Vuoi capire l'agente intelligente Codex? Non perderti questa analisi approfondita!
Vuoi capire l'agente intelligente Codex? Non perderti questa analisi approfondita!
OpenAI ha appena fatto qualcosa di "insolito".
Di solito, OpenAI rilascia modelli più potenti (come o1), ma questa volta ha pubblicato un blog tecnico approfondito intitolato 《Unrolling the Codex agent loop》, non solo aprendo il codice sorgente della logica principale di Codex CLI, ma anche smontando passo dopo passo come funziona un agente di codifica (Coding Agent) maturo.

Nel momento in cui Claude Code e Cursor stanno guadagnando popolarità, questo articolo di OpenAI non è solo una dimostrazione di forza, ma anche una "guida per evitare insidie per gli architetti di Agent". Che tu voglia utilizzare al meglio gli strumenti di programmazione AI o sviluppare un tuo Agent, vale la pena studiare questo articolo parola per parola.
L'articolo completo ha più di 8300 parole e la lettura richiede circa 20 minuti.
Innanzitutto, cos'è Codex CLI?
Codex CLI è uno strumento Agent di codifica open source prodotto da OpenAI, che può essere eseguito su un computer locale o installato in un editor di codice. Supporta VS Code, Cursor, Windsurf, ecc.
Indirizzo open source: https://github.com/openai/codex
L'Agent Loop (ciclo dell'agente) che verrà presentato in questo articolo è la logica principale di Codex CLI: è responsabile del coordinamento tra l'utente, il modello e le chiamate del modello, al fine di eseguire interazioni di valore tra gli strumenti.
Agent Loop (Ciclo dell'agente intelligente)
Il modello è solo un componente, solo l'Agent (agente intelligente) può costituire un prodotto.
Il cuore di ogni AI Agent è il cosiddetto "ciclo dell'agente intelligente (Agent Loop)". Il diagramma schematico del ciclo dell'agente intelligente è il seguente:
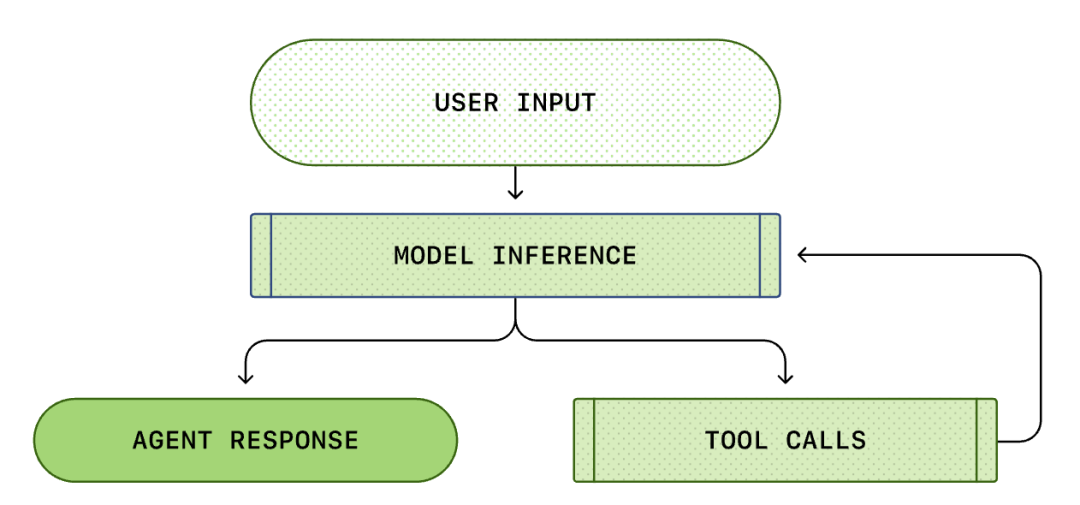
Di solito pensiamo che la programmazione AI sia: "Io chiedo, lui risponde". Ma all'interno di Codex CLI, questo è un complesso processo di ciclo infinito...
