Quer entender o agente inteligente Codex? Não perca esta análise aprofundada!
Quer entender o agente inteligente Codex? Não perca esta análise aprofundada!
A OpenAI acabou de fazer algo "incomum".
Normalmente, a OpenAI lançaria modelos mais poderosos (como o1), mas desta vez, eles publicaram um blog técnico aprofundado "Unrolling the Codex agent loop", não apenas abrindo o código da lógica central do Codex CLI, mas também desmontando passo a passo como um agente de código maduro (Coding Agent) realmente funciona.

No momento em que Claude Code e Cursor estão ganhando fãs freneticamente, este artigo da OpenAI não é apenas uma demonstração de força, mas também um "guia para evitar armadilhas para arquitetos de agentes". Se você quer usar bem as ferramentas de programação de IA ou quer desenvolver seu próprio agente, vale a pena estudar este artigo palavra por palavra.
O texto completo tem mais de 8300 palavras e leva cerca de 20 minutos para ler.
Primeiro, o que é o Codex CLI?
Codex CLI é uma ferramenta de agente de codificação de código aberto produzida pela OpenAI, que pode ser executada em um computador local ou instalada em um editor de código. Suporta VS Code, Cursor, Windsurf, etc.
Endereço de código aberto: https://github.com/openai/codex
O Agent Loop (ciclo do agente) a ser introduzido desta vez é a lógica central do Codex CLI: responsável por coordenar o usuário, o modelo e a chamada do modelo para executar interações valiosas entre as ferramentas.
Agent Loop (Ciclo do Agente Inteligente)
Os modelos são apenas componentes, os agentes (inteligentes) podem constituir um produto.
O núcleo de cada Agente de IA é o chamado "ciclo do agente (Agent Loop)". O diagrama esquemático do ciclo do agente é mostrado abaixo:
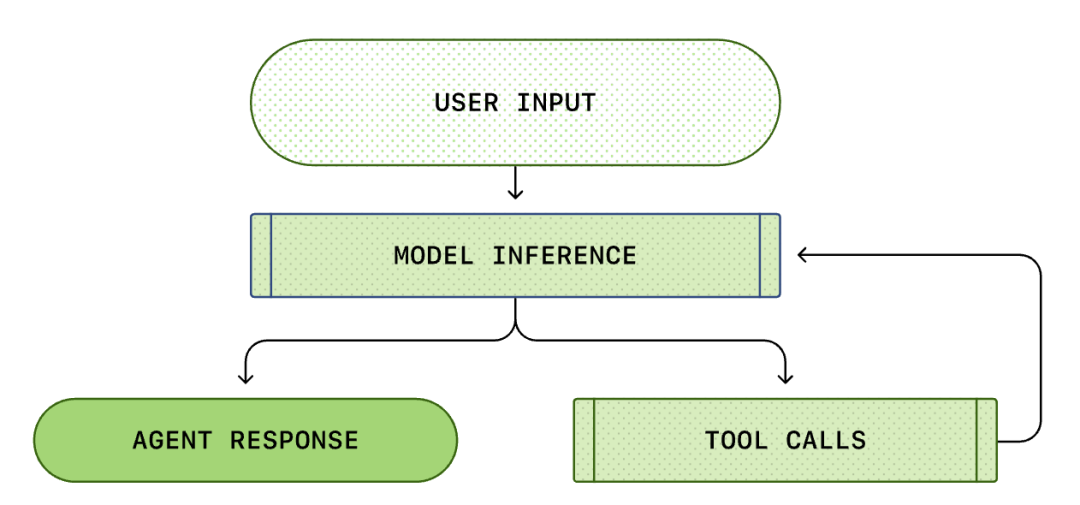
Normalmente pensamos que a programação de IA é: "Eu pergunto, ele responde". Mas dentro do Codex CLI, este é um processo complexo de loop infinito...
Um Agent Loop padrão inclui os seguintes links:
- Instruções do usuário: um conjunto de instruções de texto inseridas pelo usuário (por exemplo, "refatore esta função").
- Inferência do modelo: o modelo decide se responde diretamente ou chama uma ferramenta (Tool Call).
- Chamada de ferramenta: se o modelo decidir chamar list files ou run shell, o CLI executará esses comandos localmente.
- Observação (Observation): o resultado da execução da ferramenta (código, erro, lista de arquivos) é capturado.
- Ciclo: esses resultados são adicionados ao histórico de conversas e alimentados novamente ao modelo. Depois de ver os resultados, o modelo decide a próxima operação.
- Terminação: até que o modelo considere a tarefa concluída e produza a resposta final.
