Сакате да го разберете Codex агентот? Оваа длабинска анализа не смеете да ја пропуштите!
Сакате да го разберете Codex агентот? Оваа длабинска анализа не смеете да ја пропуштите!
OpenAI штотуку направи нешто „необично“.
Вообичаено, OpenAI објавува посилни модели (како o1), но овој пат, тие објавија длабински технички блог пост „Unrolling the Codex agent loop“, не само што го отворија изворниот код на основната логика на Codex CLI, туку и детално објаснија како функционира зрел код агент (Coding Agent).

Во време кога Claude Code и Cursor лудо собираат фанови, овој напис на OpenAI не е само покажување мускули, туку и „водич за избегнување грешки за архитекти на агенти“. Без разлика дали сакате добро да користите алатки за програмирање со вештачка интелигенција или сакате сами да развиете агент, овој напис вреди да се прочита збор по збор.
Целиот текст има 8300+ зборови, а читањето трае околу 20 минути.
Прво, што е Codex CLI?
Codex CLI е алатка за кодирање агент со отворен код од OpenAI, која може да се извршува на локален компјутер или да се инсталира во уредувач на код. Поддржува VS Code, Cursor, Windsurf и други.
Адреса на отворен код: https://github.com/openai/codex
А Agent Loop (агентска јамка) што ќе биде претставена овој пат е основната логика на Codex CLI: одговорна за координирање на корисниците, моделите и повиците на моделите, со цел да се извршат интеракции помеѓу вредни алатки.
Agent Loop (Јамка на интелигентен агент)
Моделите се само компоненти, а само агентите (Agent) можат да го сочинуваат производот.
Јадрото на секој AI Agent е таканаречената „јамка на интелигентен агент (Agent Loop)“. Дијаграмот на јамката на интелигентен агент е прикажан подолу:
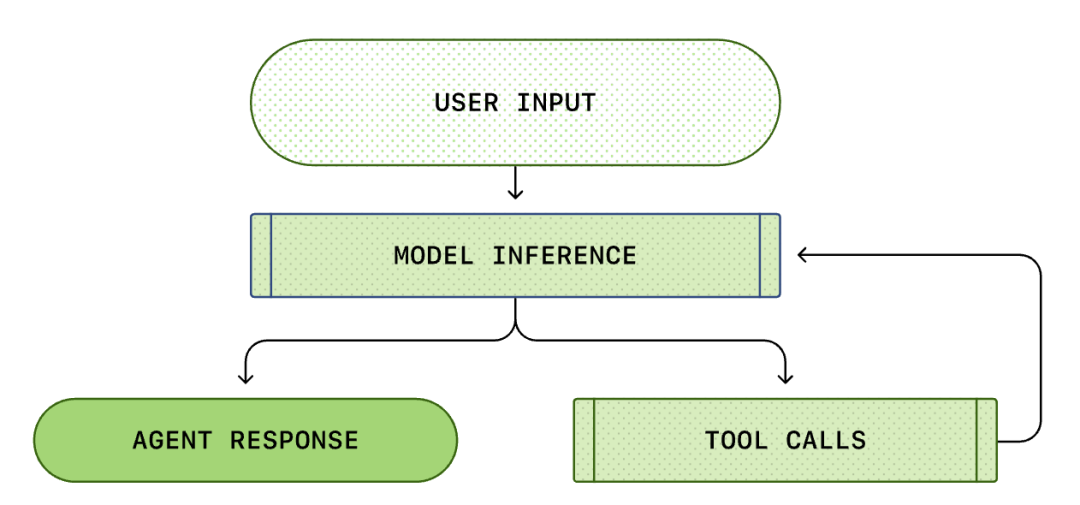
Обично мислиме дека програмирањето со вештачка интелигенција е: „Јас прашувам, тој одговара“. Но, во Codex CLI, ова е сложен процес на бесконечна јамка...
