Codex इंटेलिजंट एजंट समजून घ्यायचा आहे? हे सखोल विश्लेषण चुकवू नका!
Codex इंटेलिजंट एजंट समजून घ्यायचा आहे? हे सखोल विश्लेषण चुकवू नका!
OpenAI ने नुकतेच एक 'असामान्य' काम केले आहे.
सामान्यतः, OpenAI अधिक शक्तिशाली मॉडेल (जसे की o1) जारी करते, परंतु यावेळी, त्यांनी एक सखोल तांत्रिक ब्लॉग 'Unrolling the Codex agent loop' प्रकाशित केला आहे. यात Codex CLI चा मूळ तर्कशास्त्र (core logic) ओपन सोर्स केला आहे, तसेच एक परिपक्व कोड इंटेलिजंट एजंट (Coding Agent) नेमके कसे कार्य करते हे सोप्या पद्धतीने स्पष्ट केले आहे.

Claude Code आणि Cursor च्या लोकप्रियतेच्या पार्श्वभूमीवर, OpenAI चा हा लेख केवळ त्यांची ताकद दर्शवत नाही, तर 'एजंट आर्किटेक्टसाठी धोके टाळण्याचे मार्गदर्शन' देखील आहे. तुम्हाला AI प्रोग्रामिंग साधनांचा प्रभावीपणे वापर करायचा असेल किंवा स्वतःचा एजंट विकसित करायचा असेल, तरीही हा लेख प्रत्येक शब्दाचा अभ्यास करण्यासारखा आहे.
संपूर्ण लेख 8300+ शब्दांचा आहे, वाचायला सुमारे 20 मिनिटे लागतील.
सर्वप्रथम, Codex CLI म्हणजे काय?
Codex CLI हे OpenAI ने तयार केलेले एक ओपन-सोर्स कोडिंग एजंट टूल आहे. हे तुमच्या लोकल कॉम्प्युटरवर किंवा कोड एडिटरमध्ये इंस्टॉल करता येते. हे VS Code, Cursor, Windsurf इत्यादींना सपोर्ट करते.
ओपन सोर्स ॲड्रेस: https://github.com/openai/codex
आणि आज आपण ज्या Agent Loop (एजंट लूप) बद्दल बोलणार आहोत, ते Codex CLI चे मुख्य तर्कशास्त्र आहे: वापरकर्ता, मॉडेल आणि मॉडेल कॉल्स यांच्यात समन्वय साधून उपयुक्त साधनांचे इंटरॅक्शन (interation) करणे.
Agent Loop (इंटेलिजंट एजंट लूप)
मॉडेल हे फक्त घटक आहेत, एजंटमुळेच उत्पादन तयार होते.
प्रत्येक AI एजंटच्या केंद्रस्थानी 'इंटेलिजंट एजंट लूप (Agent Loop)' असतो. इंटेलिजंट एजंट लूपचा आकृती खालीलप्रमाणे आहे:
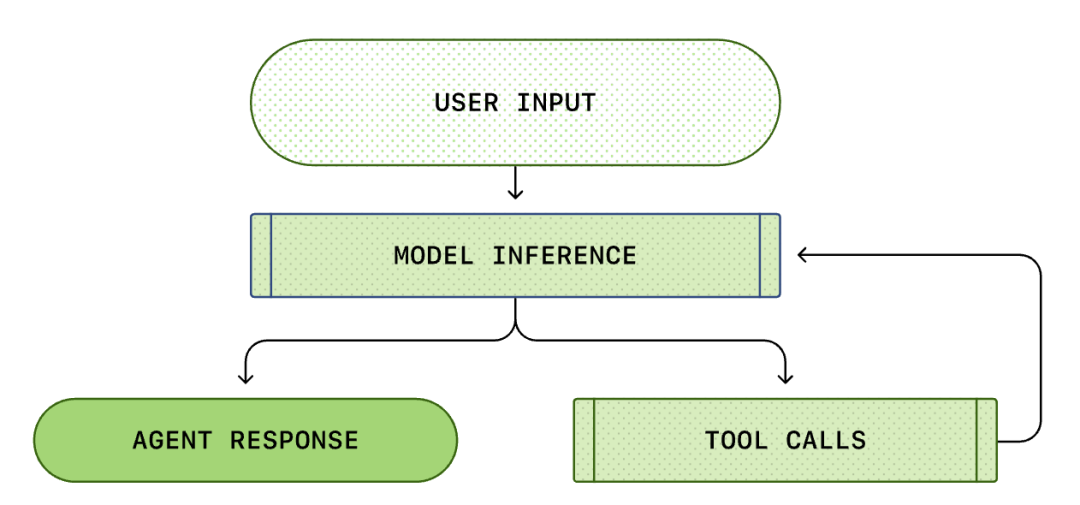
आपण सहसा विचार करतो की AI प्रोग्रामिंग म्हणजे: 'मी प्रश्न विचारतो आणि ते उत्तर देते'. पण Codex CLI मध्ये, ही एक गुंतागुंतीची आणि अनंत प्रक्रिया आहे...
