Chcesz zrozumieć agenta Codex? Nie możesz przegapić tej dogłębnej analizy!
Chcesz zrozumieć agenta Codex? Nie możesz przegapić tej dogłębnej analizy!
OpenAI właśnie zrobiło coś "nietypowego".
Zazwyczaj OpenAI publikuje mocniejsze modele (np. o1), ale tym razem opublikowali dogłębny blog techniczny "Unrolling the Codex agent loop", w którym nie tylko udostępnili kod źródłowy rdzenia Codex CLI, ale także krok po kroku rozłożyli na czynniki pierwsze, jak działa dojrzały agent kodowania (Coding Agent).

W obecnych czasach, gdy Claude Code i Cursor szaleją z popularnością, ten artykuł OpenAI to nie tylko pokaz siły, ale także "przewodnik unikania pułapek dla architektów agentów". Niezależnie od tego, czy chcesz dobrze wykorzystać narzędzia do programowania AI, czy chcesz samodzielnie opracować agenta, ten artykuł jest wart przestudiowania słowo po słowie.
Cały tekst ma ponad 8300 słów, a jego przeczytanie zajmie około 20 minut.
Po pierwsze, czym jest Codex CLI?
Codex CLI to narzędzie agenta kodowania open source firmy OpenAI, które można uruchomić na komputerze lokalnym lub zainstalować w edytorze kodu. Obsługuje VS Code, Cursor, Windsurf itp.
Adres open source: https://github.com/openai/codex
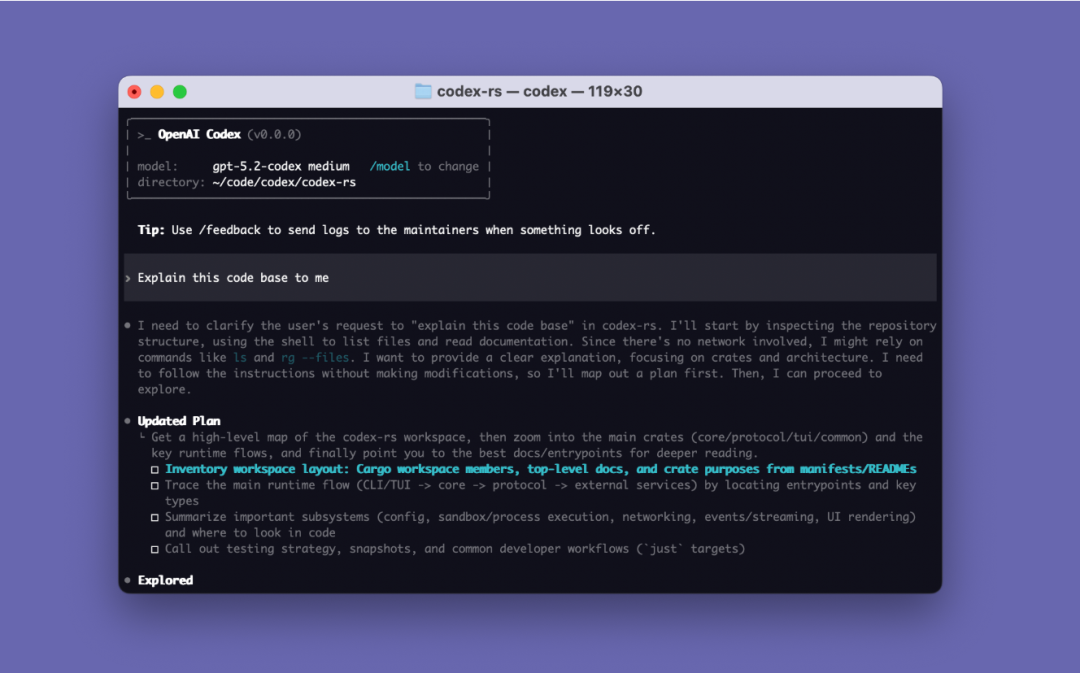
Agent Loop (pętla agenta), który zostanie przedstawiony, jest rdzeniem logiki Codex CLI: odpowiada za koordynację użytkownika, modelu i wywołań modelu w celu wykonywania interakcji między wartościowymi narzędziami.
Agent Loop (pętla inteligentnego agenta)
Model to tylko komponent, dopiero Agent (inteligentny agent) tworzy produkt.
