გსურთ გაიგოთ Codex-ის ინტელექტუალური აგენტი? ეს სიღრმისეული ანალიზი არ უნდა გამოტოვოთ!
გსურთ გაიგოთ Codex-ის ინტელექტუალური აგენტი? ეს სიღრმისეული ანალიზი არ უნდა გამოტოვოთ!
OpenAI-მ ახლახან გააკეთა „არაჩვეულებრივი“ რამ.
როგორც წესი, OpenAI აქვეყნებს უფრო ძლიერ მოდელებს (როგორიცაა o1), მაგრამ ამჯერად მათ გამოაქვეყნეს სიღრმისეული ტექნიკური ბლოგი სახელწოდებით „Unrolling the Codex agent loop“, რომელშიც არა მხოლოდ გახსნეს Codex CLI-ის ძირითადი ლოგიკა, არამედ დეტალურად გააანალიზეს, თუ როგორ მუშაობს კოდის ინტელექტუალური აგენტი (Coding Agent).

იმ დროს, როდესაც Claude Code და Cursor გიჟურად იზიდავენ ფანებს, OpenAI-ს ეს სტატია არა მხოლოდ კუნთების დემონსტრირებაა, არამედ „Agent-ის არქიტექტორისთვის ხაფანგების თავიდან აცილების სახელმძღვანელოა“. მიუხედავად იმისა, გსურთ AI პროგრამირების ხელსაწყოების კარგად გამოყენება, თუ საკუთარი აგენტის შემუშავება, ეს სტატია ყურადღებით უნდა წაიკითხოთ.
სრული ტექსტი 8300+ სიტყვაა, წაკითხვას დაახლოებით 20 წუთი დასჭირდება.
პირველ რიგში, რა არის Codex CLI?
Codex CLI არის OpenAI-ის მიერ წარმოებული კოდირების აგენტის ღია კოდის ინსტრუმენტი, რომელიც შეიძლება გაშვებული იყოს ლოკალურ კომპიუტერზე ან დაინსტალირებული იყოს კოდის რედაქტორში. მხარს უჭერს VS Code, Cursor, Windsurf და სხვა.
ღია კოდის მისამართი: https://github.com/openai/codex
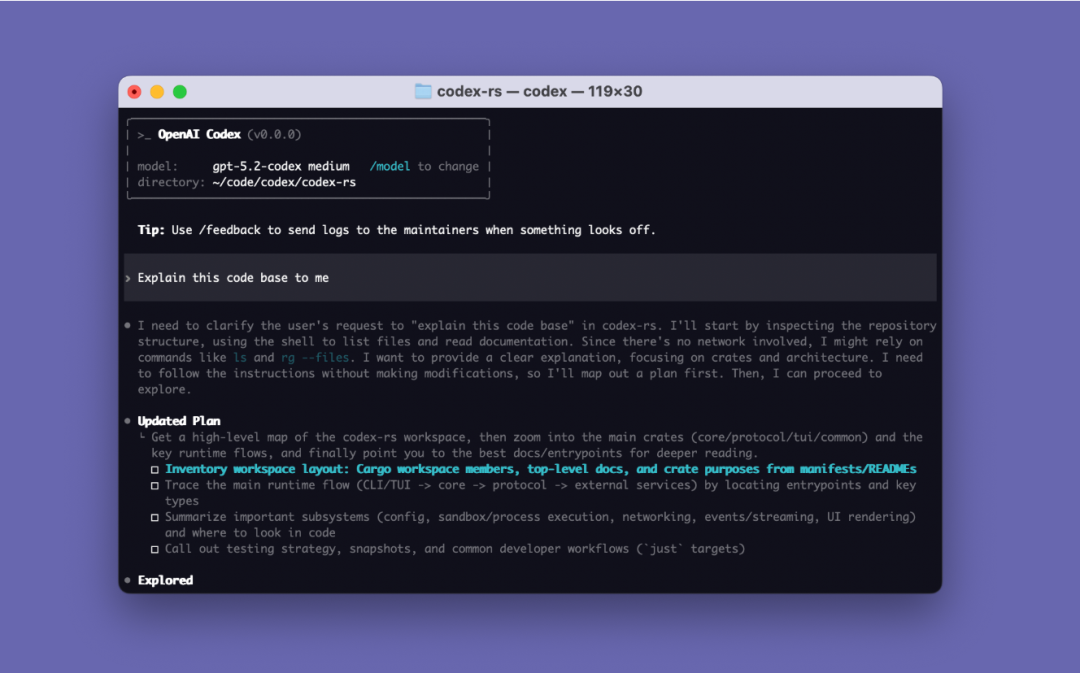
Agent Loop (აგენტის ციკლი), რომლის შესახებაც ამჯერად ვისაუბრებთ, არის Codex CLI-ის ძირითადი ლოგიკა: ის პასუხისმგებელია მომხმარებლების, მოდელებისა და მოდელის გამოძახებების კოორდინაციაზე, რათა განახორციელოს ღირებული ინსტრუმენტების ურთიერთქმედება.