Стандардна Agent Loop ги вклучува следните чекори:
- Кориснички инструкции: Збир на текстуални инструкции внесени од корисникот (на пример, „рефакторирај ја оваа функција“).
- Моделско заклучување: Моделот одлучува дали директно да одговори или да повика алатка (Tool Call).
- Повик на алатка: Ако моделот одлучи да повика list files или run shell, CLI ќе ги изврши овие команди локално.
- Набљудување (Observation): Резултатите од извршувањето на алатката (код, грешки, список на датотеки) се заробени.
- Јамка: Овие резултати се додаваат во историјата на разговор и повторно се внесуваат во моделот. Откако ќе ги види резултатите, моделот одлучува за следниот чекор.
- Прекин: Сè додека моделот не смета дека задачата е завршена и не го даде конечниот одговор.
Целиот процес од „кориснички влез“ до „одговор на интелигентен агент“ се нарекува рунда на разговор (во Codex се нарекува нишка).
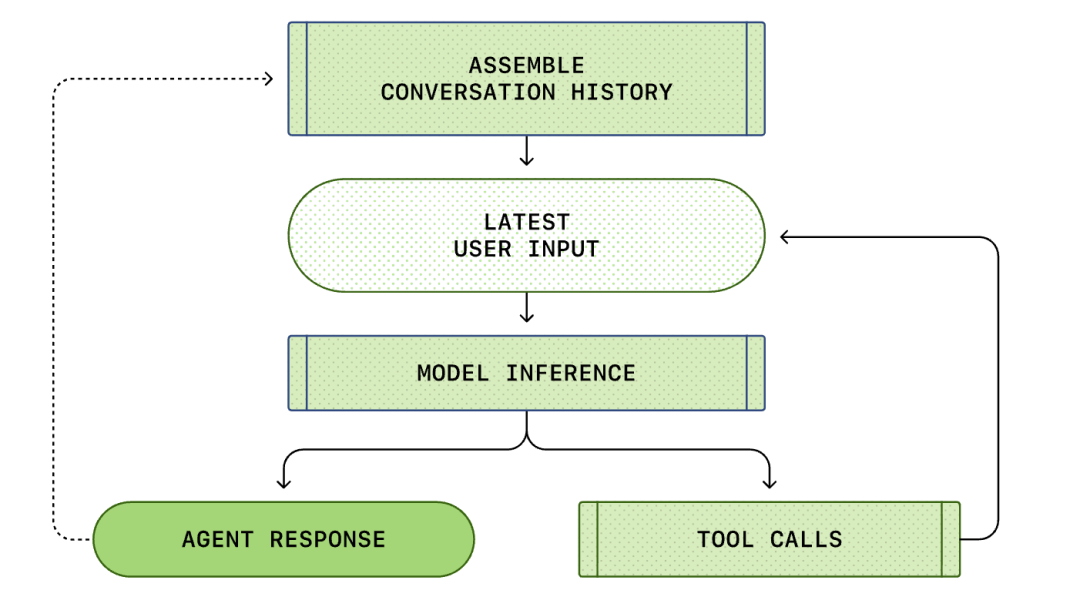
Како што напредува разговорот, должината на барањето (Prompt) што се користи за заклучување на моделот исто така ќе се зголемува. Оваа должина е важна бидејќи секој модел има контекстуален прозорец, кој го претставува максималниот број на токени што моделот може да ги користи во еден повик за заклучување.
Моделско заклучување
Codex CLI испраќа HTTP барање до Responses API за да изврши моделско заклучување. Codex го користи Responses API за да ја придвижи јамката на агентот.
Што е Responses API?
Responses API е нова генерација на интерфејс за развој на интелигентни агенти лансиран од OpenAI во март 2025 година, кој има за цел да ги обедини можностите за разговор, повици на алатки и мултимодално процесирање, за да им обезбеди на програмерите пофлексибилно и помоќно искуство за градење апликации со вештачка интелигенција.