Sercem każdego agenta AI jest tak zwana "pętla inteligentnego agenta (Agent Loop)". Schemat pętli inteligentnego agenta przedstawiono poniżej:
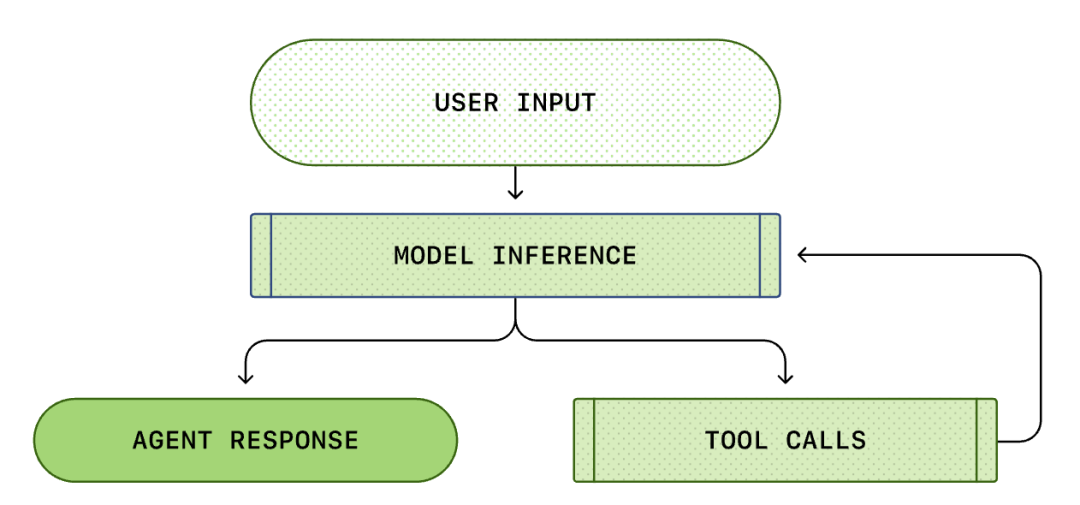
Zazwyczaj myślimy o programowaniu AI jako: "Pytam, on odpowiada". Ale wewnątrz Codex CLI jest to złożony, nieskończony proces pętli...
Standardowa pętla agenta (Agent Loop) obejmuje następujące etapy:
- Instrukcje użytkownika: Zestaw instrukcji tekstowych wprowadzonych przez użytkownika (np. "Przebuduj tę funkcję").
- Wnioskowanie modelu: Model decyduje, czy odpowiedzieć bezpośrednio, czy wywołać narzędzie (Tool Call).
- Wywołanie narzędzia: Jeśli model zdecyduje się wywołać list files lub run shell, CLI wykona te polecenia lokalnie.
- Obserwacja (Observation): Wyniki wykonania narzędzia (kod, błędy, lista plików) są przechwytywane.
- Pętla: Te wyniki są dodawane do historii konwersacji i ponownie przekazywane do modelu. Model, widząc wyniki, decyduje o następnym kroku.
- Zakończenie: Dopóki model nie uzna, że zadanie zostało zakończone i nie wygeneruje ostatecznej odpowiedzi.
Cały proces od "wprowadzenia użytkownika" do "odpowiedzi inteligentnego agenta" nazywany jest rundą konwersacji (w Codex nazywany wątkiem).
