¿Quieres entender el agente inteligente Codex? ¡No te puedes perder este análisis profundo!
¿Quieres entender el agente inteligente Codex? ¡No te puedes perder este análisis profundo!
OpenAI acaba de hacer algo "inusual".
Normalmente, OpenAI lanza modelos más potentes (como o1), pero esta vez, publicaron un blog técnico profundo, 《Unrolling the Codex agent loop》, que no solo liberó el código fuente de la lógica central de Codex CLI, sino que también desglosó paso a paso cómo funciona un agente de código (Coding Agent) maduro.

En el momento en que Claude Code y Cursor están ganando popularidad, este artículo de OpenAI no es solo una demostración de fuerza, sino también una "guía para arquitectos de agentes para evitar errores". Ya sea que quieras usar bien las herramientas de programación de IA o desarrollar tu propio Agent, vale la pena estudiar este artículo palabra por palabra.
El artículo completo tiene más de 8300 palabras y se tarda unos 20 minutos en leerlo.
Primero, ¿qué es Codex CLI?
Codex CLI es una herramienta de agente de codificación de código abierto producida por OpenAI, que se puede ejecutar en una computadora local o instalar en un editor de código. Soporta VS Code, Cursor, Windsurf, etc.
Dirección de código abierto: https://github.com/openai/codex
El Agent Loop (bucle del agente) que se presentará en esta ocasión es la lógica central de Codex CLI: es responsable de coordinar al usuario, el modelo y las llamadas al modelo para ejecutar interacciones valiosas entre herramientas.
Agent Loop (Bucle del agente inteligente)
El modelo es solo un componente, el Agent (agente inteligente) puede constituir un producto.
El núcleo de cada AI Agent es el llamado "bucle del agente inteligente (Agent Loop)". El diagrama esquemático del bucle del agente inteligente se muestra a continuación:
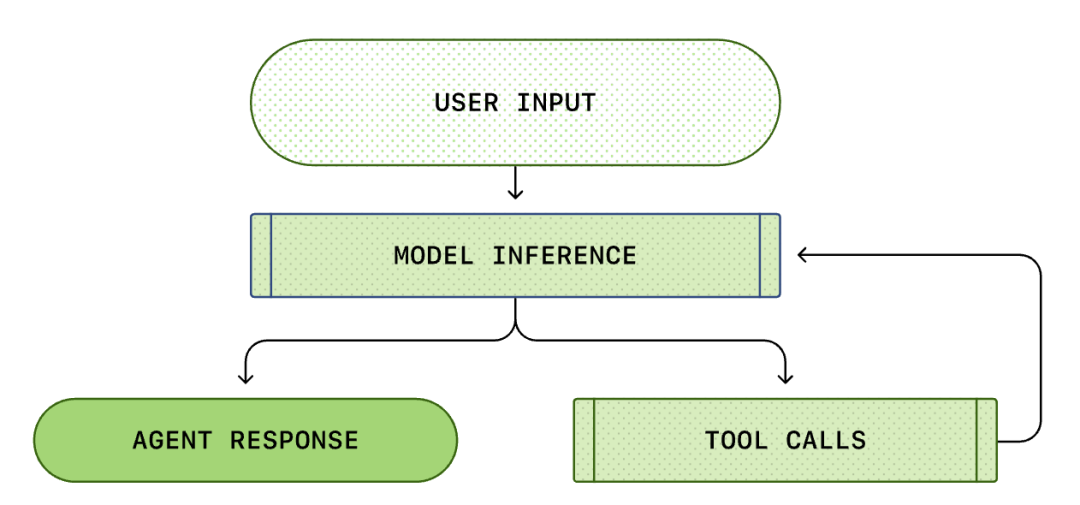
Normalmente pensamos que la programación con IA es: "Yo pregunto, él responde". Pero dentro de Codex CLI, este es un proceso complejo de bucle infinito...
Un Agent Loop estándar contiene los siguientes pasos:
- Instrucciones del usuario: Un conjunto de instrucciones de texto ingresadas por el usuario (por ejemplo, "refactorizar esta función").
- Inferencia del modelo: El modelo decide si responder directamente o llamar a una herramienta (Tool Call).
- Llamada a la herramienta: Si el modelo decide llamar a
list filesorun shell, el CLI ejecutará estos comandos localmente. - Observación (Observation): Se capturan los resultados de la ejecución de la herramienta (código, errores, lista de archivos).
- Bucle (Loop): Estos resultados se agregan al historial de la conversación y se vuelven a alimentar al modelo. Después de ver los resultados, el modelo decide el siguiente paso.
- Terminación (Termination): Hasta que el modelo considere que la tarea está completa, se genera la respuesta final.
