Vil du forstå Codex-agenten? Denne dybdeanalysen er et must!
Vil du forstå Codex-agenten? Denne dybdeanalysen er et must!
OpenAI har nettopp gjort noe "uvanlig".
Vanligvis ville OpenAI publisere sterkere modeller (som o1), men denne gangen publiserte de et dyptgående teknisk blogginnlegg 《Unrolling the Codex agent loop》, og ikke bare åpnet kildekoden til Codex CLI sin kjerne-logikk, men de dissekerte også steg-for-steg hvordan en moden kode-agent (Coding Agent) faktisk fungerer.

I en tid hvor Claude Code og Cursor tiltrekker seg fans i et rasende tempo, er denne artikkelen fra OpenAI ikke bare en demonstrasjon av muskler, men også en "guide for arkitekter av Agent-arkitekturer for å unngå fallgruver". Enten du vil bruke AI-programmeringsverktøy på en god måte, eller du vil utvikle din egen Agent, er denne artikkelen verdt å studere ord for ord.
Hele artikkelen er over 8300 ord, og det tar omtrent 20 minutter å lese den.
Først, hva er Codex CLI?
Codex CLI er et åpen kildekode-kodingsagentverktøy fra OpenAI som kan kjøres på en lokal datamaskin eller installeres i en kodeeditor. Støtter VS Code, Cursor, Windsurf, etc.
Åpen kildekode-adresse: https://github.com/openai/codex
Agent Loop (agent-sløyfen), som skal introduseres her, er kjernelogikken til Codex CLI: den er ansvarlig for å koordinere brukeren, modellen og modellkall for å utføre interaksjoner mellom verdifulle verktøy.
Agent Loop (intelligens-agent-sløyfe)
Modeller er bare komponenter, agenter (intelligens-agenter) kan utgjøre et produkt.
Kjernen i hver AI-agent er den såkalte "intelligens-agent-sløyfen (Agent Loop)". Skjematisk fremstilling av intelligens-agent-sløyfen er som følger:
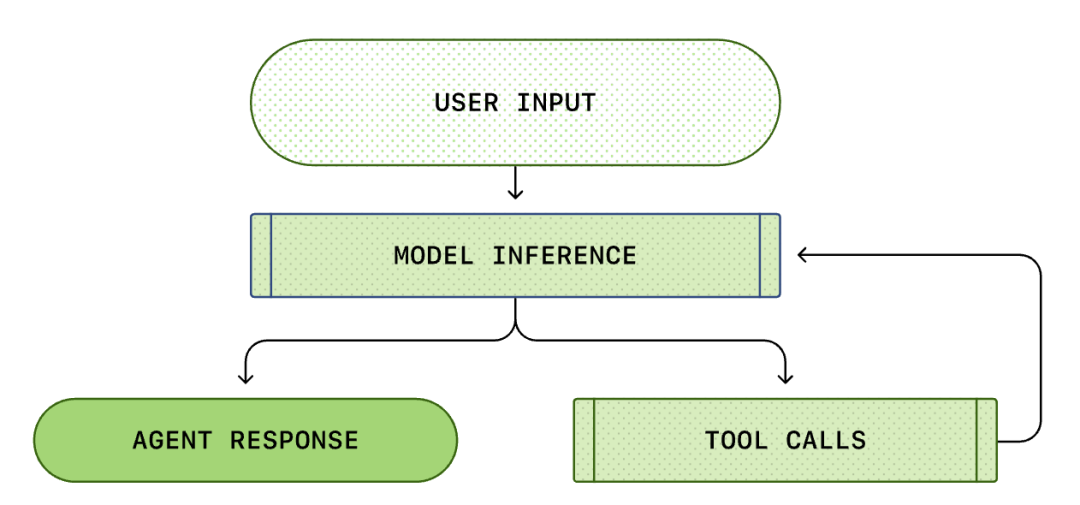
Vi tror vanligvis at AI-programmering er: "Jeg spør, den svarer". Men inne i Codex CLI er dette en kompleks, uendelig sløyfeprosess...
En standard Agent Loop inneholder følgende trinn:
- Brukerinstruksjoner: Et sett med tekstinstruksjoner som brukeren skriver inn (f.eks. "refaktorer denne funksjonen").
- Modellinferens: Modellen bestemmer om den skal svare direkte eller kalle et verktøy (Tool Call).
- Verktøykall: Hvis modellen bestemmer seg for å kalle list files eller run shell, vil CLI utføre disse kommandoene lokalt.
- Observasjon (Observation): Resultatene av verktøyutførelsen (kode, feil, filliste) fanges opp.
- Sløyfe: Disse resultatene legges til i dialoghistorikken og mates tilbake til modellen. Etter å ha sett resultatene, bestemmer modellen neste trinn.
