Codexエージェントを理解したい?この詳細な分析を見逃すな!
Codexエージェントを理解したい?この詳細な分析を見逃すな!
OpenAIはつい最近、「異例」なことをしました。
通常、OpenAIが発表するのはより強力なモデル(o1など)ですが、今回は、詳細な技術ブログ《Unrolling the Codex agent loop》を発表し、Codex CLIのコアロジックをオープンソース化しただけでなく、成熟したコードエージェント(Coding Agent)がどのように動作するのかを手取り足取り解説しました。

Claude CodeやCursorが人気を集めている現在、OpenAIのこの記事は単なる力自慢ではなく、「Agentアーキテクトのための落とし穴回避ガイド」でもあります。AIプログラミングツールを使いこなしたい人も、自分でAgentを開発したい人も、この記事は一字一句読む価値があります。
全文8300字以上、読むのに約20分かかります。
まず、Codex CLIとは?
Codex CLIは、OpenAIが開発したオープンソースのコーディングAgentツールで、ローカルコンピュータ上で実行することも、コードエディタにインストールすることもできます。VS Code、Cursor、Windsurfなどをサポートしています。
オープンソースアドレス:https://github.com/openai/codex
今回紹介するAgent Loop(エージェントループ)は、Codex CLIのコアロジックであり、ユーザー、モデル、およびモデルの呼び出しを調整して、価値のあるツール間のインタラクションを実行します。
Agent Loop(エージェントループ)
モデルは単なるコンポーネントであり、Agent(エージェント)こそが製品を構成します。
すべてのAI Agentの中核は、いわゆる「エージェントループ(Agent Loop)」です。エージェントループの概略図を以下に示します。
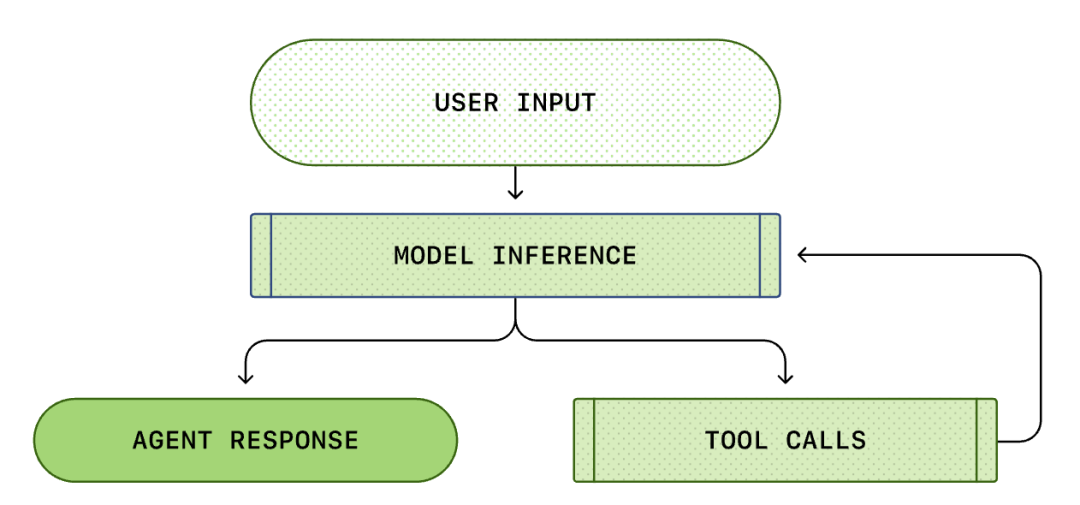
私たちは通常、AIプログラミングを「私が質問し、AIが答える」と考えています。しかし、Codex CLI内部では、これは複雑な無限ループのプロセスです...