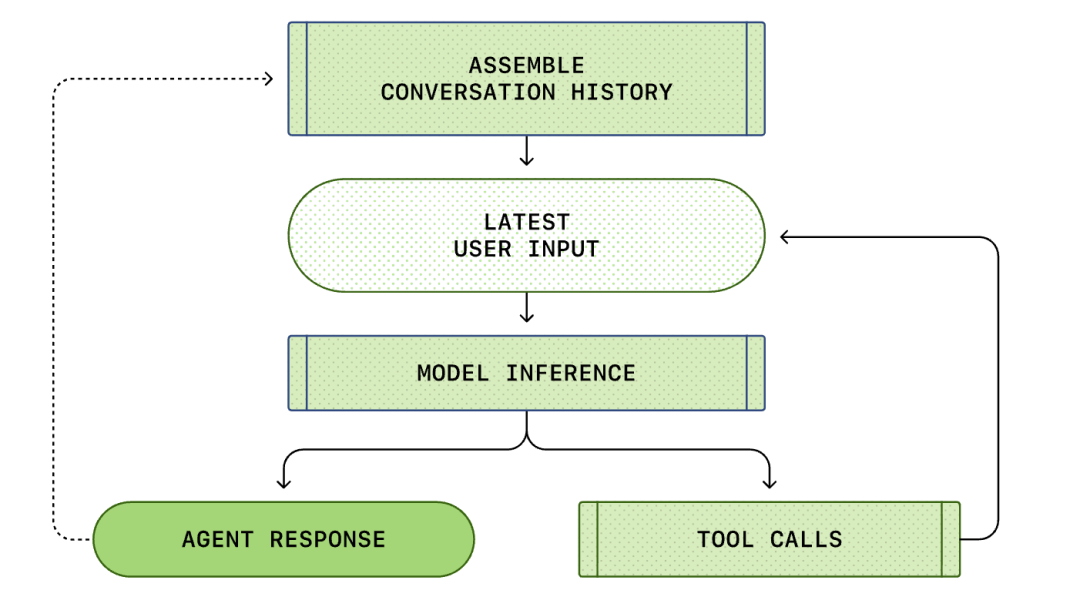
Wraz z postępem konwersacji zwiększa się również długość podpowiedzi (Prompt) używanej do wnioskowania modelu. Ta długość jest ważna, ponieważ każdy model ma okno kontekstowe, które reprezentuje maksymalną liczbę tokenów, które model może wykorzystać w jednym wywołaniu wnioskowania.
Wnioskowanie modelu
Codex CLI wysyła żądanie HTTP do Responses API w celu wnioskowania modelu. Codex używa Responses API do sterowania pętlą agenta.
Czym jest Responses API?
Responses API to interfejs programowania agentów nowej generacji wprowadzony przez OpenAI w marcu 2025 r., którego celem jest ujednolicenie konwersacji, wywołań narzędzi i możliwości przetwarzania multimodalnego, aby zapewnić programistom bardziej elastyczne i wydajne środowisko tworzenia aplikacji AI.
Punkt końcowy Responses API używany przez Codex CLI jest konfigurowalny i może być używany z dowolnym punktem końcowym, który implementuje Responses API.
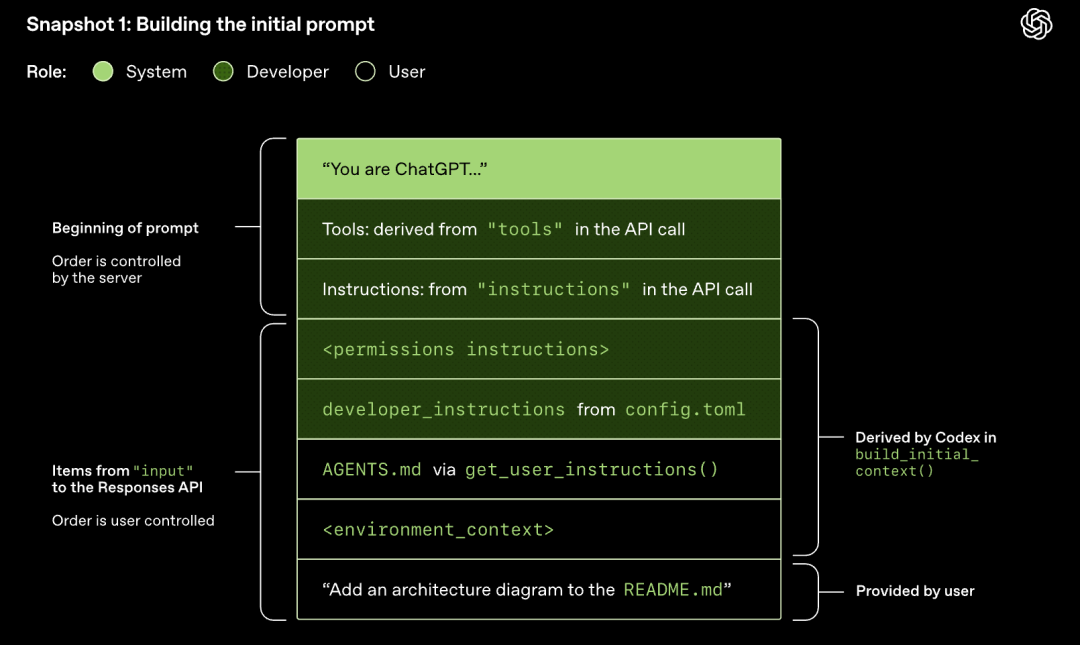
Model próbkuje (generuje odpowiedź)
Żądanie HTTP wysłane do Responses API uruchamia pierwszą "rundę" w konwersacji Codex. Serwer przesyła strumieniowo odpowiedź za pośrednictwem Server-Sent Events (SSE).