Un Agent Loop standard include le seguenti fasi:
- Istruzioni dell'utente: un insieme di istruzioni di testo inserite dall'utente (ad esempio "Rifattorizza questa funzione").
- Inferenza del modello: il modello decide se rispondere direttamente o chiamare uno strumento (Tool Call).
- Chiamata dello strumento: se il modello decide di chiamare list files o run shell, CLI eseguirà questi comandi localmente.
- Osservazione (Observation): vengono acquisiti i risultati dell'esecuzione dello strumento (codice, errori, elenco dei file).
- Ciclo (Loop): questi risultati vengono aggiunti alla cronologia della conversazione e reinseriti nel modello. Dopo aver visto i risultati, il modello decide il passo successivo.
- Terminazione (Termination): fino a quando il modello non ritiene che l'attività sia completata, emette la risposta finale.
L'intero processo dall'"input dell'utente" alla "risposta dell'agente intelligente" è chiamato round di conversazione (chiamato thread in Codex).
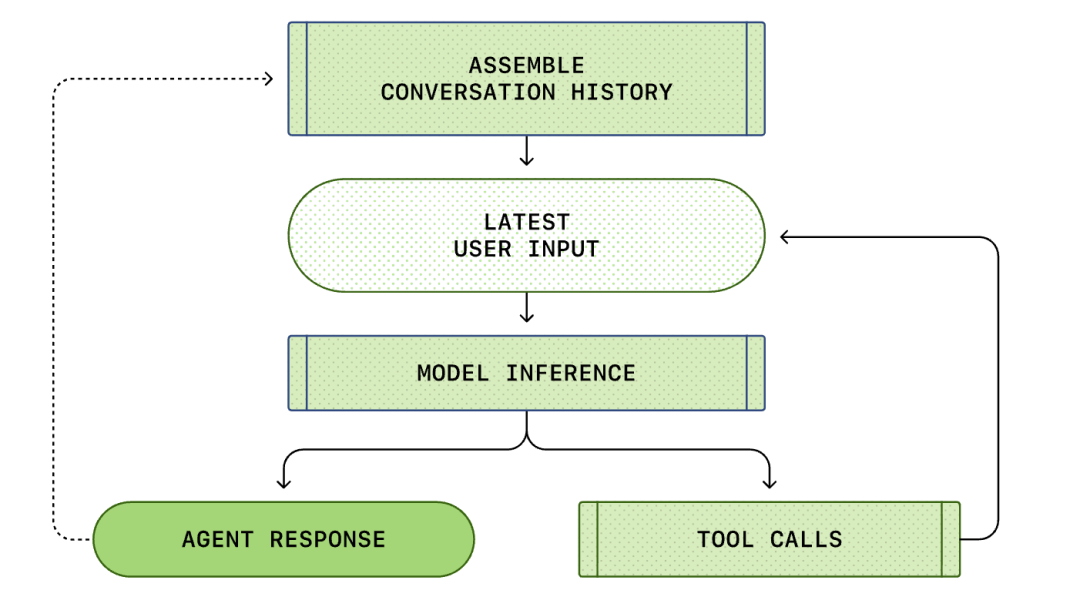
Man mano che la conversazione procede, aumenta anche la lunghezza del prompt utilizzato per l'inferenza del modello. Questa lunghezza è importante perché ogni modello ha una finestra di contesto, che rappresenta il numero massimo di token che il modello può utilizzare in una singola chiamata di inferenza.
Inferenza del modello
Codex CLI invia una richiesta HTTP all'API Responses per l'inferenza del modello. Codex utilizza l'API Responses per guidare il ciclo dell'agente.
Cos'è l'API Responses?
L'API Responses è un'API di sviluppo di agenti di nuova generazione lanciata da OpenAI nel marzo 2025, progettata per unificare le capacità di conversazione, chiamata di strumenti ed elaborazione multimodale, fornendo agli sviluppatori un'esperienza di creazione di applicazioni AI più flessibile e potente.