Todo o processo de "entrada do usuário" para "resposta do agente" é chamado de rodada de conversa (chamada de thread no Codex).
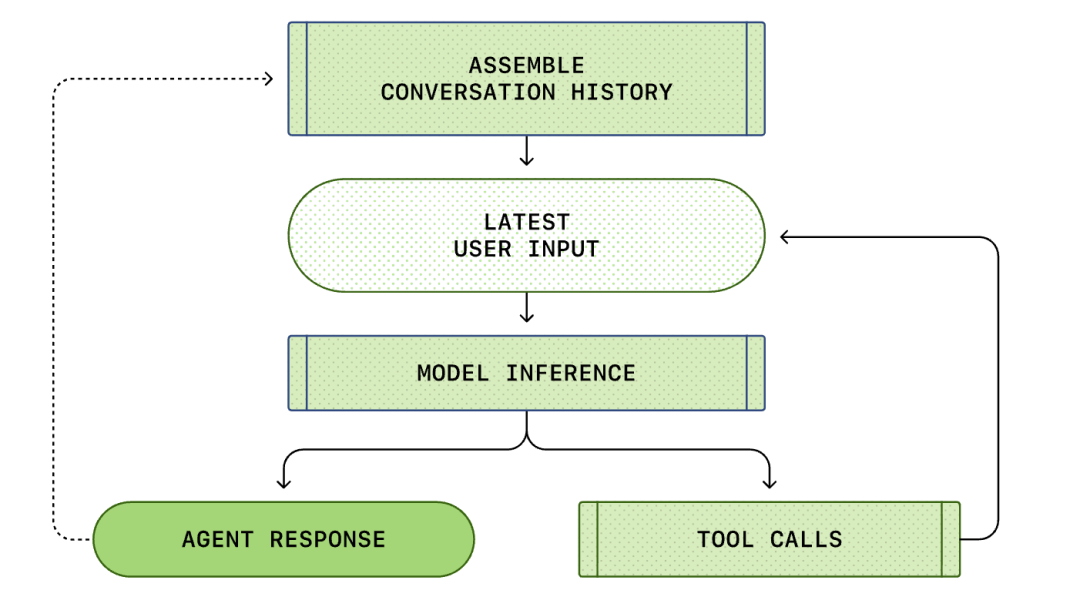
À medida que a conversa avança, o comprimento do prompt usado para inferir o modelo também aumenta. Este comprimento é importante porque cada modelo tem uma janela de contexto, que representa o número máximo de tokens que o modelo pode usar em uma única chamada de inferência.
Inferência do modelo
O Codex CLI envia uma solicitação HTTP para a API Responses para inferência do modelo. O Codex usa a API Responses para conduzir o ciclo do agente.
O que é a API Responses?
A API Responses é uma interface de desenvolvimento de agente de nova geração lançada pela OpenAI em março de 2025, com o objetivo de unificar as capacidades de conversação, chamada de ferramentas e processamento multimodal, e fornecer aos desenvolvedores uma experiência de construção de aplicativos de IA mais flexível e poderosa.
O endpoint da API Responses usado pelo Codex CLI é configurável e pode ser usado com qualquer endpoint que implemente a API Responses.
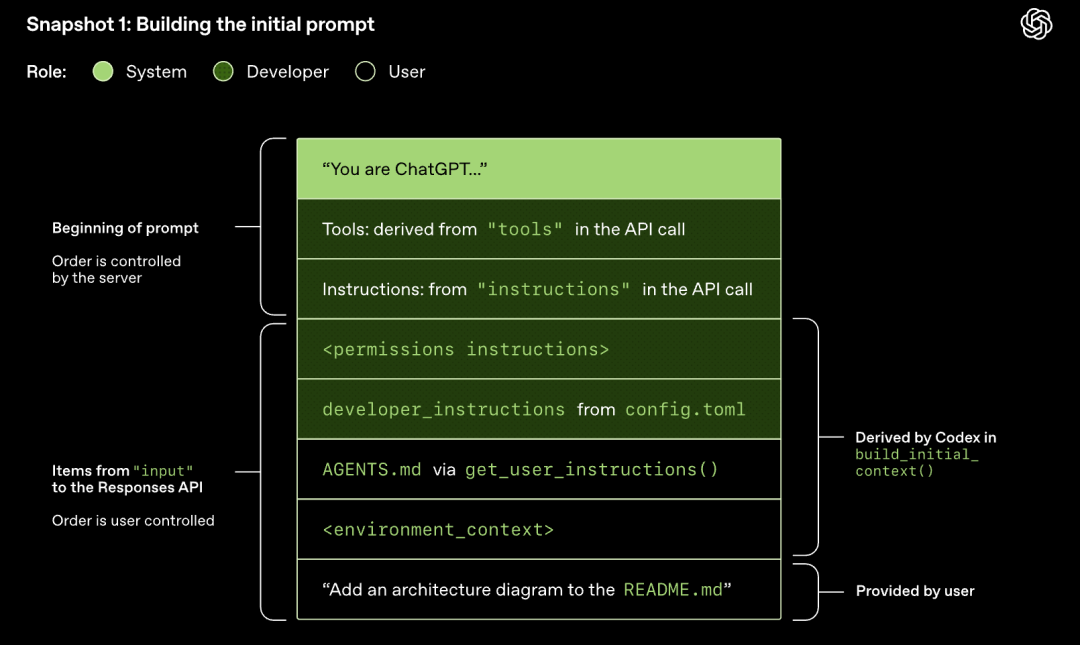
Modelo para amostragem (gerar resposta)
A solicitação HTTP iniciada para a API Responses inicia a primeira "rodada" (turn) na conversa do Codex. O servidor retorna a resposta em fluxo através de Server-Sent Events (SSE).