Agent Loop (ინტელექტუალური აგენტის ციკლი)
მოდელები მხოლოდ კომპონენტებია, Agent (ინტელექტუალური აგენტი) ქმნის პროდუქტს.
თითოეული AI Agent-ის ბირთვი არის ე.წ. „ინტელექტუალური აგენტის ციკლი (Agent Loop)“. ინტელექტუალური აგენტის ციკლის სქემა ნაჩვენებია ქვემოთ:
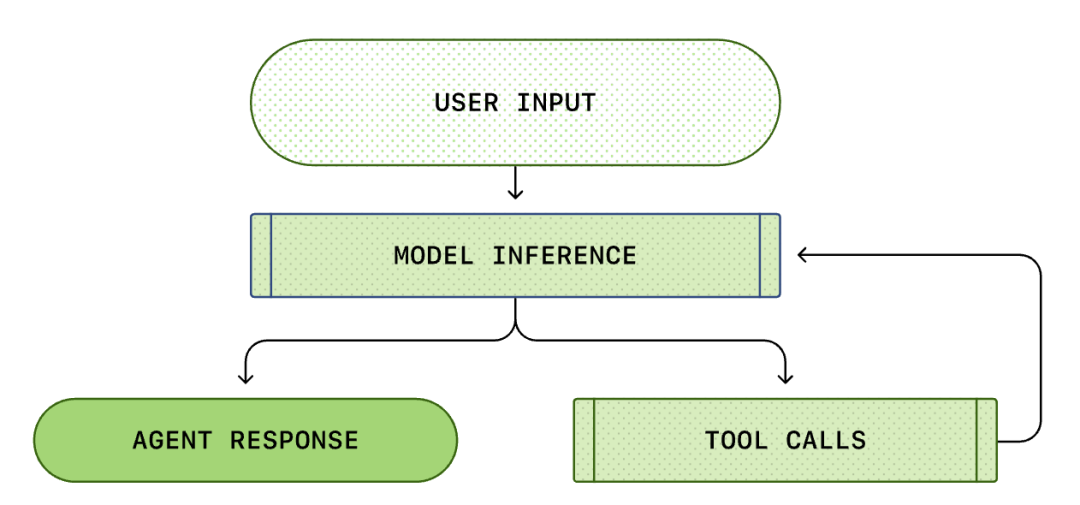
ჩვენ, როგორც წესი, ვფიქრობთ, რომ AI პროგრამირება არის: „მე ვკითხულობ, ის პასუხობს“. მაგრამ Codex CLI-ის შიგნით, ეს არის რთული უსასრულო ციკლური პროცესი...
სტანდარტული Agent Loop მოიცავს შემდეგ ნაბიჯებს:
- მომხმარებლის ინსტრუქციები: მომხმარებლის მიერ შეყვანილი ტექსტური ინსტრუქციების ნაკრები (მაგალითად, „ამ ფუნქციის რეფაქტორინგი“).
- მოდელის დასკვნა: მოდელი წყვეტს, უპასუხოს პირდაპირ თუ გამოიძახოს ინსტრუმენტი (Tool Call).