एका स्टँडर्ड एजंट लूपमध्ये खालील टप्पे असतात:
- वापरकर्त्याचे निर्देश: वापरकर्त्याने दिलेले टेक्स्ट इन्स्ट्रक्शन (text instruction) (उदाहरणार्थ, 'या फंक्शनला रीस्ट्रक्चर करा').
- मॉडेल इन्फरन्स (Model Inference): मॉडेल ठरवते की थेट उत्तर द्यायचे आहे की टूल कॉल (Tool Call) करायचा आहे.
- टूल कॉल: जर मॉडेलने list files किंवा run shell कमांड्स (commands) वापरण्याचा निर्णय घेतला, तर CLI हे कमांड्स तुमच्या लोकल मशीनवर रन करते.
- ऑब्झर्व्हेशन (Observation): टूल एक्झिक्युट (execute) केल्यानंतर मिळणारे परिणाम (कोड, एरर, फाइल लिस्ट) कॅप्चर (capture) केले जातात.
- लूप: हे परिणाम संभाषण इतिहासात जोडले जातात आणि पुन्हा मॉडेलला दिले जातात. निकाल पाहिल्यानंतर, मॉडेल पुढील ॲक्शन (action) ठरवते.
- समाप्ती: मॉडेलला कार्य पूर्ण झाले आहे असे वाटेपर्यंत, अंतिम उत्तर दिले जाते.
'वापरकर्त्याच्या इनपुट' पासून 'एजंटच्या रिस्पॉन्स' पर्यंतच्या संपूर्ण प्रक्रियेला संभाषणाची एक फेरी म्हणतात (Codex मध्ये याला थ्रेड म्हणतात).
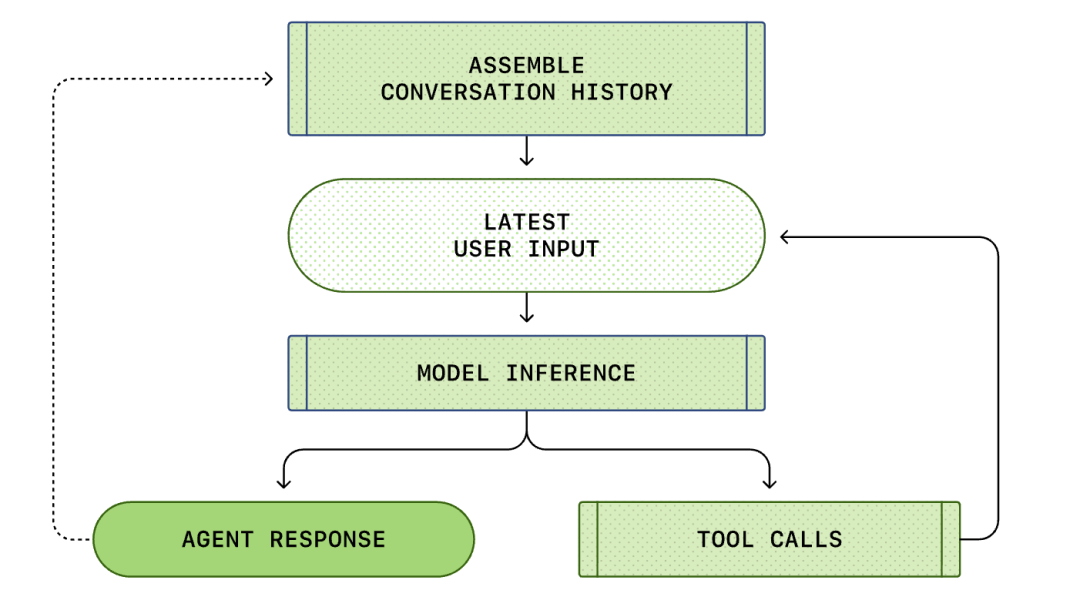
संभाषण जसजसे पुढे सरकते, मॉडेलला इन्फरन्स (Inference) देण्यासाठी वापरल्या जाणाऱ्या प्रॉम्प्टची (Prompt) लांबी देखील वाढते. ही लांबी खूप महत्त्वाची आहे, कारण प्रत्येक मॉडेलची एक संदर्भ विंडो (context window) असते, जी मॉडेल एका इन्फरन्स कॉलमध्ये (inference call) वापरू शकणाऱ्या टोकनची (tokens) कमाल संख्या दर्शवते.
