Szeretnéd megérteni a Codex intelligens ágenst? Ezt a mélyreható elemzést nem hagyhatod ki!
Szeretnéd megérteni a Codex intelligens ágenst? Ezt a mélyreható elemzést nem hagyhatod ki!
Az OpenAI most tett egy "szokatlan" dolgot.
Általában az OpenAI erősebb modelleket ad ki (mint például az o1), de ezúttal kiadtak egy mélyreható technikai blogbejegyzést 《Unrolling the Codex agent loop》 címmel, amely nemcsak a Codex CLI alapvető logikáját nyitotta meg, hanem lépésről lépésre lebontotta, hogyan is működik egy kiforrott kódoló intelligens ágens (Coding Agent).

A Claude Code és a Cursor őrült népszerűségének idején az OpenAI cikke nemcsak az izommutogatásról szól, hanem egy "Ágens építészeknek szóló buktatók elkerülésére vonatkozó útmutató" is. Akár jól szeretnéd használni az AI programozási eszközöket, akár saját ágenst szeretnél fejleszteni, ezt a cikket érdemes szóról szóra elolvasni.
A teljes szöveg 8300+ szó, az olvasás körülbelül 20 percet vesz igénybe.
Először is, mi az a Codex CLI?
A Codex CLI az OpenAI által kiadott nyílt forráskódú kódoló ágens eszköz, amely futtatható a helyi számítógépen, vagy telepíthető kódszerkesztőbe. Támogatja a VS Code, Cursor, Windsurf stb. alkalmazásokat.
Nyílt forráskódú cím: https://github.com/openai/codex
A bemutatandó Agent Loop (ágens hurok) a Codex CLI alapvető logikája: felelős a felhasználó, a modell és a modellhívások koordinálásáért, hogy értékes eszközök közötti interakciókat hajtson végre.
Agent Loop (intelligens ágens hurok)
A modellek csak összetevők, az Agent (intelligens ágens) alkotja a terméket.
Mindegyik AI Agent magja az úgynevezett "intelligens ágens hurok (Agent Loop)". Az intelligens ágens hurok sematikus ábrája az alábbiak szerint:
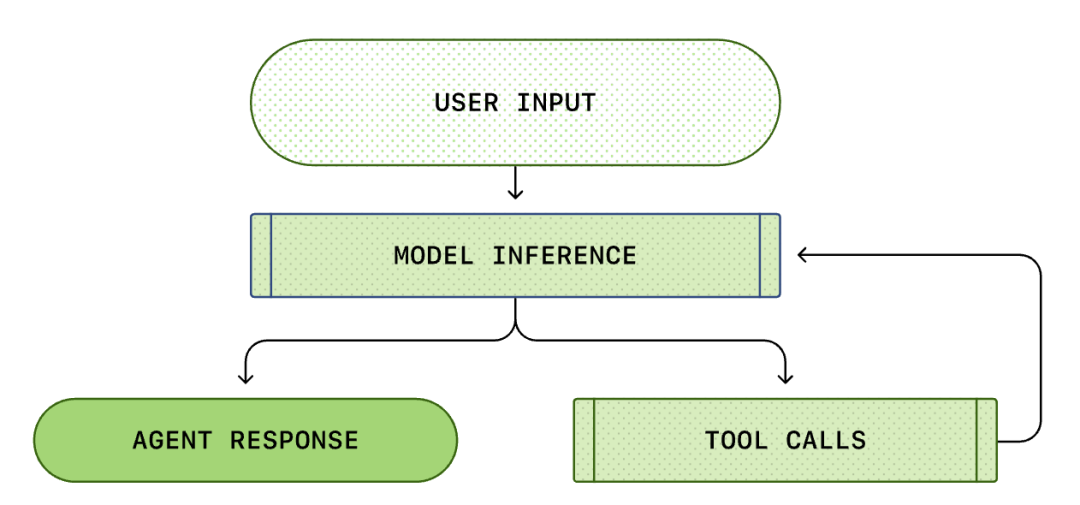
Általában azt gondoljuk, hogy az AI programozás: "Én kérdezek, ő válaszol". De a Codex CLI-n belül ez egy összetett, végtelen ciklus...
Egy szabványos Agent Loop a következő lépéseket tartalmazza:
- Felhasználói utasítások: A felhasználó által bevitt szöveges utasítások (például "alakítsd át ezt a függvényt").
- Modell következtetés: A modell eldönti, hogy közvetlenül válaszol-e, vagy eszközt hív meg (Tool Call).
- Eszközhívás: Ha a modell úgy dönt, hogy meghívja a list files vagy run shell parancsot, a CLI helyben végrehajtja ezeket a parancsokat.
- Megfigyelés (Observation): Az eszköz végrehajtásának eredményei (kód, hibák, fájllista) rögzítésre kerülnek.
- Hurok: Ezek az eredmények hozzáadódnak a beszélgetési előzményekhez, és újra betáplálásra kerülnek a modellbe. A modell az eredmények láttán eldönti a következő lépést.
