Vill du förstå Codex-agenten? Missa inte denna djupgående analys!
Vill du förstå Codex-agenten? Missa inte denna djupgående analys!
OpenAI har precis gjort något "ovanligt".
Vanligtvis släpper OpenAI starkare modeller (som o1), men den här gången publicerade de en djupgående teknisk blogg, 《Unrolling the Codex agent loop》, och öppnade inte bara källkoden för Codex CLI:s kärnlogik, utan bröt också ner steg för steg hur en mogen kodningsagent (Coding Agent) faktiskt fungerar.

I en tid då Claude Code och Cursor vinner fans i rasande fart är OpenAI:s artikel inte bara en uppvisning av muskler, utan också en "guide för agentarkitekter för att undvika fallgropar". Oavsett om du vill använda AI-programmeringsverktyg på ett bra sätt eller utveckla en egen agent är den här artikeln värd att studera ord för ord.
Artikeln är över 8300 ord lång och tar cirka 20 minuter att läsa.
Först, vad är Codex CLI?
Codex CLI är ett öppen källkodsverktyg för kodningsagenter från OpenAI som kan köras på en lokal dator eller installeras i en kodredigerare. Stöder VS Code, Cursor, Windsurf, etc.
Öppen källkodsadress: https://github.com/openai/codex
Agent Loop (agentloop), som kommer att introduceras här, är kärnlogiken i Codex CLI: den ansvarar för att samordna användare, modeller och modellanrop för att utföra interaktioner mellan värdefulla verktyg.
Agent Loop (agentloop)
Modeller är bara komponenter, agenter (intelligenta agenter) kan utgöra produkter.
Kärnan i varje AI-agent är den så kallade "agentloopen". Schematisk diagram över agentloopen visas nedan:
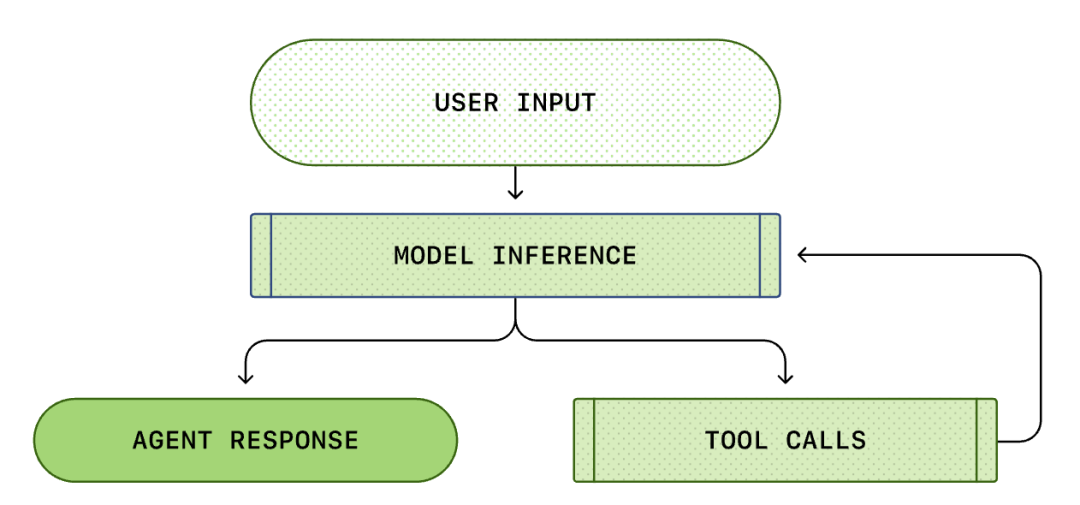
Vi tror vanligtvis att AI-programmering är: "Jag frågar, den svarar". Men inuti Codex CLI är detta en komplex oändlig loop-process...
En standardagentloop innehåller följande steg:
- Användarinstruktioner: En uppsättning textinstruktioner som användaren matar in (t.ex. "refaktorera den här funktionen").
- Modellinferens: Modellen bestämmer om den ska svara direkt eller anropa ett verktyg (Tool Call).
- Verktygsanrop: Om modellen bestämmer sig för att anropa list files eller run shell kommer CLI att köra dessa kommandon lokalt.
- Observation: Resultatet av verktygets körning (kod, fel, fillista) fångas upp.
- Loop: Dessa resultat läggs till i konversationshistoriken och matas in i modellen igen. Efter att ha sett resultatet bestämmer modellen nästa steg.
- Avsluta: Tills modellen anser att uppgiften är slutförd och matar ut det slutliga svaret.