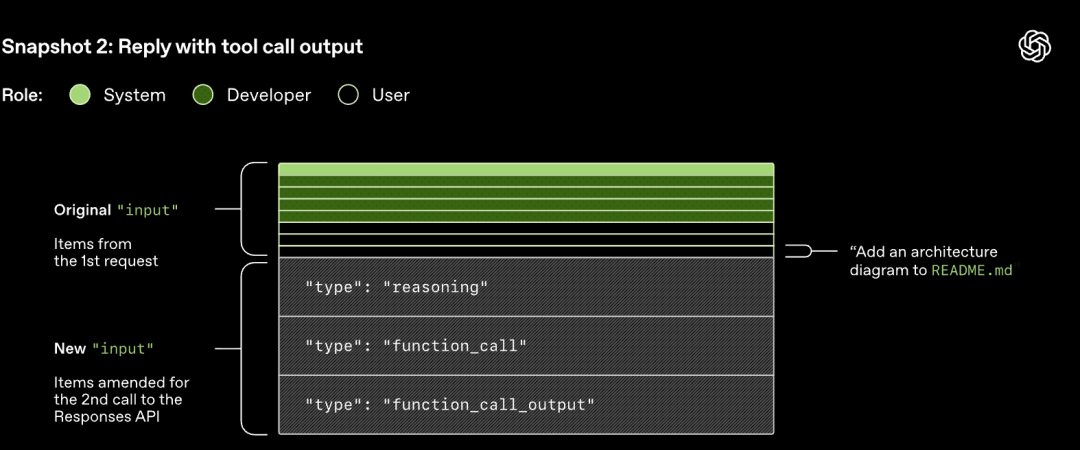
Zauważ, że podpowiedź z poprzedniej rundy jest dokładnym prefiksem nowej podpowiedzi. Takie podejście może znacznie poprawić wydajność kolejnych żądań – można wykorzystać mechanizm buforowania podpowiedzi.

Wpływ ciągłego wydłużania się podpowiedzi wraz z kolejnymi rundami
1. Aspekt wydajności
- Wzrost kosztów próbkowania modelu: Ciągłe wydłużanie się podpowiedzi spowoduje wzrost kosztów próbkowania modelu, ponieważ proces próbkowania wymaga przetwarzania większej ilości danych, co prowadzi do zwiększenia obciążenia obliczeniowego.
- Zmniejszenie efektywności buforowania: Wraz z ciągłym wydłużaniem się podpowiedzi wraz z kolejnymi rundami, trudność dopasowania dokładnego prefiksu wzrasta, a prawdopodobieństwo trafienia w pamięć podręczną maleje.
2. Aspekt zarządzania oknem kontekstowym
- Łatwe wyczerpanie okna kontekstowego: Ciągłe wydłużanie się podpowiedzi spowoduje szybki wzrost liczby tokenów w konwersacji, a po przekroczeniu progu okna kontekstowego może to doprowadzić do jego wyczerpania.
- Zwiększenie konieczności operacji kompresji: Aby uniknąć wyczerpania okna kontekstowego, konieczne jest skompresowanie konwersacji, gdy liczba tokenów przekroczy próg.
3. Aspekt ryzyka nietrafienia w pamięć podręczną
- Wiele operacji łatwo wywołuje nietrafienie w pamięć podręczną: Jeśli wydłużenie podpowiedzi wiąże się ze zmianą dostępnych narzędzi modelu, docelowego modelu, konfiguracji piaskownicy itp., dodatkowo zwiększy to ryzyko nietrafienia w pamięć podręczną.
- Narzędzie MCP zwiększa złożoność: Serwer MCP może dynamicznie zmieniać listę udostępnianych narzędzi, a reagowanie na powiązane powiadomienia w długotrwałych konwersacjach może prowadzić do nietrafienia w pamięć podręczną.
Informacje referencyjne: "Unrolling the Codex agent loop" Źródło: OpenAI



