Ingin Memahami Agen Pintar Codex? Analisis Mendalam Ini Tidak Boleh Dilepaskan!
Ingin Memahami Agen Pintar Codex? Analisis Mendalam Ini Tidak Boleh Dilepaskan!
OpenAI baru sahaja melakukan sesuatu yang "luar biasa".
Biasanya, OpenAI akan mengeluarkan model yang lebih berkuasa (seperti o1), tetapi kali ini, mereka menerbitkan blog teknikal mendalam 《Unrolling the Codex agent loop》, bukan sahaja membuka sumber logik teras Codex CLI, tetapi juga membongkar langkah demi langkah bagaimana agen pengekodan (Coding Agent) yang matang berfungsi.

Pada masa Claude Code dan Cursor mendapat perhatian ramai, artikel OpenAI ini bukan sahaja mempamerkan kekuatan, tetapi juga merupakan "panduan mengelakkan kesilapan untuk arkitek Agen". Sama ada anda ingin menggunakan alat pengaturcaraan AI dengan baik, atau ingin membangunkan Agen sendiri, artikel ini patut dibaca dengan teliti.
Keseluruhan artikel mengandungi 8300+ perkataan, dan memerlukan kira-kira 20 minit untuk dibaca.
Pertama, Apakah Codex CLI?
Codex CLI ialah alat Agen pengekodan sumber terbuka yang dikeluarkan oleh OpenAI, yang boleh dijalankan pada komputer tempatan atau dipasang dalam editor kod. Menyokong VS Code, Cursor, Windsurf, dll.
Alamat sumber terbuka: https://github.com/openai/codex
Dan Agent Loop (Gelung Agen) yang akan diperkenalkan kali ini ialah logik teras Codex CLI: bertanggungjawab untuk menyelaraskan pengguna, model dan panggilan model, untuk melaksanakan interaksi antara alat yang berharga.
Agent Loop (Gelung Agen Pintar)
Model hanyalah komponen, Agen (Agen Pintar) boleh membentuk produk.
Teras setiap Agen AI ialah apa yang dipanggil "gelung agen pintar (Agent Loop)". Gambar rajah skematik gelung agen pintar adalah seperti berikut:
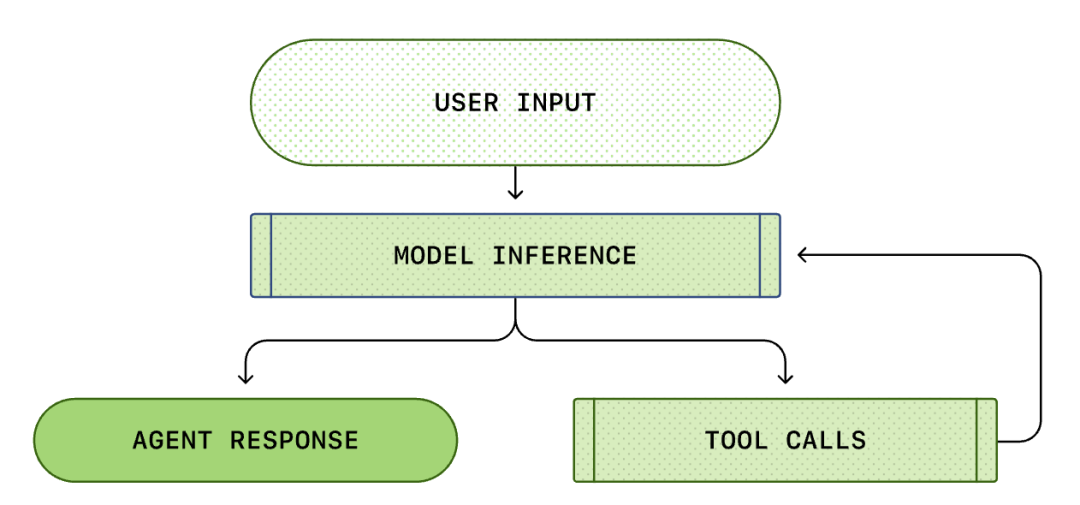
Kita biasanya berfikir bahawa pengaturcaraan AI ialah: "Saya bertanya, ia menjawab". Tetapi dalam Codex CLI, ini adalah proses gelung tak terhingga yang kompleks...