Den kompletta processen från "användarinmatning" till "agentsvar" kallas en konversationsrunda (kallas en tråd i Codex).
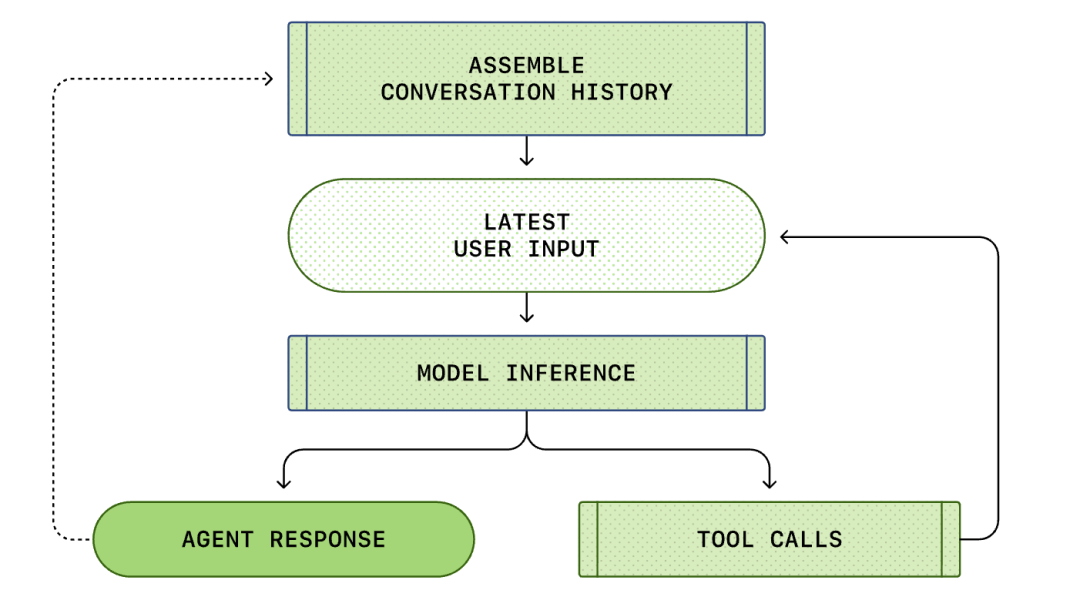
När konversationen fortskrider kommer längden på prompten som används för att resonera med modellen också att öka. Denna längd är viktig eftersom varje modell har ett kontextfönster, som representerar det maximala antalet tokens som modellen kan använda i ett enda inferensanrop.
Modellinferens
Codex CLI skickar HTTP-förfrågningar till Responses API för modellinferens. Codex använder Responses API för att driva agentloopen.
Vad är Responses API?
Responses API är en ny generation av agentutvecklingsgränssnitt som lanserades av OpenAI i mars 2025, som syftar till att förena konversation, verktygsanrop och multimodala bearbetningsmöjligheter för att ge utvecklare en mer flexibel och kraftfull AI-applikationsbyggnadsupplevelse.
Responses API-slutpunkten som används av Codex CLI är konfigurerbar och kan användas med alla slutpunkter som implementerar Responses API.
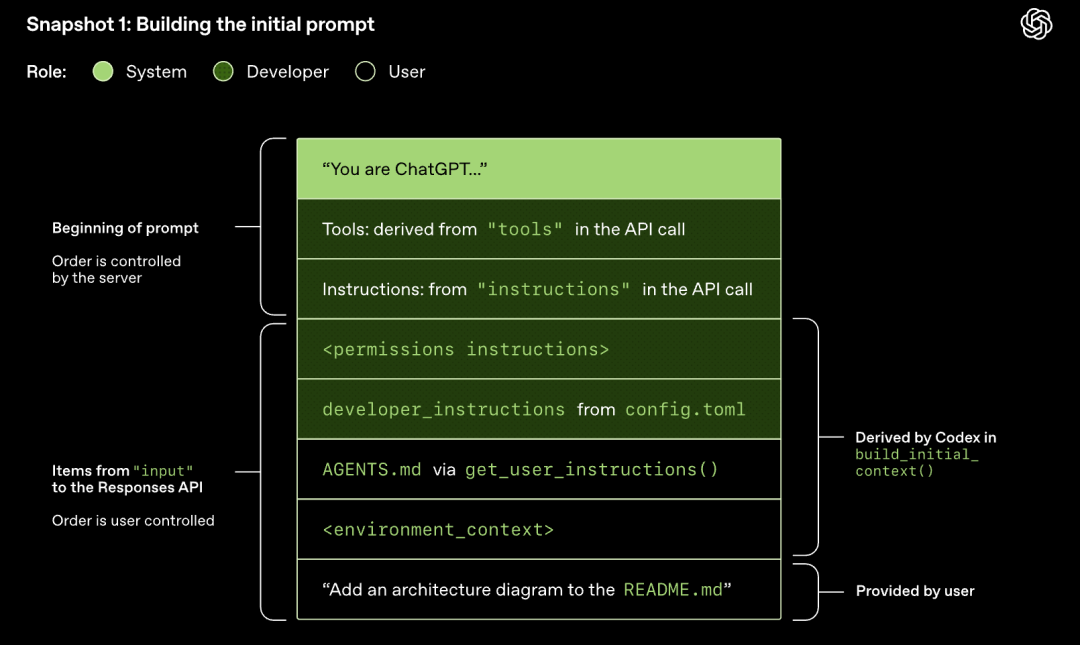
Modellen samplar (genererar svar)
HTTP-förfrågan som initieras till Responses API startar den första "rundan" i Codex-konversationen. Servern returnerar svaret strömmande via Server-Sent Events (SSE).