標準的なAgent Loopには、以下の段階が含まれます。
- ユーザー命令:ユーザーが入力したテキスト命令のセット(例:「この関数をリファクタリングする」)。
- モデル推論:モデルは、直接回答するか、ツール(Tool Call)を呼び出すかを決定します。
- ツール呼び出し:モデルが list files または run shell を呼び出すことを決定した場合、CLIはローカルでこれらのコマンドを実行します。
- 観察(Observation):ツールの実行結果(コード、エラー、ファイルリスト)がキャプチャされます。
- ループ:これらの結果は会話履歴に追加され、再度モデルに供給されます。モデルは結果を見て、次の操作を決定します。
- 終了:モデルがタスクが完了したと判断するまで、最終的な応答を出力します。
「ユーザー入力」から「エージェント応答」までのプロセス全体は、会話の1ラウンド(Codexではスレッドと呼ばれる)と呼ばれます。
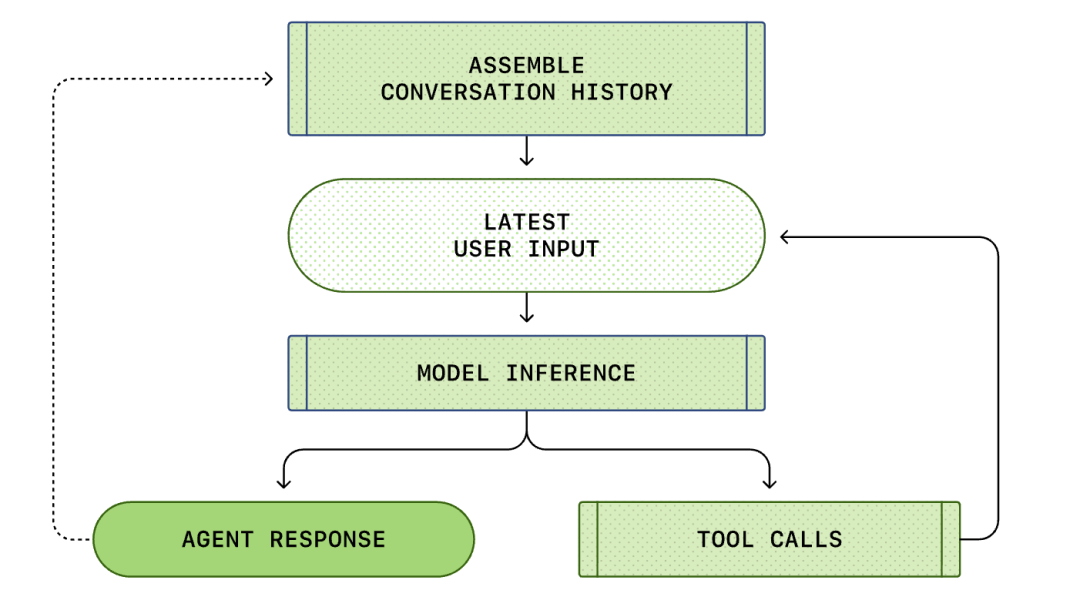
会話が進むにつれて、モデルの推論に使用されるプロンプト(Prompt)の長さも増加します。この長さは重要です。なぜなら、各モデルにはコンテキストウィンドウがあり、これはモデルが1回の推論呼び出しで使用できる最大トークン数を表しているからです。
モデル推論
Codex CLIは、Responses APIにHTTPリクエストを送信して、モデル推論を実行します。CodexはResponses APIを使用して、エージェントループを駆動します。
Responses APIとは?
Responses APIは、OpenAIが2025年3月に発表した次世代のエージェント開発インターフェースであり、会話、ツール呼び出し、およびマルチモーダル処理能力を統合し、開発者により柔軟で強力なAIアプリケーション構築体験を提供することを目的としています。
Codex CLIで使用されるResponses APIのエンドポイントは構成可能であり、Responses APIを実装する任意のエンドポイントで使用できます。
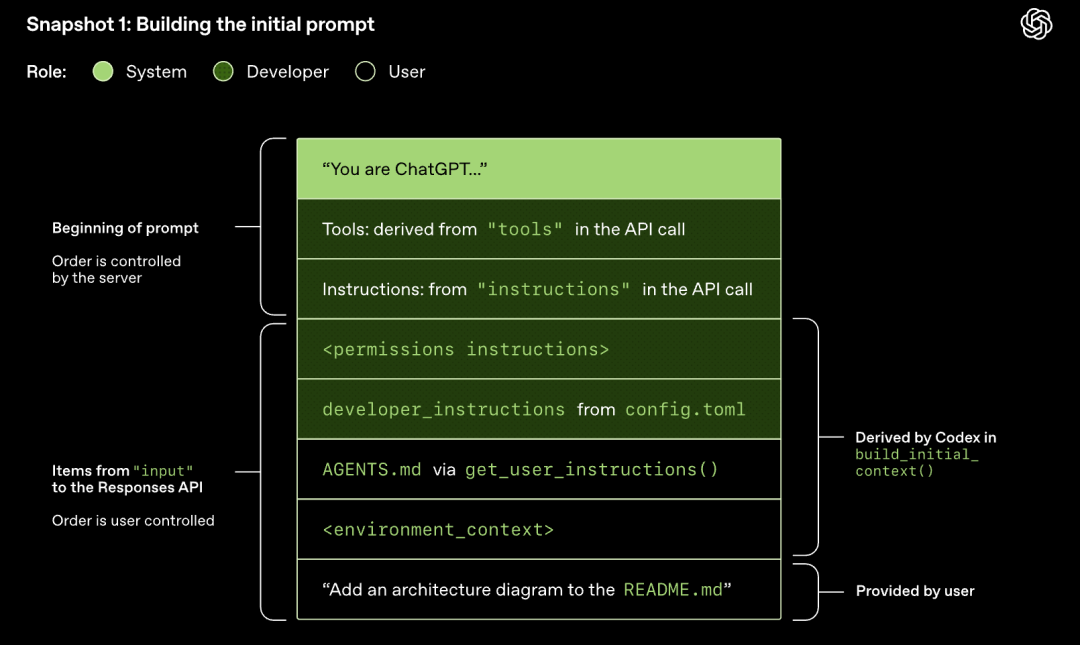