मॉडेल इन्फरन्स
Codex CLI मॉडेल इन्फरन्ससाठी Responses API ला HTTP रिक्वेस्ट (request) पाठवते. Codex एजंट लूप चालवण्यासाठी Responses API वापरते.
Responses API म्हणजे काय?
Responses API हे OpenAI ने मार्च 2025 मध्ये लाँच केलेले नेक्स्ट जनरेशन इंटेलिजंट एजंट डेव्हलपमेंट इंटरफेस (next generation intelligent agent development interface) आहे. हे संभाषण, टूल कॉल्स आणि मल्टीमॉडल प्रोसेसिंग क्षमता एकत्रित करते आणि डेव्हलपर्सना (developers) अधिक लवचिक आणि शक्तिशाली AI ॲप्लिकेशन (application) तयार करण्याचा अनुभव देते.
Codex CLI द्वारे वापरले जाणारे Responses API एंडपॉइंट (endpoint) कॉन्फिगर (configure) करता येते आणि Responses API लागू केलेल्या कोणत्याही एंडपॉइंटसोबत वापरले जाऊ शकते.
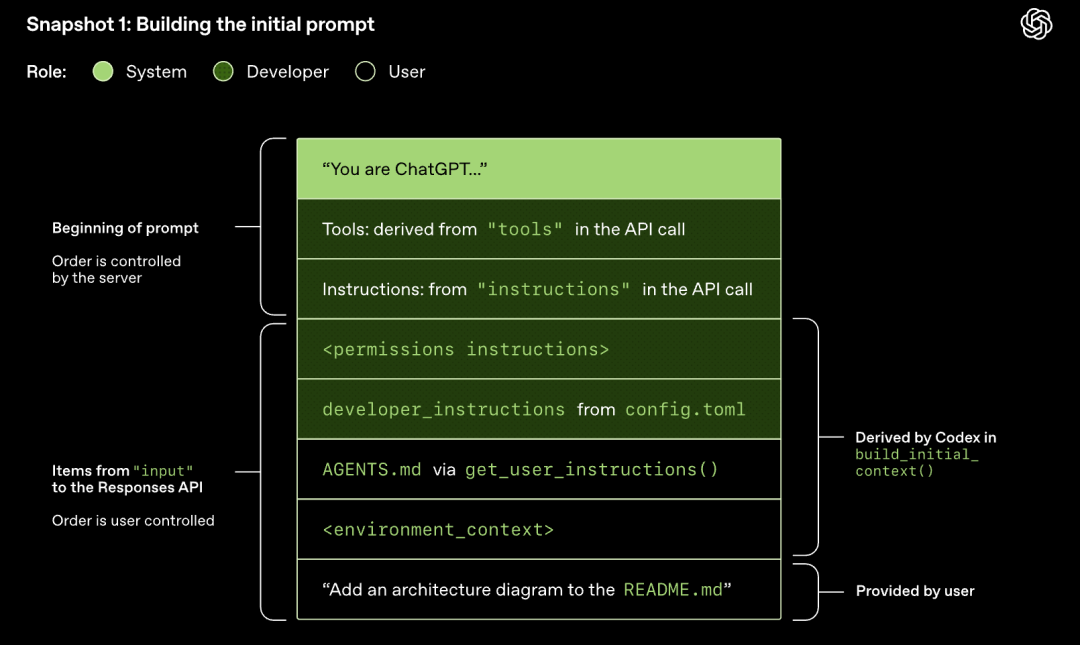
मॉडेल सॅम्पलिंग (Model Sampling) (रिस्पॉन्स जनरेट करणे)
Responses API ला पाठवलेली HTTP रिक्वेस्ट Codex संभाषणातील पहिली 'फेरी' सुरू करते. सर्व्हर Server-Sent Events (SSE) द्वारे रिस्पॉन्स स्ट्रीम (stream) करतो.