Gelung Agen standard mengandungi pautan berikut:
- Arahan Pengguna: Satu set arahan teks yang dimasukkan oleh pengguna (contohnya "susun semula fungsi ini").
- Inferens Model: Model menentukan sama ada untuk menjawab secara langsung, atau memanggil alat (Tool Call).
- Panggilan Alat: Jika model memutuskan untuk memanggil list files atau run shell, CLI akan melaksanakan arahan ini secara tempatan.
- Pemerhatian (Observation): Hasil pelaksanaan alat (kod, ralat, senarai fail) ditangkap.
- Gelung: Hasil ini ditambahkan pada sejarah perbualan dan disalurkan semula kepada model. Selepas melihat hasilnya, model memutuskan langkah seterusnya.
- Penamatan: Sehingga model menganggap tugas selesai, output respons akhir.
Keseluruhan proses daripada "input pengguna" kepada "respons agen pintar" dipanggil pusingan perbualan (dipanggil thread dalam Codex).
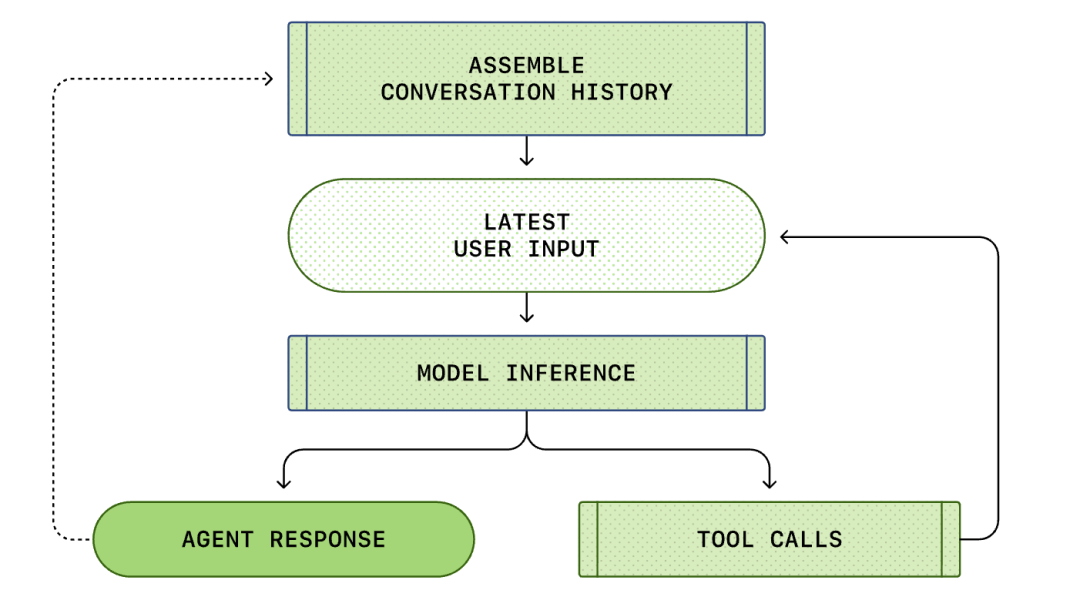
Apabila perbualan berlangsung, panjang gesaan (Prompt) yang digunakan untuk membuat inferens model juga akan meningkat. Panjang ini penting, kerana setiap model mempunyai tetingkap konteks, yang mewakili bilangan token maksimum yang boleh digunakan oleh model dalam satu panggilan inferens.
Inferens Model
Codex CLI menghantar permintaan HTTP ke Responses API untuk inferens model. Codex menggunakan Responses API untuk memacu gelung agen.
Apakah Responses API?
Responses API ialah antara muka pembangunan agen pintar generasi baharu yang dilancarkan oleh OpenAI pada Mac 2025, yang bertujuan untuk menyatukan perbualan, panggilan alat dan keupayaan pemprosesan berbilang mod, dan menyediakan pembangun dengan pengalaman membina aplikasi AI yang lebih fleksibel dan berkuasa.