Крајната точка на Responses API што ја користи Codex CLI може да се конфигурира и може да се користи со која било крајна точка што го имплементира Responses API.
Моделот зема примероци (генерира одговор)
HTTP барањето испратено до Responses API ќе ја започне првата „рунда“ во разговорот на Codex. Серверот ќе врати одговор преку Server-Sent Events (SSE).
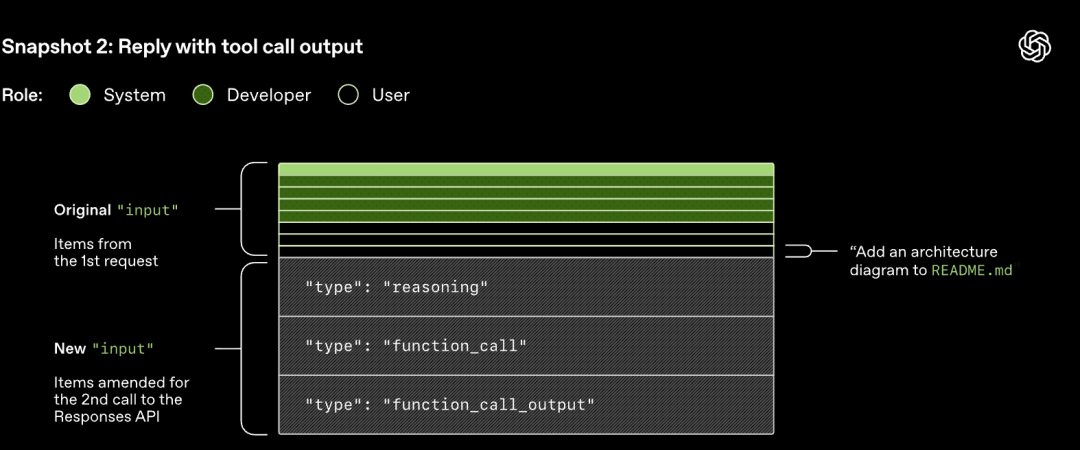
Забележете дека барањето од претходната рунда е прецизен префикс на новото барање. Овој дизајн може значително да ја подобри ефикасноста на последователните барања - може да се искористи механизмот за кеширање на барања.

Влијанието на постојаното продолжување на барањата со зголемување на рундите
1. Во однос на перформансите
- Зголемени трошоци за земање примероци од моделот: Постојаното продолжување на барањата ќе ги зголеми трошоците за земање примероци од моделот, бидејќи процесот на земање примероци треба да обработи повеќе податоци, што доведува до зголемување на пресметките.
- Намалена ефикасност на кеширање: Како што барањата постојано се продолжуваат со зголемување на рундите, тешкотијата за прецизно совпаѓање на префиксите се зголемува, а можноста за погодување на кешот се намалува.
2. Во однос на управувањето со контекстуалниот прозорец
- Контекстуалниот прозорец лесно се исцрпува: Постојаното продолжување на барањата ќе предизвика брзо зголемување на бројот на ознаки во разговорот, а штом ќе се надмине прагот на контекстуалниот прозорец, може да доведе до исцрпување на контекстуалниот прозорец.
- Зголемена потреба за операции за компресија: За да се избегне исцрпување на контекстуалниот прозорец, потребно е да се компресира разговорот кога бројот на ознаки ќе го надмине прагот.
3. Во однос на ризикот од промашување на кешот
- Различни операции лесно предизвикуваат промашување на кешот: Ако се вклучени операции како што се менување на достапните алатки на моделот, целниот модел, конфигурацијата на sandbox итн. поради продолжување на барањата, тоа дополнително ќе го зголеми ризикот од промашување на кешот.
- MCP алатките ја зголемуваат сложеноста: MCP серверот може динамички да ја менува листата на обезбедени алатки, а одговарањето на релевантните известувања во долги разговори може да доведе до промашување на кешот.
Информации за референца: „Unrolling the Codex agent loop“ Извор: OpenAI