- Avslutning: Inntil modellen mener at oppgaven er fullført, og skriver ut det endelige svaret.
Hele prosessen fra "brukerinndata" til "intelligens-agent-respons" kalles en runde av dialogen (kalt en tråd i Codex).
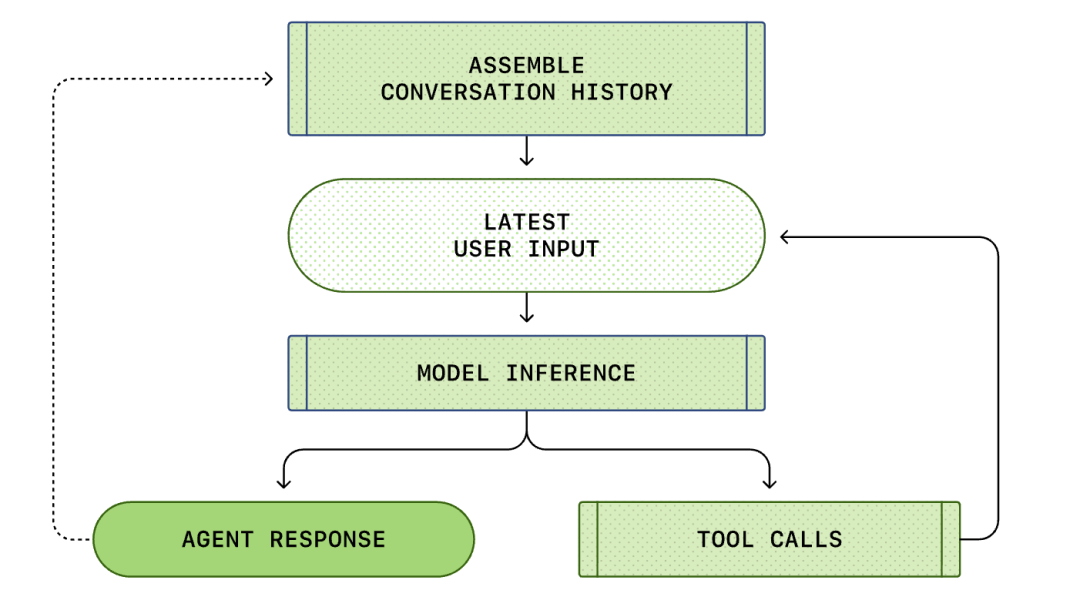
Etter hvert som dialogen skrider frem, vil lengden på ledeteksten (Prompt) som brukes til å resonnere modellen også øke. Denne lengden er viktig fordi hver modell har et kontekstvindu, som representerer det maksimale antallet tokens modellen kan bruke i ett resonnementkall.
Modellinferens
Codex CLI sender en HTTP-forespørsel til Responses API for modellinferens. Codex bruker Responses API til å drive agentsløyfen.
Hva er Responses API?
Responses API er en ny generasjons agentutviklingsgrensesnitt lansert av OpenAI i mars 2025, som har som mål å forene dialog, verktøykall og multimodal prosesseringsevne, og gi utviklere en mer fleksibel og kraftig AI-applikasjonsbyggeopplevelse.
Responses API-endepunktet som brukes av Codex CLI er konfigurerbart og kan brukes med alle endepunkter som implementerer Responses API.
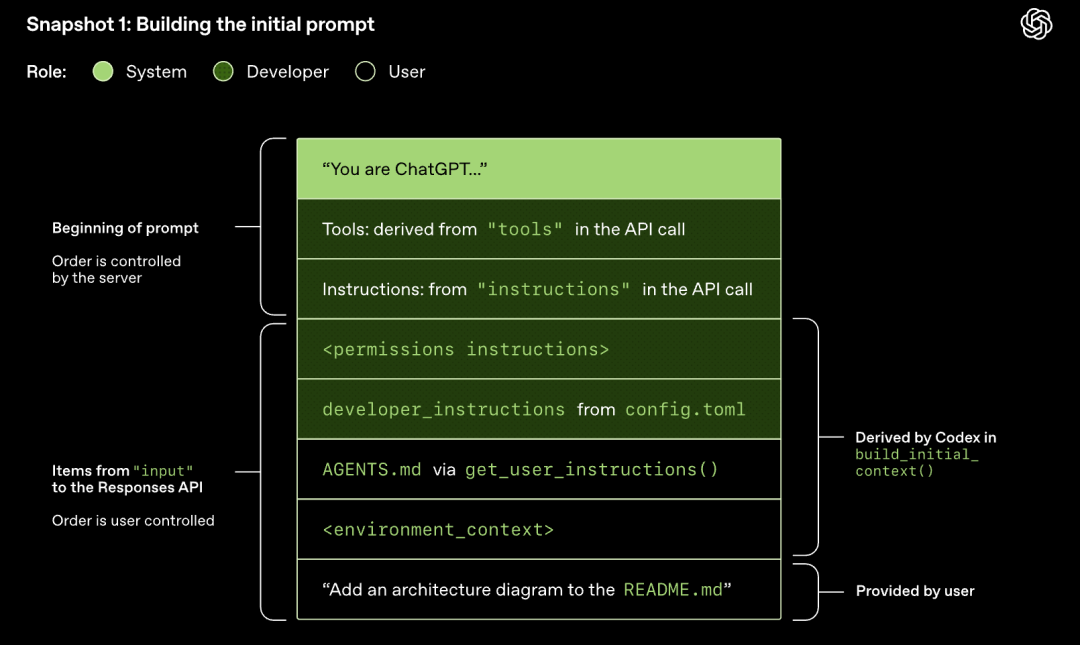
Modellen utfører sampling (genererer respons)
HTTP-forespørselen som sendes til Responses API starter den første "runden" i Codex-dialogen. Serveren vil streame responsen tilbake gjennom Server-Sent Events (SSE).