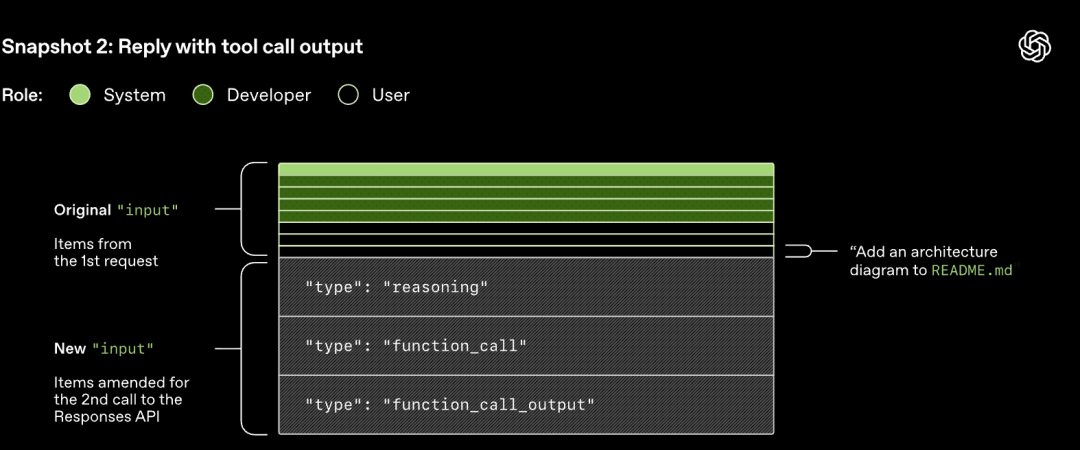
Observera att den tidigare rundans prompt är ett exakt prefix för den nya prompten. Denna design kan avsevärt förbättra effektiviteten i efterföljande förfrågningar - promptcachingmekanismen kan utnyttjas.

Effekterna av att prompten kontinuerligt förlängs med antalet rundor
1. Prestandamässigt
- Ökade kostnader för modellsampling: Den kontinuerliga förlängningen av prompten kommer att öka kostnaderna för modellsampling, eftersom samplingsprocessen behöver bearbeta mer data, vilket leder till en ökning av beräkningsmängden.
- Minskad cacheeffektivitet: När prompten kontinuerligt förlängs med antalet rundor ökar svårigheten att matcha exakta prefix, och sannolikheten för cacheträffar minskar.
2. Hantering av kontextfönster
- Kontextfönstret töms lätt: Den kontinuerliga förlängningen av prompten kommer att göra att antalet tokens i konversationen ökar snabbt, och när tröskelvärdet för kontextfönstret överskrids kan det leda till att kontextfönstret töms.
- Ökat behov av komprimeringsoperationer: För att undvika att kontextfönstret töms måste konversationen komprimeras när antalet tokens överskrider tröskelvärdet.
3. Risk för missad cache
- Flera operationer kan lätt utlösa missad cache: Om ändringar av tillgängliga verktyg för modellen, målmodellen, sandlådekonfigurationen etc. är involverade på grund av förlängningen av prompten, kommer det ytterligare att öka risken för missad cache.
- MCP-verktyg ökar komplexiteten: MCP-servern kan dynamiskt ändra listan över tillhandahållna verktyg, och att svara på relevanta meddelanden i långa konversationer kan leda till missad cache.
Referensinformation: 《Unrolling the Codex agent loop》 Källa: OpenAI