- ინსტრუმენტის გამოძახება: თუ მოდელი გადაწყვეტს list files-ის ან run shell-ის გამოძახებას, CLI შეასრულებს ამ ბრძანებებს ლოკალურად.
- დაკვირვება (Observation): ინსტრუმენტის შესრულების შედეგები (კოდი, შეცდომები, ფაილების სია) აღირიცხება.
- ციკლი: ეს შედეგები ემატება საუბრის ისტორიას და კვლავ გადაეცემა მოდელს. შედეგის დანახვის შემდეგ, მოდელი წყვეტს შემდეგ ნაბიჯს.
- შეწყვეტა: სანამ მოდელი არ ჩათვლის, რომ დავალება დასრულებულია და არ გამოიტანს საბოლოო პასუხს.
მთელი პროცესი „მომხმარებლის შეყვანიდან“ „ინტელექტუალური აგენტის პასუხამდე“ ეწოდება საუბრის რაუნდს (Codex-ში მას უწოდებენ თემას).
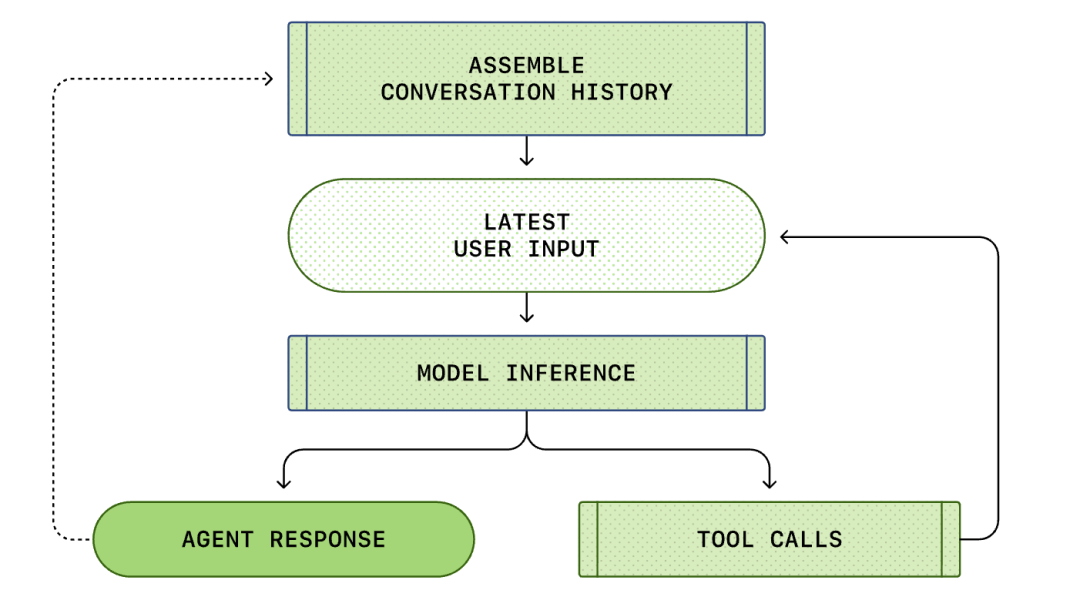
საუბრის მიმდინარეობისას, იზრდება მოთხოვნის სიგრძე (Prompt), რომელიც გამოიყენება მოდელის დასასკვნად. ეს სიგრძე მნიშვნელოვანია, რადგან თითოეულ მოდელს აქვს კონტექსტური ფანჯარა, რომელიც წარმოადგენს მაქსიმალურ რაოდენობას ტოკენებისა (tokens), რომელთა გამოყენებაც მოდელს შეუძლია დასკვნის გამოტანის ერთ გამოძახებაში.
მოდელის დასკვნა
Codex CLI უგზავნის HTTP მოთხოვნას Responses API-ს მოდელის დასასკვნად. Codex იყენებს Responses API-ს აგენტის ციკლის გასააქტიურებლად.
რა არის Responses API?