- Befejezés: Amíg a modell úgy nem gondolja, hogy a feladat befejeződött, kiadja a végső választ.
A "felhasználói bemenettől" az "intelligens ágens válaszáig" tartó teljes folyamatot a beszélgetés egy fordulójának nevezzük (a Codexben szálnak nevezik).
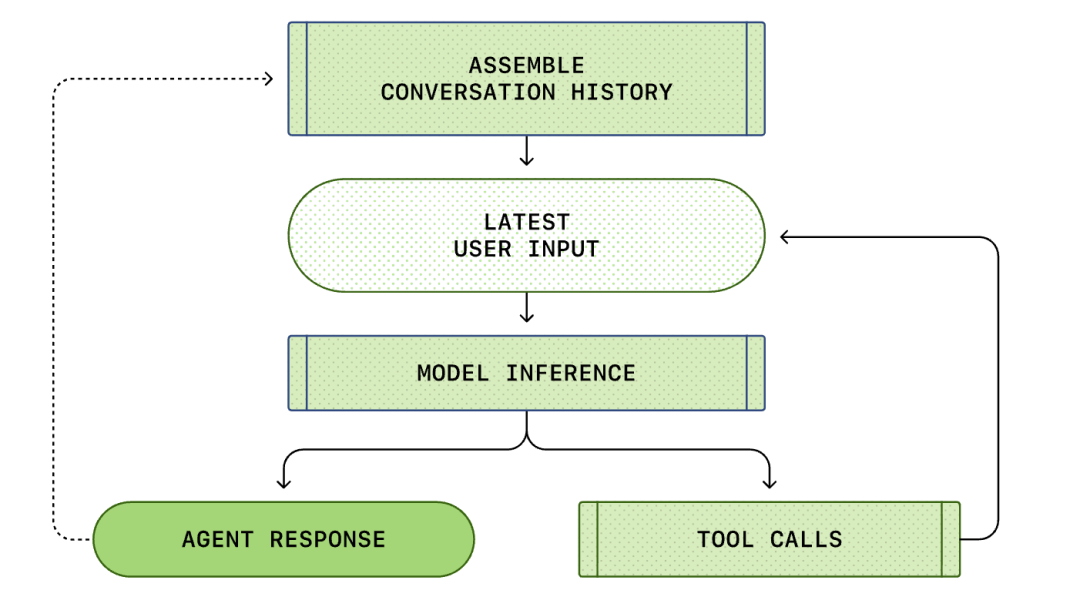
A beszélgetés előrehaladtával a modell következtetéséhez használt prompt (Prompt) hossza is növekszik. Ez a hossz fontos, mert minden modellnek van egy kontextusablaka, amely azt a maximális számú tokent (tokens) jelenti, amelyet a modell egy következtetési hívás során használhat.
Modell következtetés
A Codex CLI HTTP-kérést küld a Responses API-nak a modell következtetéséhez. A Codex a Responses API-t használja az ágens hurok meghajtására.
Mi az a Responses API?
A Responses API az OpenAI által 2025 márciusában bevezetett új generációs intelligens ágens fejlesztési interfész, amelynek célja a beszélgetés, az eszközhívások és a többmódusú feldolgozási képességek egységesítése, hogy a fejlesztők számára rugalmasabb és hatékonyabb AI alkalmazásfejlesztési élményt nyújtson.
A Codex CLI által használt Responses API végpont konfigurálható, és bármely Responses API-t megvalósító végponttal használható.
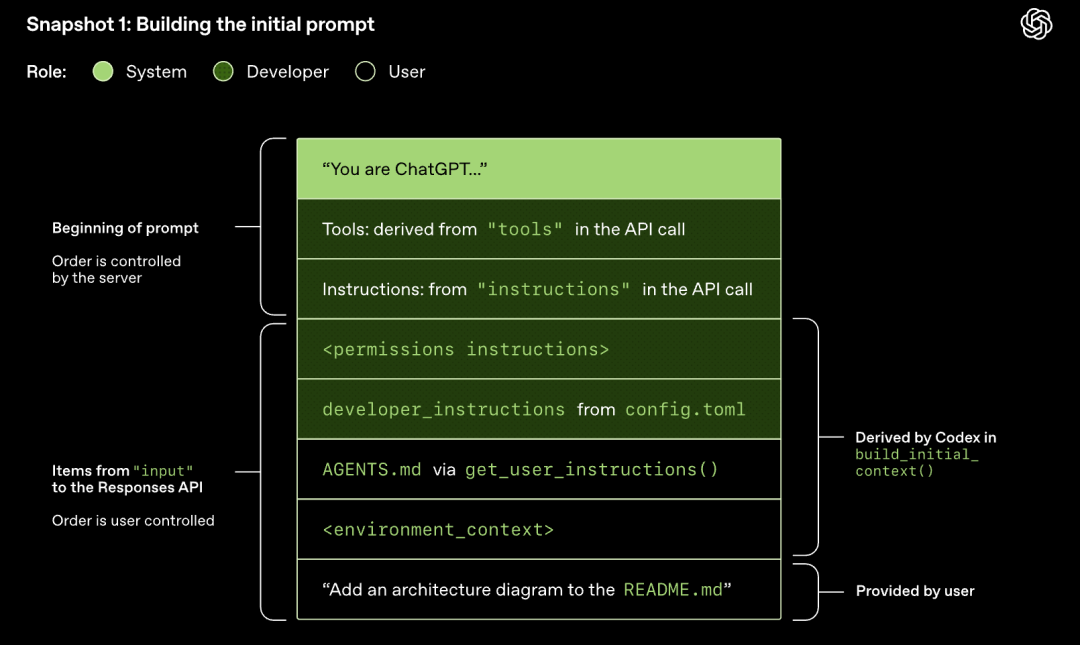
Modell mintavételezés (válasz generálása)
A Responses API-hoz intézett HTTP-kérés elindítja a Codex beszélgetésének első "fordulóját" (turn). A szerver Server-Sent Events (SSE) streamen keresztül adja vissza a választ.
