Dëshironi të kuptoni agjentin inteligjent Codex? Kjo analizë e thellë nuk duhet humbur!
Dëshironi të kuptoni agjentin inteligjent Codex? Kjo analizë e thellë nuk duhet humbur!
OpenAI sapo bëri diçka "të pazakontë".
Zakonisht, OpenAI do të publikonte modele më të forta (si p.sh. o1), por këtë herë, ata publikuan një blog teknik të thellë "Unrolling the Codex agent loop", jo vetëm që hapën burimin e logjikës thelbësore të Codex CLI, por gjithashtu shpjeguan hap pas hapi se si funksionon një agjent i pjekur i kodimit (Coding Agent).

Në kohën kur Claude Code dhe Cursor po fitojnë popullaritet me shpejtësi, ky artikull i OpenAI nuk është vetëm një demonstrim i forcës, por edhe një "udhëzues për arkitektët e agjentëve për të shmangur kurthet". Pavarësisht nëse dëshironi të përdorni mirë mjetet e programimit AI, ose dëshironi të zhvilloni vetë një Agjent, ky artikull meriton të studiohet fjalë për fjalë.
Artikulli i plotë ka mbi 8300 fjalë dhe leximi zgjat afërsisht 20 minuta.
Së pari, çfarë është Codex CLI?
Codex CLI është një mjet agjenti kodimi me burim të hapur i prodhuar nga OpenAI, i cili mund të ekzekutohet në një kompjuter lokal ose të instalohet në një redaktues kodi. Ai mbështet VS Code, Cursor, Windsurf, etj.
Adresa e burimit të hapur: https://github.com/openai/codex
Dhe Agent Loop (cikli i agjentit) që do të prezantohet këtë herë është logjika thelbësore e Codex CLI: përgjegjëse për koordinimin e përdoruesve, modeleve dhe thirrjeve të modeleve, në mënyrë që të kryejë ndërveprime të vlefshme midis mjeteve.
Agent Loop (Cikli i Agjentit Inteligjent)
Modelet janë vetëm komponentë, vetëm Agjentët (agjentët inteligjentë) mund të përbëjnë një produkt.
Bërthama e çdo Agjenti AI është i ashtuquajturi "cikël i agjentit inteligjent (Agent Loop)". Diagrami skematik i ciklit të agjentit inteligjent është si më poshtë:
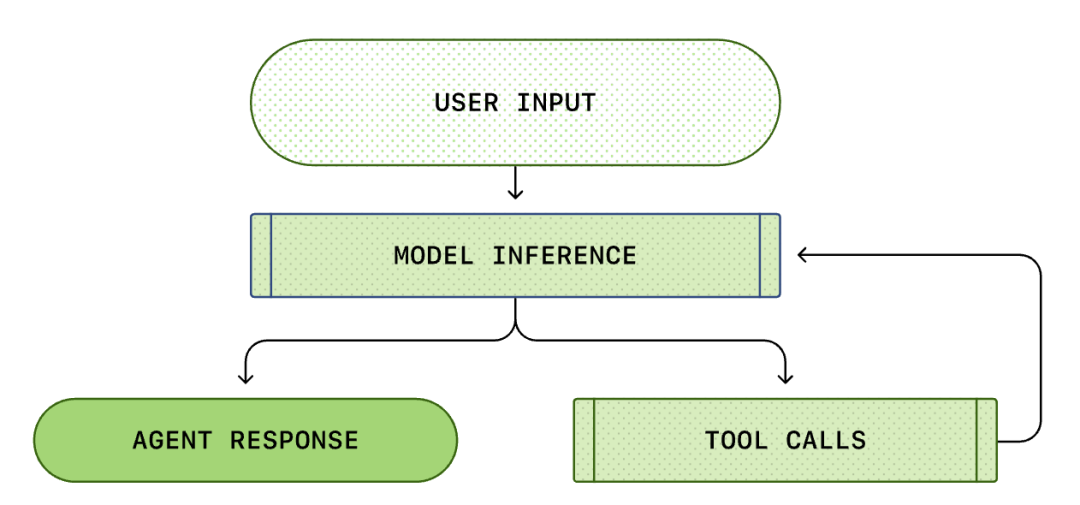
Ne zakonisht mendojmë se programimi AI është: "Unë pyes, ai përgjigjet". Por brenda Codex CLI, ky është një proces kompleks i pafund ciklik...
Një Agent Loop standard përmban hapat e mëposhtëm:
- Udhëzime të përdoruesit: Një grup udhëzimesh tekstuale të futura nga përdoruesi (p.sh. "ristrukturoni këtë funksion").
- Arsyetimi i modelit: Modeli vendos nëse do të përgjigjet drejtpërdrejt ose do të thërrasë një mjet (Tool Call).
- Thirrja e mjetit: Nëse modeli vendos të thërrasë list files ose run shell, CLI do t'i ekzekutojë këto komanda lokalisht.
- Vëzhgimi (Observation): Rezultatet e ekzekutimit të mjetit (kodi, gabimet, lista e skedarëve) kapen.