Responses API არის OpenAI-ის მიერ 2025 წლის მარტში გამოშვებული ინტელექტუალური აგენტის განვითარების ახალი თაობის ინტერფეისი, რომელიც მიზნად ისახავს გააერთიანოს საუბრის, ინსტრუმენტის გამოძახებისა და მრავალმხრივი დამუშავების შესაძლებლობები, რათა დეველოპერებს მიაწოდოს AI აპლიკაციების შექმნის უფრო მოქნილი და ძლიერი გამოცდილება.
Codex CLI-ის მიერ გამოყენებული Responses API-ის ბოლო წერტილი კონფიგურირებადია და მისი გამოყენება შესაძლებელია Responses API-ის ნებისმიერ ბოლო წერტილთან ერთად.
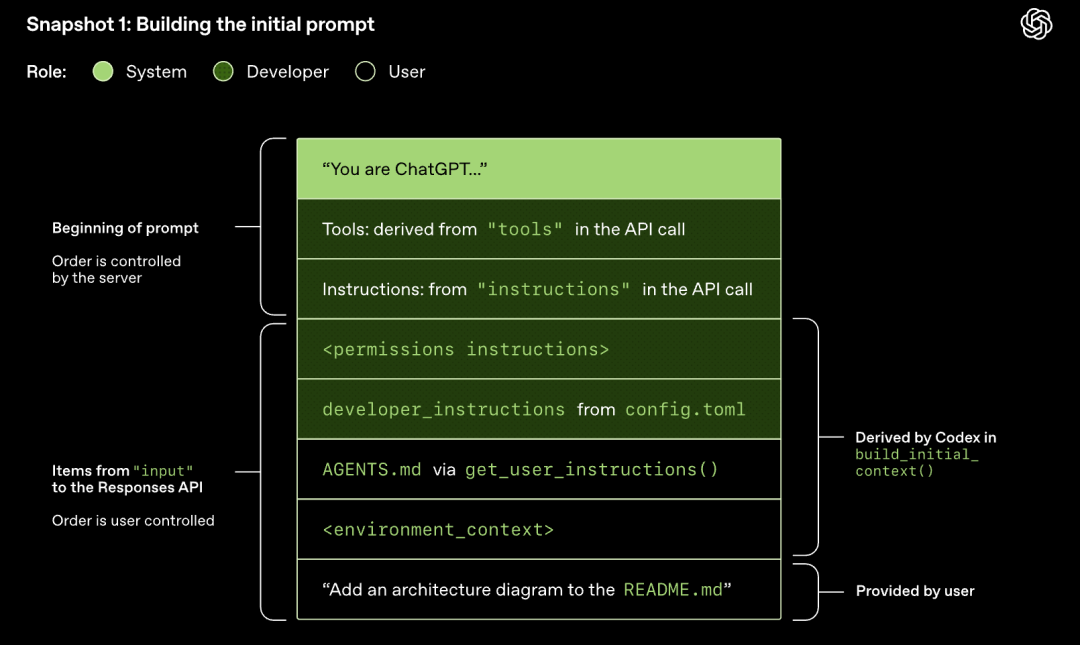
მოდელი ახორციელებს შერჩევას (ქმნის პასუხს)
Responses API-ში გაგზავნილი HTTP მოთხოვნა იწყებს Codex-ის საუბრის პირველ „რაუნდს“ (turn). სერვერი პასუხს აბრუნებს Server-Sent Events (SSE) ნაკადის საშუალებით.