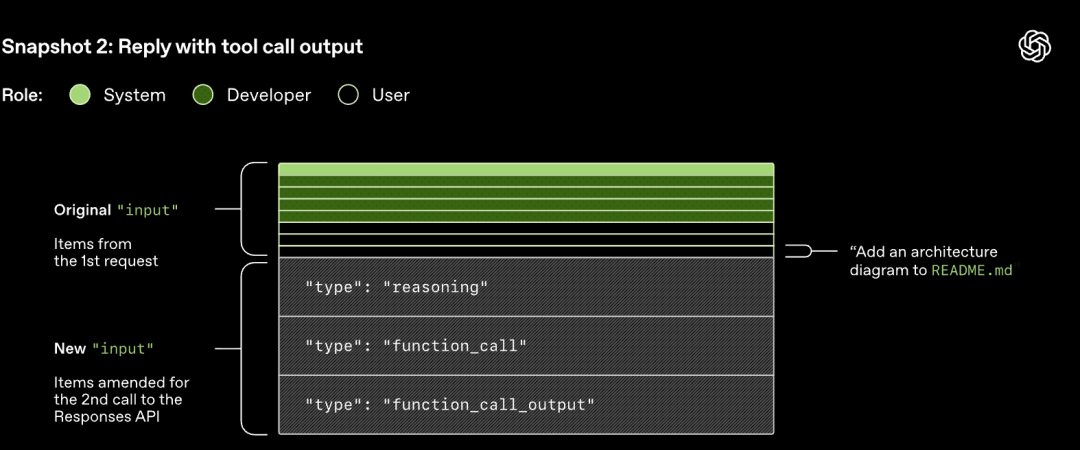
लक्षात घ्या, मागील फेरीतील प्रॉम्प्ट हा नवीन प्रॉम्प्टचा अचूक उपसर्ग (prefix) आहे. हे डिझाइन (design) पुढील रिक्वेस्टची (request) कार्यक्षमता लक्षणीयरीत्या सुधारते - प्रॉम्प्ट कॅशिंग मेकॅनिझमचा (prompt caching mechanism) वापर केला जाऊ शकतो.

फेऱ्या वाढल्याने प्रॉम्प्ट सतत वाढण्याचा परिणाम
1. कार्यक्षमतेच्या दृष्टीने
- मॉडेल सॅम्पलिंग खर्च वाढतो: प्रॉम्प्ट सतत वाढल्यामुळे, मॉडेल सॅम्पलिंगचा खर्च वाढतो, कारण सॅम्पलिंग प्रक्रियेस अधिक डेटा (data) प्रोसेस (process) करावा लागतो, ज्यामुळे गणनेचे प्रमाण वाढते.
- कॅश कार्यक्षमतेत घट: फेऱ्या वाढल्यामुळे प्रॉम्प्ट सतत वाढत असल्याने, अचूक प्रीफिक्स मॅचिंगची (prefix matching) शक्यता कमी होते आणि कॅश हिट होण्याची शक्यता कमी होते.
2. संदर्भ विंडो व्यवस्थापनाच्या दृष्टीने
- संदर्भ विंडो लवकर संपते: प्रॉम्प्ट सतत वाढल्यामुळे, संभाषणातील टोकनची संख्या झपाट्याने वाढते आणि संदर्भ विंडोची थ्रेशोल्ड (threshold) ओलांडल्यास, संदर्भ विंडो लवकर संपण्याची शक्यता असते.
- कॉम्प्रेशन (Compression) ऑपरेशनची आवश्यकता वाढते: संदर्भ विंडो संपणे टाळण्यासाठी, टोकनची संख्या थ्रेशोल्ड ओलांडल्यावर संभाषण कॉम्प्रेस (compress) करणे आवश्यक आहे.
3. कॅश मिस होण्याचा धोका
- अनेक ऑपरेशन्समुळे कॅश मिस होऊ शकतो: प्रॉम्प्ट वाढल्यामुळे मॉडेलसाठी उपलब्ध टूल्स, टारगेट मॉडेल (target model), सँडबॉक्स कॉन्फिगरेशन (sandbox configuration) इत्यादी बदलल्यास, कॅश मिस होण्याचा धोका वाढतो.
- MCP टूल्स गुंतागुंत वाढवतात: MCP सर्व्हर (server) पुरवलेल्या टूल्सची लिस्ट (list) गतिशीलपणे बदलू शकतो, ज्यामुळे दीर्घ संभाषणादरम्यान संबंधित सूचनांना प्रतिसाद दिल्याने कॅश मिस होऊ शकतो.
संदर्भ माहिती: 'Unrolling the Codex agent loop' स्त्रोत: OpenAI