- Cikli: Këto rezultate i shtohen historisë së bisedës dhe ushqehen përsëri në model. Pasi modeli sheh rezultatet, ai vendos hapin tjetër.
- Përfundimi: Derisa modeli të mendojë se detyra është përfunduar dhe të nxjerrë përgjigjen përfundimtare.
I gjithë procesi nga "hyrja e përdoruesit" në "përgjigjen e agjentit inteligjent" quhet një raund i bisedës (i quajtur një fije në Codex).
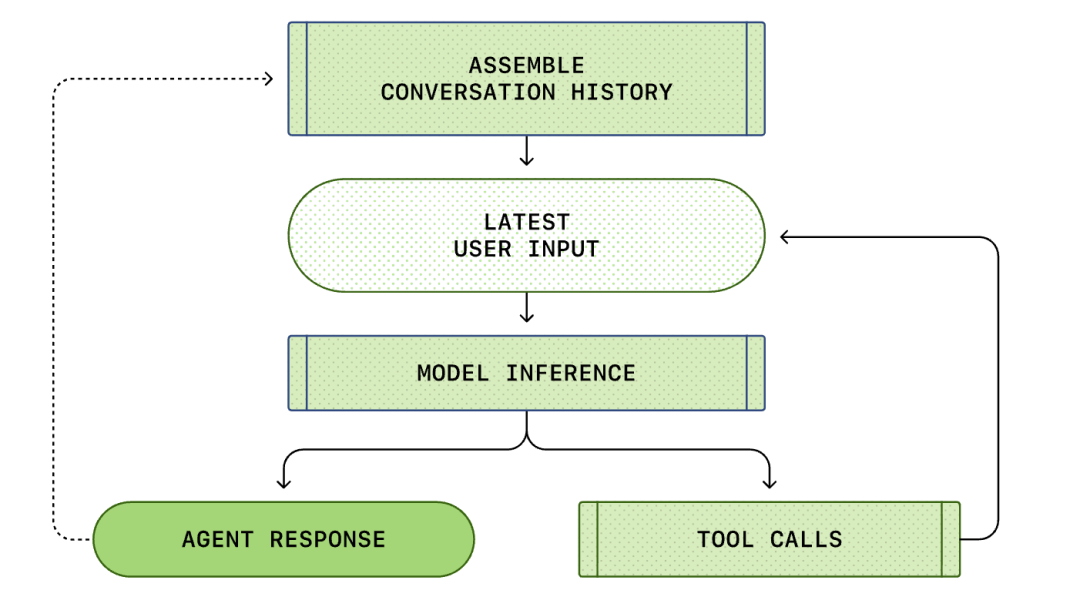
Ndërsa biseda përparon, gjatësia e kërkesës (Prompt) e përdorur për të arsyetuar modelin gjithashtu do të rritet. Kjo gjatësi është e rëndësishme sepse çdo model ka një dritare konteksti, e cila përfaqëson numrin maksimal të fjalëve (tokens) që modeli mund të përdorë në një thirrje arsyetimi.
Arsyetimi i modelit
Codex CLI dërgon kërkesa HTTP në Responses API për arsyetimin e modelit. Codex përdor Responses API për të drejtuar ciklin e agjentit.
Çfarë është Responses API?
Responses API është një gjeneratë e re e ndërfaqes së zhvillimit të agjentëve inteligjentë e lançuar nga OpenAI në mars 2025, e cila synon të unifikojë bisedën, thirrjen e mjeteve dhe aftësitë e përpunimit multimodal, duke u ofruar zhvilluesve një përvojë më fleksibël dhe më të fuqishme të ndërtimit të aplikacioneve AI.
Endpoints API Responses të përdorura nga Codex CLI janë të konfigurueshme dhe mund të përdoren me çdo endpoint që zbaton Responses API.
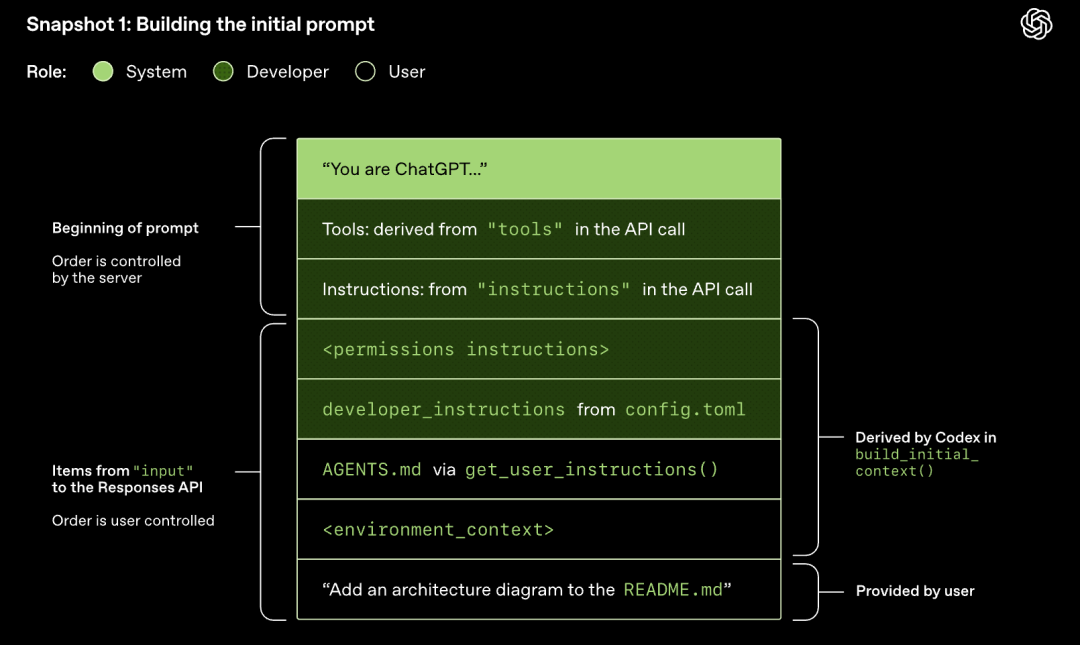
Modeli kryen kampionimin (gjeneron përgjigje)
Kërkesa HTTP e iniciuar në Responses API fillon "turnin" e parë në bisedën Codex. Serveri do të kthejë përgjigjen në mënyrë rrjedhëse përmes Server-Sent Events (SSE).