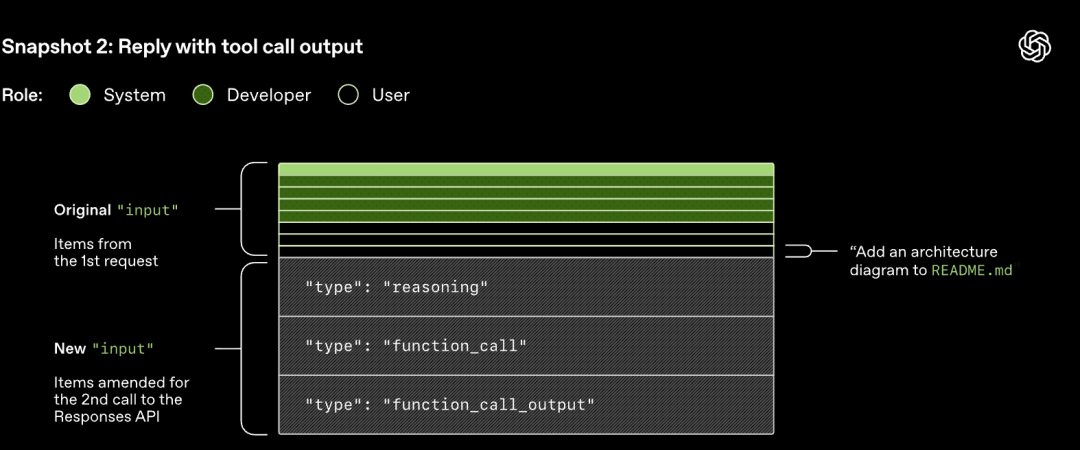
გაითვალისწინეთ, რომ წინა რაუნდის მოთხოვნა არის ახალი მოთხოვნის ზუსტი პრეფიქსი. ეს დიზაინი მნიშვნელოვნად აუმჯობესებს შემდგომი მოთხოვნების ეფექტურობას - შესაძლებელია მოთხოვნის ქეშირების მექანიზმის გამოყენება.

მოთხოვნის მუდმივი გახანგრძლივების გავლენა რაუნდების მატებასთან ერთად
1. შესრულების თვალსაზრისით
- მოდელის შერჩევის ღირებულების ზრდა: მოთხოვნის მუდმივი გახანგრძლივება გაზრდის მოდელის შერჩევის ღირებულებას, რადგან შერჩევის პროცესს მეტი მონაცემების დამუშავება სჭირდება, რაც იწვევს გამოთვლების მოცულობის ზრდას.
- ქეშირების ეფექტურობის შემცირება: მოთხოვნის რაუნდების მატებასთან ერთად მუდმივი გახანგრძლივების გამო, ზუსტი პრეფიქსის შესატყვისის სირთულე იზრდება და ქეშის მოხვედრის ალბათობა მცირდება.
2. კონტექსტური ფანჯრის მართვის თვალსაზრისით
- კონტექსტური ფანჯრის მარტივად ამოწურვა: მოთხოვნის მუდმივი გახანგრძლივება გამოიწვევს საუბარში ნიშნების რაოდენობის სწრაფ ზრდას და კონტექსტური ფანჯრის ზღვრის გადაჭარბების შემთხვევაში, შესაძლოა, კონტექსტური ფანჯარა ამოიწუროს.
- შეკუმშვის ოპერაციის აუცილებლობის ზრდა: კონტექსტური ფანჯრის ამოწურვის თავიდან ასაცილებლად, საჭიროა საუბრის შეკუმშვა, როდესაც ნიშნების რაოდენობა ზღვარს გადააჭარბებს.
3. ქეშში არ მოხვედრის რისკის თვალსაზრისით
- მრავალმა ოპერაციამ შეიძლება გამოიწვიოს ქეშში არ მოხვედრა: თუ მოთხოვნის გახანგრძლივებასთან დაკავშირებით ხდება მოდელისთვის ხელმისაწვდომი ინსტრუმენტების, სამიზნე მოდელის, სენდბოქსის კონფიგურაციის და ა.შ. შეცვლა, ეს კიდევ უფრო გაზრდის ქეშში არ მოხვედრის რისკს.
- MCP ინსტრუმენტები ზრდის სირთულეს: MCP სერვერს შეუძლია დინამიურად შეცვალოს მოწოდებული ინსტრუმენტების სია და შესაბამის შეტყობინებებზე რეაგირება ხანგრძლივი საუბრის დროს გამოიწვევს ქეშში არ მოხვედრას.
საინფორმაციო ცნობარი: „Unrolling the Codex agent loop“ წყარო: OpenAI



