Codex-agent begrijpen? Mis deze diepgaande analyse niet!
Codex-agent begrijpen? Mis deze diepgaande analyse niet!
OpenAI heeft zojuist iets 'ongebruikelijks' gedaan.
Normaal gesproken zou OpenAI sterkere modellen (zoals o1) uitbrengen, maar deze keer hebben ze een diepgaande technische blogpost gepubliceerd, 《Unrolling the Codex agent loop》. Ze hebben niet alleen de kernlogica van de Codex CLI open-source gemaakt, maar ook stap voor stap ontleed hoe een volwassen code-agent (Coding Agent) daadwerkelijk werkt.

In de huidige tijd, waarin Claude Code en Cursor razend populair zijn, is dit artikel van OpenAI niet alleen een spierballenvertoon, maar ook een 'gids om valkuilen te vermijden voor Agent-architecten'. Of je nu AI-programmeertools goed wilt gebruiken of zelf een Agent wilt ontwikkelen, dit artikel is de moeite waard om woord voor woord te bestuderen.
Het volledige artikel telt meer dan 8300 woorden en het lezen duurt ongeveer 20 minuten.
Ten eerste, wat is Codex CLI?
Codex CLI is een open-source coderingsagent-tool van OpenAI, die op een lokale computer kan worden uitgevoerd of in een code-editor kan worden geïnstalleerd. Het ondersteunt VS Code, Cursor, Windsurf, enz.
Open-source adres: https://github.com/openai/codex
De Agent Loop (agentlus) die in dit artikel wordt geïntroduceerd, is de kernlogica van de Codex CLI: het is verantwoordelijk voor het coördineren van gebruikers, modellen en modelaanroepen om interacties tussen waardevolle tools uit te voeren.
Agent Loop (intelligentie-agentlus)
Modellen zijn slechts componenten, alleen Agents (intelligentie-agenten) kunnen een product vormen.
De kern van elke AI Agent is de zogenaamde 'intelligentie-agentlus (Agent Loop)'. Het schematische diagram van de intelligentie-agentlus is als volgt:
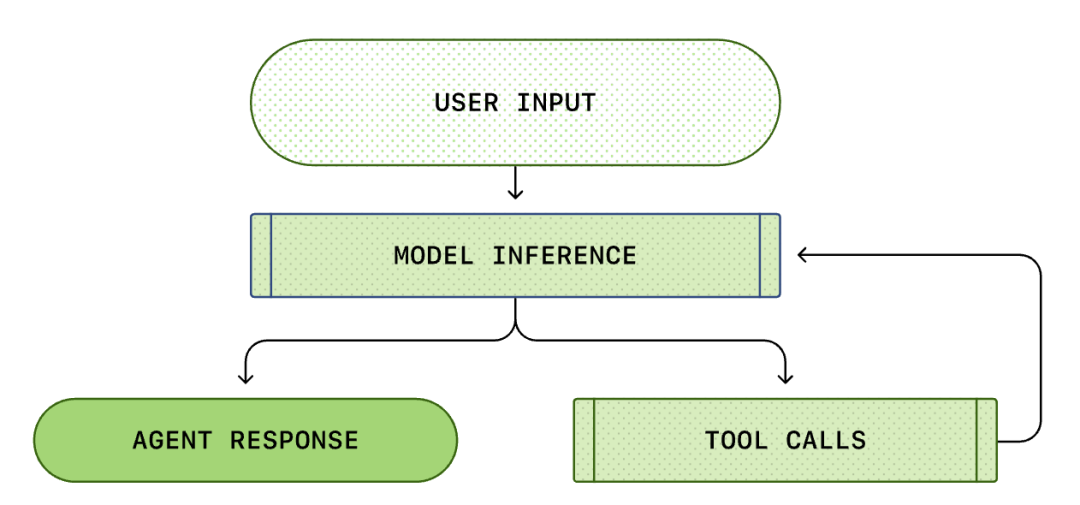
We denken meestal dat AI-programmeren is: 'Ik vraag, het antwoordt'. Maar binnen Codex CLI is dit een complex, oneindig lusproces...
Een standaard Agent Loop bevat de volgende stappen:
- Gebruikersinstructies: Een set tekstinstructies die door de gebruiker zijn ingevoerd (bijvoorbeeld 'herstructureer deze functie').
- Modelinferentie: Het model beslist of het direct antwoordt of een tool (Tool Call) aanroept.
- Toolaanroep: Als het model besluit om list files of run shell aan te roepen, voert de CLI deze opdrachten lokaal uit.
- Observatie (Observation): De resultaten van de tooluitvoering (code, fouten, bestandslijst) worden vastgelegd.
- Lus: Deze resultaten worden toegevoegd aan de dialooggeschiedenis en opnieuw aan het model gevoerd. Nadat het model de resultaten heeft gezien, beslist het over de volgende stap.