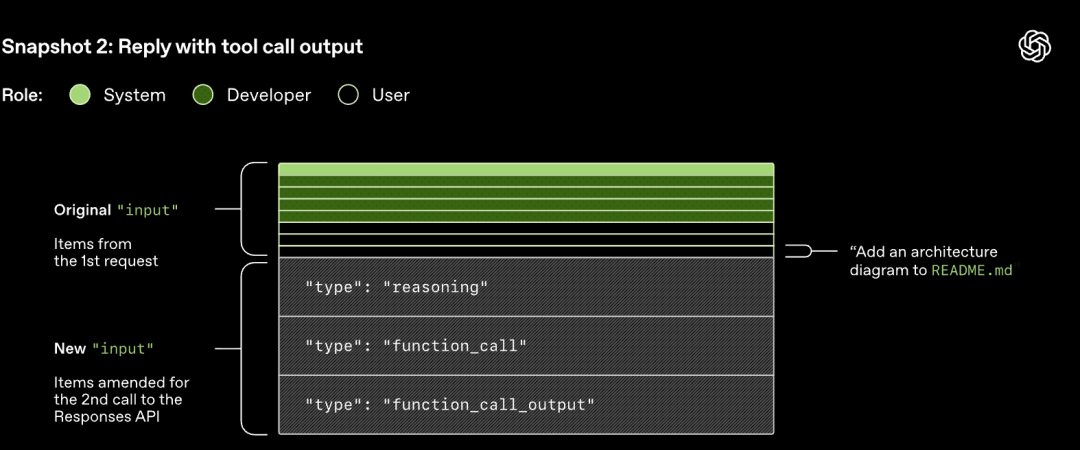
Vini re se kërkesa e raundit të fundit është parashtesa e saktë e kërkesës së re. Ky dizajn mund të përmirësojë ndjeshëm efikasitetin e kërkesave të mëvonshme - mund të përdoret mekanizmi i memorjes së kërkesave.

Ndikimi i zgjatjes së vazhdueshme të kërkesës me rritjen e raundeve
1. Aspekte të performancës
- Rritja e kostos së kampionimit të modelit: Zgjatja e vazhdueshme e kërkesës do të rrisë koston e kampionimit të modelit, sepse procesi i kampionimit duhet të përpunojë më shumë të dhëna, duke çuar në një rritje të sasisë së llogaritjeve.
- Reduktimi i përfitimeve të memorjes: Me zgjatjen e vazhdueshme të kërkesës me rritjen e raundeve, vështirësia e përputhjes së saktë të parashtesës rritet dhe mundësia e goditjes së memorjes zvogëlohet.
2. Aspekte të menaxhimit të dritares së kontekstit
- Dritarja e kontekstit harxhohet lehtësisht: Zgjatja e vazhdueshme e kërkesës do të bëjë që numri i shenjave në bisedë të rritet shpejt dhe sapo të tejkalojë pragun e dritares së kontekstit, mund të çojë në harxhimin e dritares së kontekstit.
- Rritja e nevojës për operacione kompresimi: Për të shmangur harxhimin e dritares së kontekstit, biseda duhet të kompresohet kur numri i shenjave tejkalon pragun.
3. Aspekte të rrezikut të humbjes së memorjes
- Operacione të shumta mund të shkaktojnë humbje të memorjes: Nëse ndryshimet në mjetet e disponueshme të modelit, modelin e synuar, konfigurimin e sandbox, etj. janë të përfshira për shkak të zgjatjes së kërkesës, rreziku i humbjes së memorjes do të rritet më tej.
- Mjetet MCP rrisin kompleksitetin: Serveri MCP mund të ndryshojë dinamikisht listën e mjeteve të ofruara, dhe përgjigja ndaj njoftimeve përkatëse në biseda të gjata mund të çojë në humbje të memorjes.
Informacion referues: "Unrolling the Codex agent loop" Burimi: OpenAI