Todo el proceso desde la "entrada del usuario" hasta la "respuesta del agente inteligente" se denomina ronda de conversación (en Codex se denomina hilo).
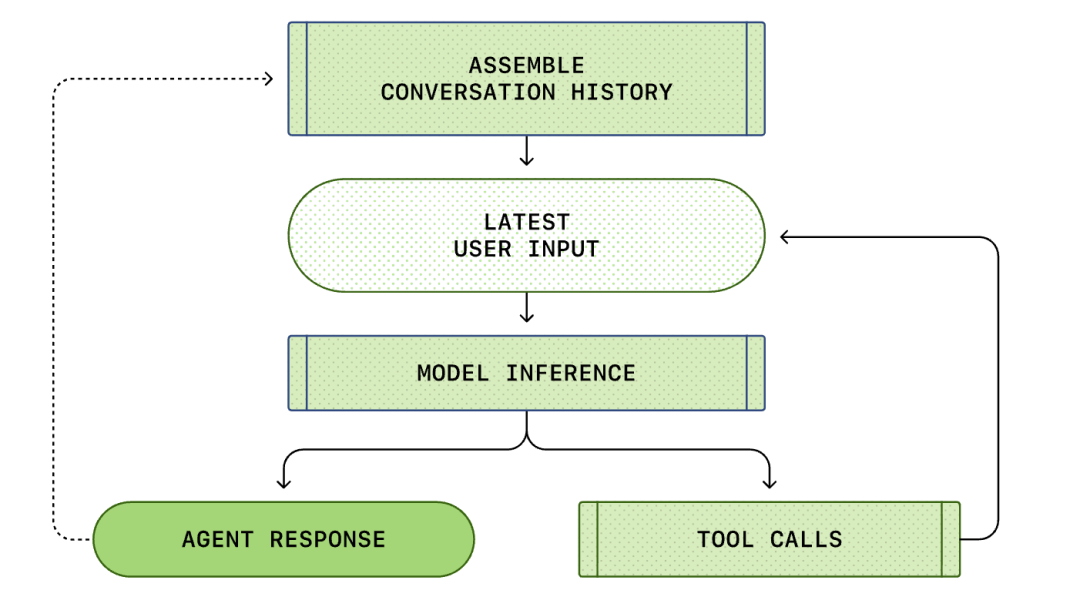
A medida que avanza la conversación, la longitud del prompt utilizado para la inferencia del modelo también aumenta. Esta longitud es importante porque cada modelo tiene una ventana de contexto, que representa el número máximo de tokens que el modelo puede usar en una sola llamada de inferencia.
Inferencia del modelo
Codex CLI envía una solicitud HTTP a la Responses API para la inferencia del modelo. Codex utiliza la Responses API para impulsar el bucle del agente.
¿Qué es la Responses API?
Responses API es una interfaz de desarrollo de agentes inteligentes de nueva generación lanzada por OpenAI en marzo de 2025, cuyo objetivo es unificar las capacidades de conversación, llamada a herramientas y procesamiento multimodal, para proporcionar a los desarrolladores una experiencia de construcción de aplicaciones de IA más flexible y potente.
El punto final de la Responses API utilizado por Codex CLI es configurable y se puede utilizar con cualquier punto final que implemente la Responses API.
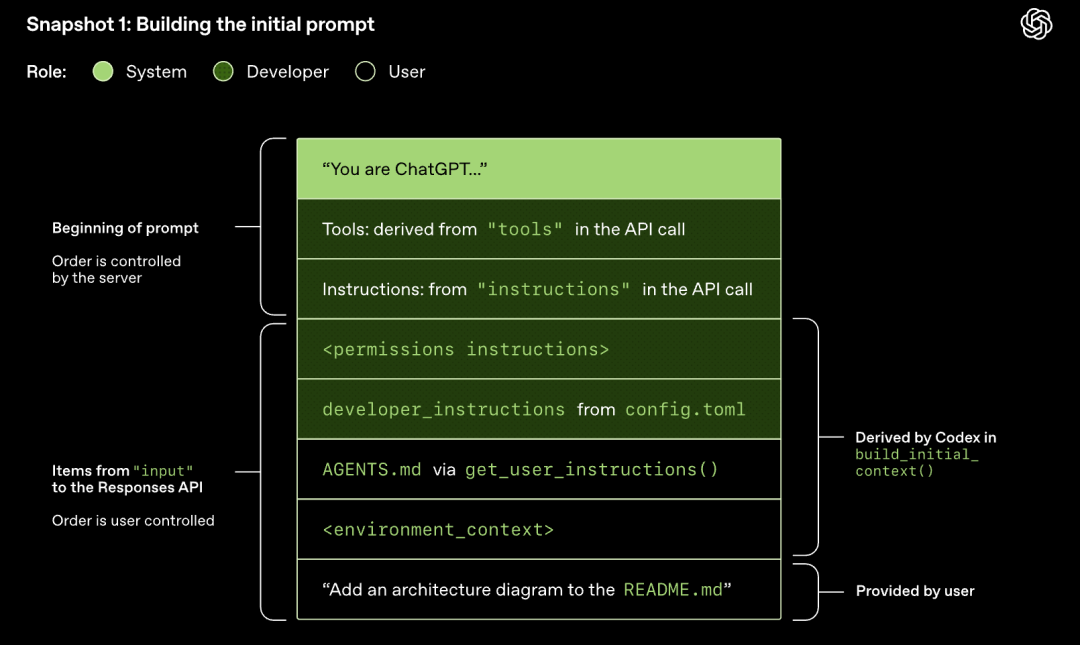
El modelo realiza el muestreo (genera la respuesta)
La solicitud HTTP iniciada a la Responses API inicia el primer "turno" en la conversación de Codex. El servidor devuelve la respuesta en streaming a través de Server-Sent Events (SSE).