- Beëindiging: Totdat het model van mening is dat de taak is voltooid en het uiteindelijke antwoord uitvoert.
Het hele proces van 'gebruikersinvoer' tot 'intelligentie-agentrespons' wordt een ronde van de dialoog genoemd (in Codex een thread genoemd).
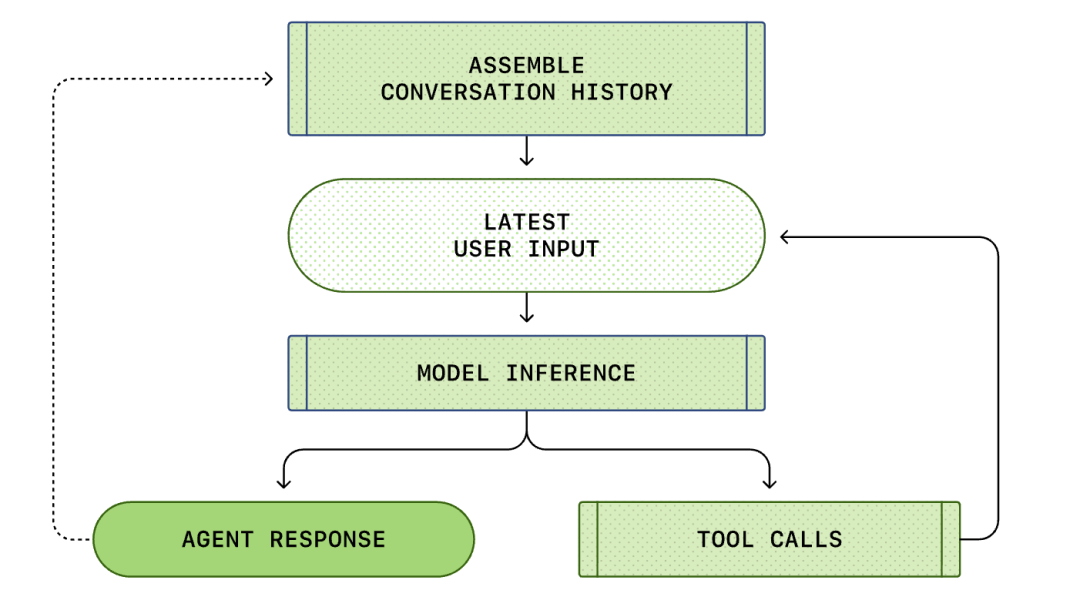
Naarmate de dialoog vordert, neemt ook de lengte toe van de prompt die wordt gebruikt om het model te redeneren. Deze lengte is belangrijk, omdat elk model een contextvenster heeft dat het maximale aantal tokens vertegenwoordigt dat het model kan gebruiken in één inferentie-aanroep.
Modelinferentie
Codex CLI verzendt HTTP-verzoeken naar de Responses API voor modelinferentie. Codex gebruikt de Responses API om de agentlus aan te sturen.
Wat is de Responses API?
De Responses API is een nieuwe generatie interface voor de ontwikkeling van intelligentie-agenten die OpenAI in maart 2025 heeft gelanceerd, met als doel dialoog, toolaanroepen en multimodale verwerkingsmogelijkheden te verenigen en ontwikkelaars een flexibelere en krachtigere ervaring te bieden bij het bouwen van AI-applicaties.
Het Responses API-eindpunt dat door Codex CLI wordt gebruikt, is configureerbaar en kan worden gebruikt met elk eindpunt dat de Responses API implementeert.
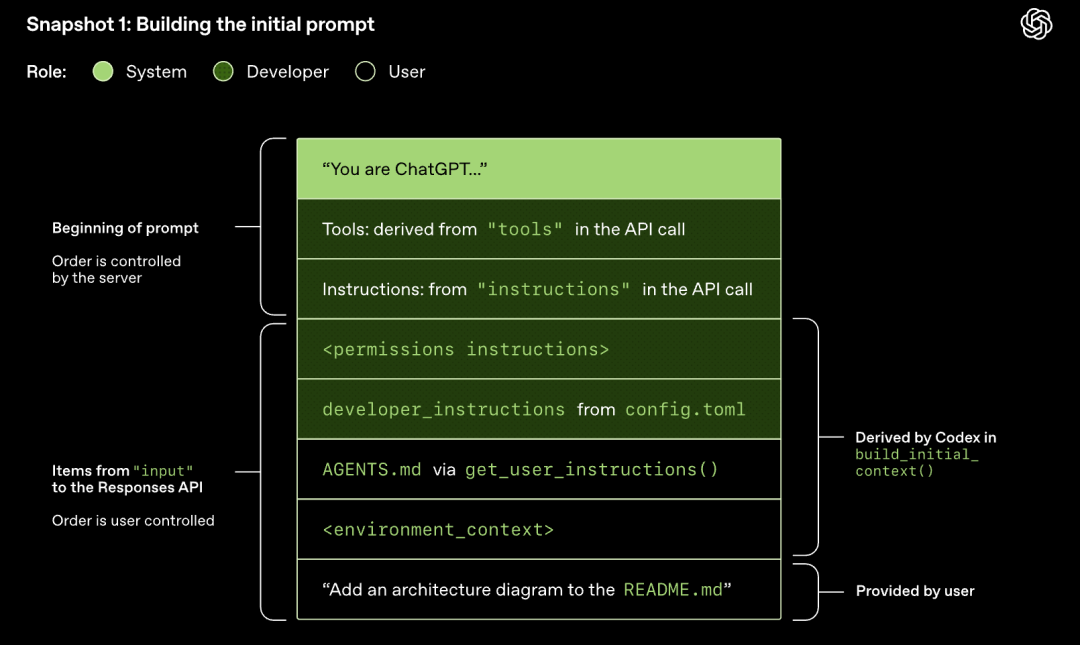
Model sampling (respons genereren)
Het HTTP-verzoek dat naar de Responses API wordt verzonden, start de eerste 'ronde' (turn) in de Codex-dialoog. De server retourneert de respons via Server-Sent Events (SSE) streaming.