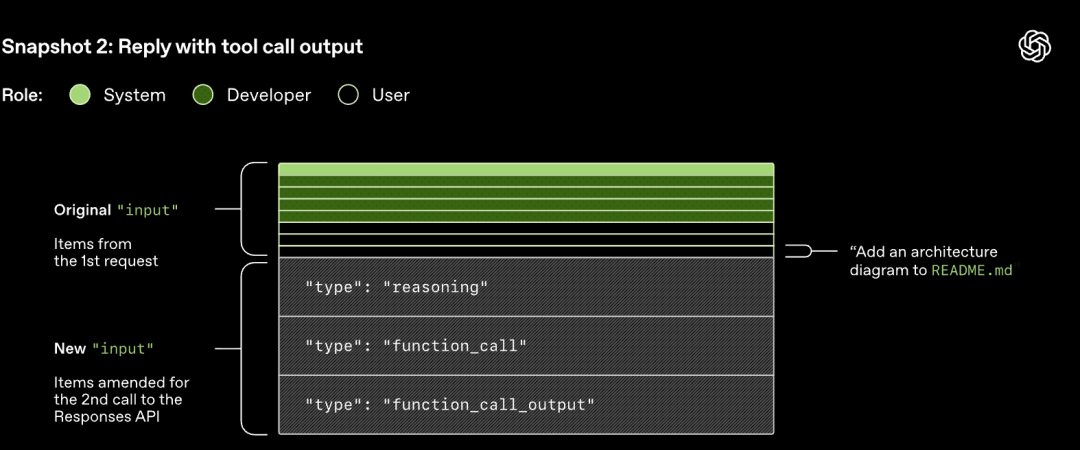
Figyelem, az előző forduló promptja az új prompt pontos előtagja. Ez a kialakítás jelentősen javíthatja a későbbi kérések hatékonyságát – kihasználható a prompt gyorsítótár mechanizmus.

A prompt fordulókkal való növekedésének hatásai
1. Teljesítmény szempontjából
- A modell mintavételezési költségeinek növekedése: A prompt folyamatos meghosszabbítása növeli a modell mintavételezési költségeit, mivel a mintavételezési folyamatnak több adatot kell feldolgoznia, ami megnöveli a számítási mennyiséget.
- A gyorsítótár hatékonyságának csökkenése: Ahogy a prompt a fordulókkal együtt folyamatosan meghosszabbodik, a pontos előtag egyeztetés nehézsége nő, és a gyorsítótár találati valószínűsége csökken.
2. Kontextusablak kezelés szempontjából
- A kontextusablak könnyen kimerül: A prompt folyamatos meghosszabbítása a beszélgetésben lévő tokenek számának gyors növekedését okozza, és ha túllépi a kontextusablak küszöbértékét, a kontextusablak kimerüléséhez vezethet.
- A tömörítési műveletek szükségességének növekedése: A kontextusablak kimerülésének elkerülése érdekében a beszélgetést tömöríteni kell, ha a tokenek száma meghaladja a küszöbértéket.
3. A gyorsítótár kihagyás kockázata szempontjából
- Számos művelet könnyen kiválthatja a gyorsítótár kihagyását: Ha a prompt meghosszabbítása miatt a modell elérhető eszközeinek, a célmodellnek, a sandbox konfigurációjának stb. megváltoztatására kerül sor, az tovább növeli a gyorsítótár kihagyás kockázatát.
- Az MCP eszközök növelik a komplexitást: Az MCP szerver dinamikusan megváltoztathatja a rendelkezésre álló eszközök listáját, és a kapcsolódó értesítésekre való reagálás hosszú beszélgetések során a gyorsítótár kihagyásához vezethet.
Tájékoztatás: 《Unrolling the Codex agent loop》 Forrás: OpenAI