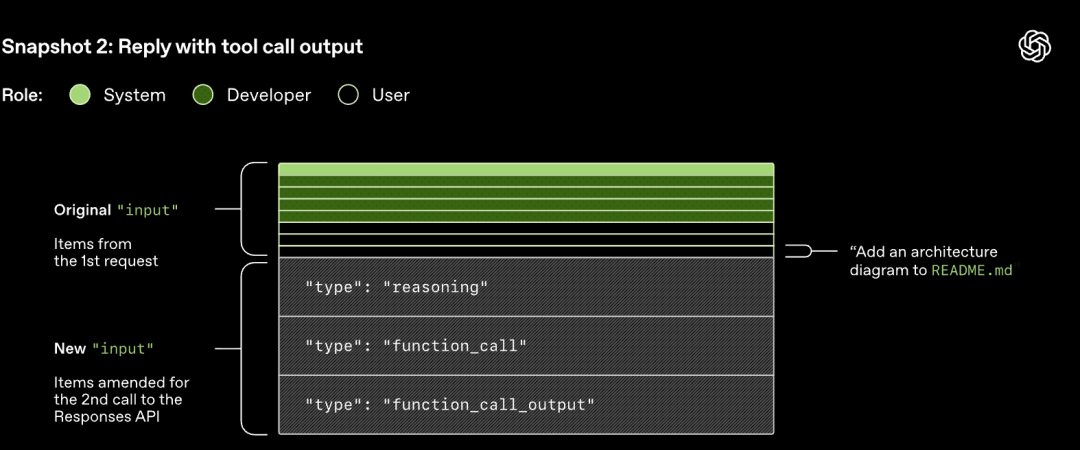
Observe que o prompt da rodada anterior é o prefixo exato do novo prompt. Este design pode melhorar significativamente a eficiência das solicitações subsequentes - o mecanismo de cache de prompt pode ser usado.

O impacto do aumento contínuo do prompt com o aumento das rodadas
1. Em termos de desempenho
- Aumento do custo de amostragem do modelo: o aumento contínuo do prompt aumentará o custo de amostragem do modelo, porque o processo de amostragem precisa processar mais dados, resultando em um aumento na quantidade de cálculo.
- Redução dos benefícios do cache: à medida que o prompt aumenta continuamente com o aumento das rodadas, a dificuldade de correspondência exata do prefixo aumenta e a probabilidade de acertos de cache diminui.
2. Em termos de gerenciamento da janela de contexto
- Janela de contexto fácil de esgotar: o aumento contínuo do prompt fará com que o número de tokens na conversa aumente rapidamente e, uma vez que o limite da janela de contexto seja excedido, poderá levar ao esgotamento da janela de contexto.
- Aumento da necessidade de operações de compressão: para evitar o esgotamento da janela de contexto, a conversa precisa ser comprimida quando o número de tokens exceder o limite.
3. Em termos de risco de falha de cache
- Várias operações podem facilmente causar falha de cache: se as operações como alterar as ferramentas disponíveis do modelo, o modelo de destino, a configuração da sandbox, etc., estiverem envolvidas devido ao aumento do prompt, o risco de falha de cache aumentará ainda mais.
- As ferramentas MCP aumentam a complexidade: o servidor MCP pode alterar dinamicamente a lista de ferramentas fornecidas e responder às notificações relevantes em conversas longas pode causar falha de cache.
Informações de referência: "Unrolling the Codex agent loop" Fonte: OpenAI