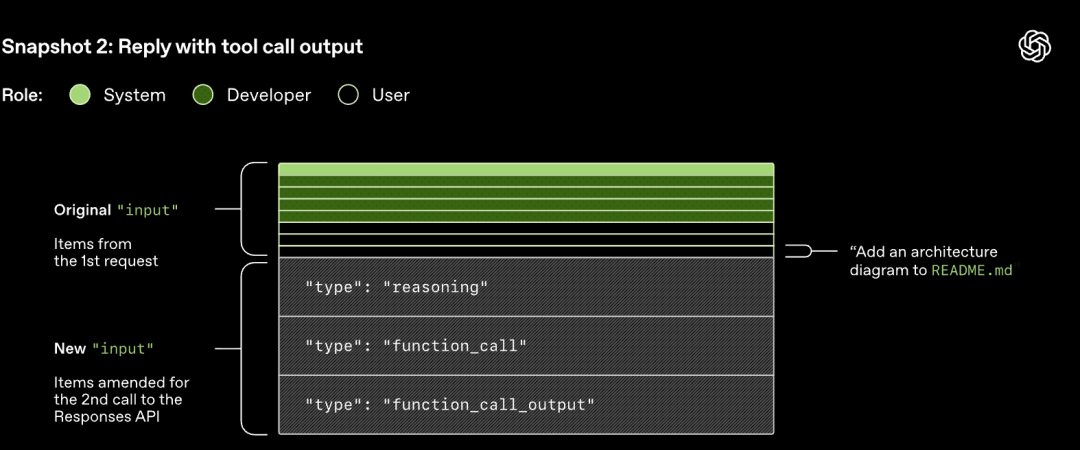
Let op: de prompt van de vorige ronde is het exacte voorvoegsel van de nieuwe prompt. Dit ontwerp kan de efficiëntie van latere verzoeken aanzienlijk verbeteren - het kan gebruikmaken van het prompt-cachingmechanisme.

De impact van de voortdurende verlenging van de prompt naarmate de rondes toenemen
1. Qua prestaties
- Verhoogde kosten voor model sampling: De voortdurende verlenging van de prompt zal de kosten voor model sampling verhogen, omdat het samplingproces meer gegevens moet verwerken, wat leidt tot een grotere rekenkracht.
- Verminderde cache-efficiëntie: Naarmate de prompt voortdurend langer wordt naarmate de rondes toenemen, neemt de moeilijkheidsgraad van het exact matchen van voorvoegsels toe, waardoor de kans op een cache-hit afneemt.
2. Qua contextvensterbeheer
- Contextvenster raakt gemakkelijk op: De voortdurende verlenging van de prompt zal ervoor zorgen dat het aantal tokens in de dialoog snel toeneemt. Zodra de drempel van het contextvenster wordt overschreden, kan dit leiden tot het opraken van het contextvenster.
- Noodzaak tot compressie neemt toe: Om te voorkomen dat het contextvenster opraakt, moet de dialoog worden gecomprimeerd wanneer het aantal tokens de drempel overschrijdt.
3. Qua risico op cache-miss
- Meerdere bewerkingen veroorzaken gemakkelijk een cache-miss: Als bewerkingen zoals het wijzigen van de beschikbare tools van het model, het doelmodel, de sandbox-configuratie, enz. betrokken zijn als gevolg van de verlenging van de prompt, zal dit het risico op een cache-miss verder vergroten.
- MCP-tools vergroten de complexiteit: De MCP-server kan de lijst met aangeboden tools dynamisch wijzigen. Het reageren op relevante meldingen in lange gesprekken kan leiden tot een cache-miss.
Referentie-informatie: 《Unrolling the Codex agent loop》Bron: OpenAI