L'endpoint dell'API Responses utilizzato da Codex CLI è configurabile e può essere utilizzato con qualsiasi endpoint che implementi l'API Responses.
Il modello esegue il campionamento (genera la risposta)
La richiesta HTTP avviata all'API Responses avvia il primo "round" (turn) nella conversazione di Codex. Il server restituirà la risposta in streaming tramite Server-Sent Events (SSE).
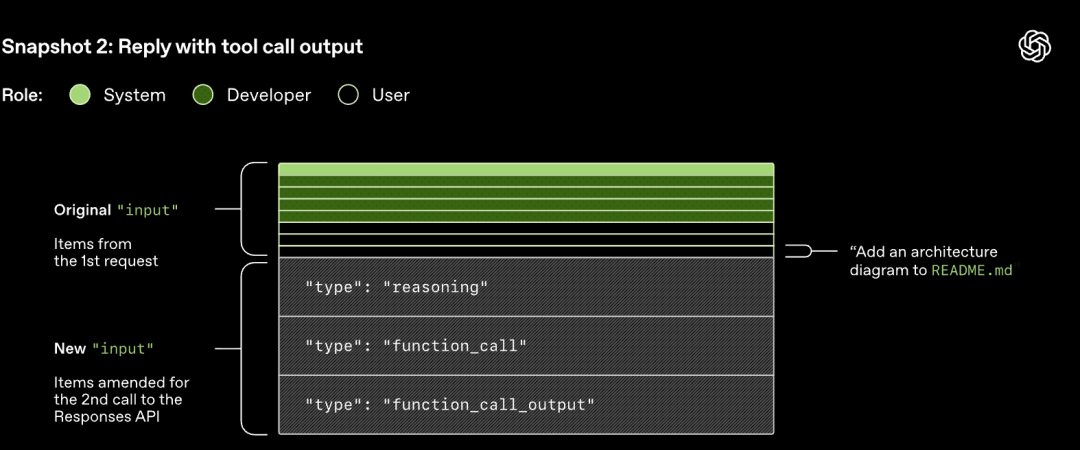
Si noti che il prompt del round precedente è il prefisso esatto del nuovo prompt. Questo design può migliorare significativamente l'efficienza delle richieste successive: è possibile sfruttare il meccanismo di cache del prompt.

L'impatto dell'aumento continuo del prompt con l'aumentare dei round
1. Aspetti prestazionali
- Aumento dei costi di campionamento del modello: l'estensione continua del prompt aumenterà i costi di campionamento del modello, perché il processo di campionamento deve elaborare più dati, con conseguente aumento del carico di calcolo.
- Riduzione dell'efficacia della cache: con l'aumento continuo del prompt con l'aumentare dei round, la difficoltà di corrispondenza del prefisso esatto aumenta e la probabilità di hit della cache diminuisce.
2. Aspetti della gestione della finestra di contesto
- Facile esaurimento della finestra di contesto: l'estensione continua del prompt farà aumentare rapidamente il numero di token nella conversazione e, una volta superata la soglia della finestra di contesto, potrebbe causare l'esaurimento della finestra di contesto.
- Aumento della necessità di operazioni di compressione: per evitare l'esaurimento della finestra di contesto, è necessario comprimere la conversazione quando il numero di token supera la soglia.
3. Aspetti del rischio di mancato hit della cache
- Molteplici operazioni possono facilmente innescare un mancato hit della cache: se l'estensione del prompt comporta modifiche agli strumenti disponibili del modello, al modello di destinazione, alla configurazione della sandbox e ad altre operazioni, aumenterà ulteriormente il rischio di mancato hit della cache.
- Gli strumenti MCP aumentano la complessità: il server MCP può modificare dinamicamente l'elenco degli strumenti forniti e rispondere alle relative notifiche in conversazioni lunghe può causare un mancato hit della cache.
Informazioni di riferimento: 《Unrolling the Codex agent loop》Fonte: OpenAI



