhöhung der Rechenlast führt.
- Reduzierte Cache-Effizienz: Mit der kontinuierlichen Verlängerung des Prompts mit zunehmender Anzahl von Runden steigt die Schwierigkeit, eine exakte Präfixübereinstimmung zu erzielen, und die Wahrscheinlichkeit eines Cache-Treffers sinkt.
2. Aspekte des Kontextfenstermanagements
- Kontextfenster ist leicht erschöpft: Die kontinuierliche Verlängerung des Prompts führt zu einer schnellen Zunahme der Anzahl der Token im Dialog. Sobald der Schwellenwert des Kontextfensters überschritten wird, kann dies dazu führen, dass das Kontextfenster erschöpft ist.
- Erhöhte Notwendigkeit von Komprimierungsoperationen: Um zu vermeiden, dass das Kontextfenster erschöpft ist, muss der Dialog komprimiert werden, wenn die Anzahl der Token den Schwellenwert überschreitet.
3. Aspekte des Risikos von Cache-Fehlern
- Mehrere Operationen können leicht zu Cache-Fehlern führen: Wenn aufgrund der Verlängerung des Prompts Operationen wie das Ändern der für das Modell verfügbaren Tools, des Zielmodells oder der Sandbox-Konfiguration erforderlich sind, erhöht dies das Risiko von Cache-Fehlern weiter.
- MCP-Tools erhöhen die Komplexität: Der MCP-Server kann die Liste der bereitgestellten Tools dynamisch ändern. Das Reagieren auf entsprechende Benachrichtigungen in langen Gesprächen kann zu Cache-Fehlern führen.
Referenzinformationen: 《Unrolling the Codex agent loop》Quelle: OpenAI