モデルがサンプリングを実行する(応答を生成する)
Responses APIに開始されたHTTPリクエストは、Codexの会話における最初の「ターン」を開始します。サーバーは、Server-Sent Events (SSE) を介して応答をストリーミングで返します。
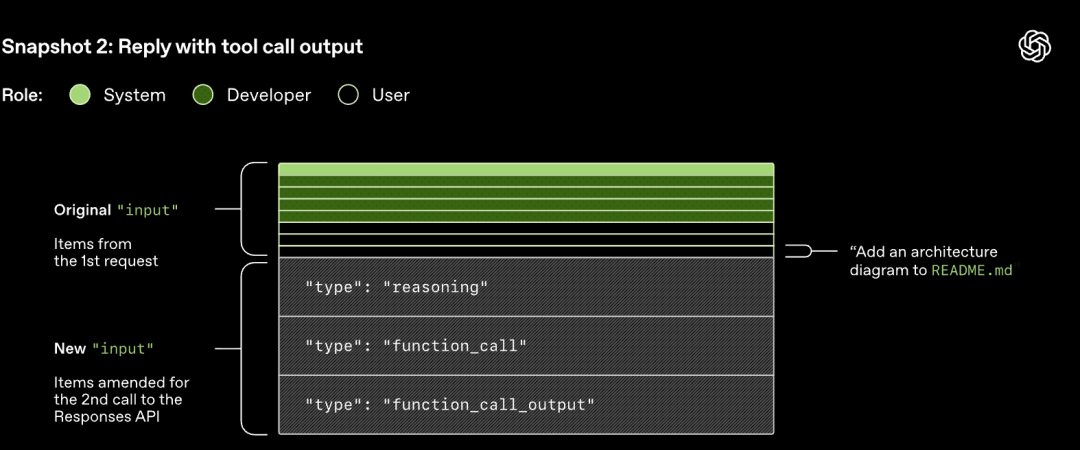
前のターンのプロンプトは、新しいプロンプトの正確なプレフィックスであることに注意してください。この設計により、後続のリクエストの効率が大幅に向上します。プロンプトキャッシュメカニズムを利用できるからです。

ターン数が増加するにつれてプロンプトが長くなることの影響
1. パフォーマンス面
- モデルサンプリングコストの増加:プロンプトが長くなるにつれて、モデルサンプリングコストが上昇します。これは、サンプリングプロセスがより多くのデータを処理する必要があるため、計算量が増加するためです。
- キャッシュ効率の低下:プロンプトがターン数とともに長くなるにつれて、正確なプレフィックスマッチングの難易度が増し、キャッシュヒットの可能性が低下します。
2. コンテキストウィンドウ管理面
- コンテキストウィンドウが枯渇しやすい:プロンプトが長くなるにつれて、会話内のトークン数が急速に増加し、コンテキストウィンドウのしきい値を超えると、コンテキストウィンドウが枯渇する可能性があります。
- 圧縮操作の必要性の増加:コンテキストウィンドウの枯渇を避けるために、トークン数がしきい値を超えたときに会話を圧縮する必要があります。
3. キャッシュミスリスク面
- さまざまな操作がキャッシュミスを引き起こしやすい:プロンプトの延長により、モデルで使用可能なツール、ターゲットモデル、サンドボックス構成などの変更が必要になる場合、キャッシュミスのリスクがさらに高まります。
- MCPツールの複雑さの増加:MCPサーバーは、提供されるツールリストを動的に変更できます。長時間の会話で関連する通知に応答すると、キャッシュミスが発生する可能性があります。
参考情報:《Unrolling the Codex agent loop》出典:OpenAI