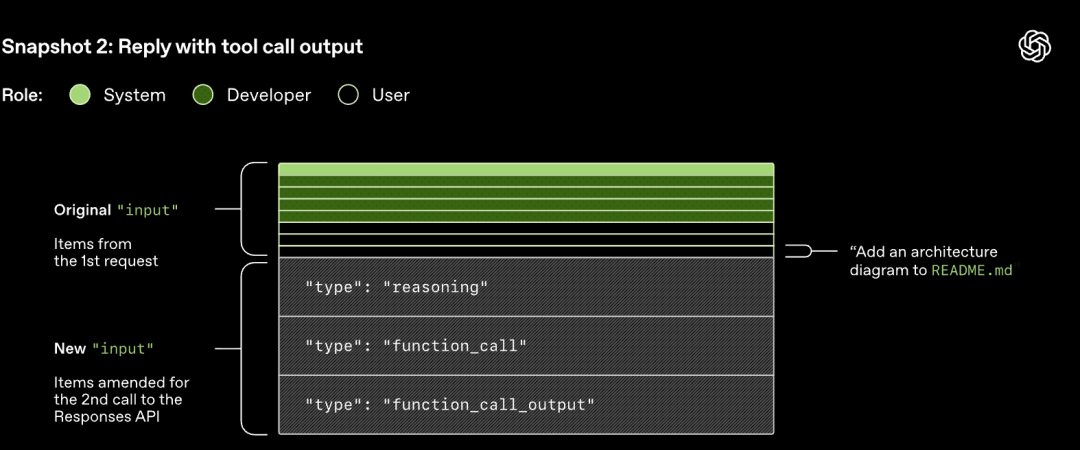
Vær oppmerksom på at ledeteksten fra forrige runde er et nøyaktig prefiks for den nye ledeteksten. Denne designen kan forbedre effektiviteten til påfølgende forespørsler betydelig – ledetekst-cachemekanismen kan brukes.

Effekten av at ledeteksten forlenges kontinuerlig med antall runder
1. Ytelsesmessig
- Økte kostnader for modellsampling: Den kontinuerlige forlengelsen av ledeteksten vil øke kostnadene for modellsampling, fordi samplingsprosessen krever behandling av mer data, noe som fører til en økning i beregningsmengden.
- Redusert cache-effekt: Etter hvert som ledeteksten forlenges kontinuerlig med antall runder, øker vanskeligheten med å matche nøyaktige prefikser, og sannsynligheten for cache-treff reduseres.
2. Kontekstvindusadministrasjonsmessig
- Kontekstvinduet er lett å tømme: Den kontinuerlige forlengelsen av ledeteksten vil føre til at antallet markeringer i dialogen øker raskt, og når terskelen for kontekstvinduet er overskredet, kan det føre til at kontekstvinduet tømmes.
- Økt nødvendighet av komprimering: For å unngå at kontekstvinduet tømmes, er det nødvendig å komprimere dialogen når antallet markeringer overskrider terskelen.
3. Cache-bom-risikomessig
- Flere operasjoner kan lett utløse cache-bom: Hvis endringer i modellens tilgjengelige verktøy, målmodell, sandbokskonfigurasjon og andre operasjoner er involvert på grunn av forlengelsen av ledeteksten, vil det ytterligere øke risikoen for cache-bom.
- MCP-verktøy øker kompleksiteten: MCP-serveren kan dynamisk endre listen over verktøy som tilbys, og respons på relevante varsler i lange samtaler kan føre til cache-bom.
Referanseinformasjon: 《Unrolling the Codex agent loop》Kilde: OpenAI