Titik akhir Responses API yang digunakan oleh Codex CLI boleh dikonfigurasikan dan boleh digunakan dengan mana-mana titik akhir yang melaksanakan Responses API.
Model Membuat Pensampelan (Menjana Respons)
Permintaan HTTP yang dimulakan ke Responses API akan memulakan "pusingan" pertama dalam perbualan Codex. Pelayan akan mengembalikan respons secara strim melalui Server-Sent Events (SSE).
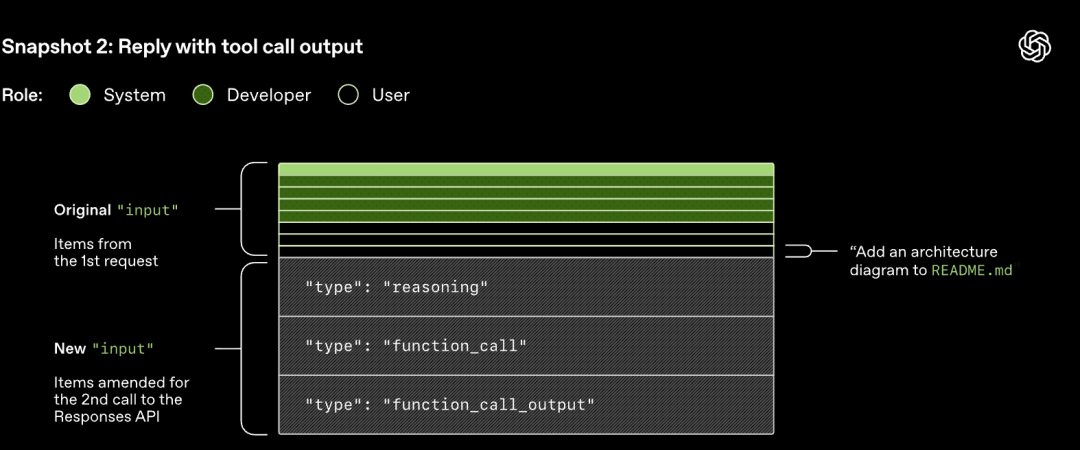
Perhatikan bahawa gesaan pusingan sebelumnya ialah awalan tepat gesaan baharu. Reka bentuk ini boleh meningkatkan kecekapan permintaan susulan dengan ketara - mekanisme cache gesaan boleh digunakan.

Kesan Gesaan yang Memanjang Apabila Pusingan Bertambah
1. Dari segi prestasi
- Peningkatan Kos Pensampelan Model: Gesaan yang berterusan memanjang akan meningkatkan kos pensampelan model, kerana proses pensampelan perlu memproses lebih banyak data, yang membawa kepada peningkatan dalam jumlah pengiraan.
- Pengurangan Faedah Cache: Apabila gesaan terus memanjang dengan peningkatan pusingan, kesukaran untuk padanan awalan yang tepat meningkat, dan kemungkinan cache dipukul berkurangan.
2. Dari segi pengurusan tetingkap konteks
- Tetingkap Konteks Mudah Habis: Gesaan yang berterusan memanjang akan menyebabkan bilangan token dalam perbualan meningkat dengan cepat, dan sebaik sahaja ambang tetingkap konteks melebihi, ia boleh menyebabkan tetingkap konteks habis.
- Peningkatan Keperluan Operasi Pemampatan: Untuk mengelakkan tetingkap konteks daripada habis, perbualan perlu dimampatkan apabila bilangan token melebihi ambang.
3. Dari segi risiko cache tidak dipukul
- Pelbagai Operasi Mudah Mencetuskan Cache Tidak Dipukul: Jika perubahan pada alat yang tersedia model, model sasaran, konfigurasi kotak pasir, dan operasi lain terlibat kerana gesaan dipanjangkan, risiko cache tidak dipukul akan meningkat lagi.
- Alat MCP Meningkatkan Kerumitan: Pelayan MCP boleh mengubah senarai alat yang disediakan secara dinamik, dan respons kepada pemberitahuan yang berkaitan dalam perbualan yang panjang boleh menyebabkan cache tidak dipukul.
Maklumat rujukan: 《Unrolling the Codex agent loop》Sumber: OpenAI