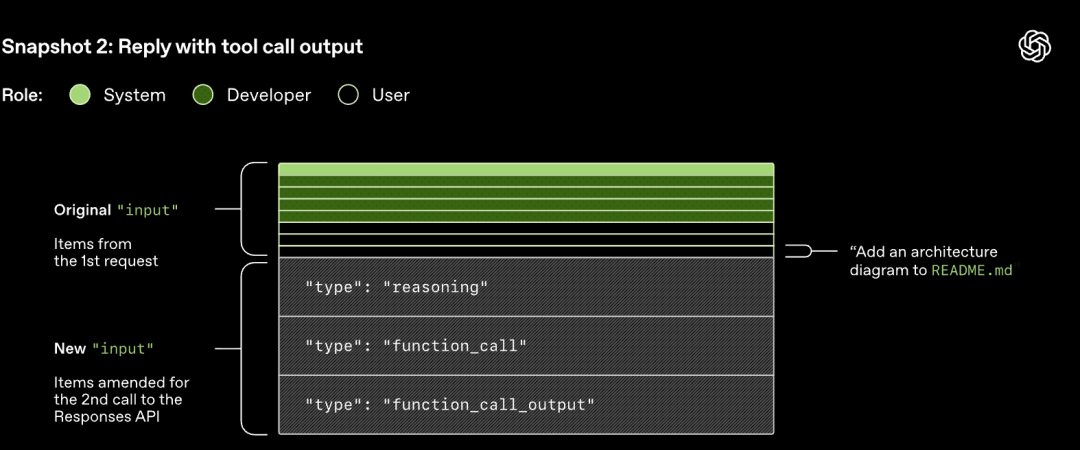
Ten en cuenta que el prompt de la ronda anterior es un prefijo exacto del nuevo prompt. Este diseño puede mejorar significativamente la eficiencia de las solicitudes posteriores: se puede utilizar el mecanismo de caché de prompts.

Impacto del aumento continuo del prompt con el aumento de los turnos
1. En términos de rendimiento
- Aumento del costo de muestreo del modelo: La extensión continua del prompt aumentará el costo de muestreo del modelo, porque el proceso de muestreo necesita procesar más datos, lo que resulta en un aumento de la cantidad de cálculo.
- Disminución de los beneficios de la caché: A medida que el prompt se extiende continuamente con el aumento de los turnos, la dificultad de la coincidencia de prefijos exactos aumenta y la posibilidad de aciertos de caché disminuye.
2. En términos de gestión de la ventana de contexto
- La ventana de contexto se agota fácilmente: La extensión continua del prompt hará que el número de tokens en la conversación aumente rápidamente, y una vez que exceda el umbral de la ventana de contexto, puede provocar el agotamiento de la ventana de contexto.
- Aumento de la necesidad de operaciones de compresión: Para evitar el agotamiento de la ventana de contexto, es necesario comprimir la conversación cuando el número de tokens excede el umbral.
3. En términos de riesgo de fallos de caché
- Múltiples operaciones pueden provocar fallos de caché: Si la extensión del prompt implica cambiar las herramientas disponibles del modelo, el modelo de destino, la configuración del sandbox y otras operaciones, aumentará aún más el riesgo de fallos de caché.
- La herramienta MCP aumenta la complejidad: El servidor MCP puede cambiar dinámicamente la lista de herramientas proporcionadas, y responder a las notificaciones relevantes en conversaciones largas puede provocar fallos de caché.
Información de referencia: 《Unrolling the Codex agent loop》Fuente: OpenAI



