Bạn muốn hiểu rõ về tác nhân thông minh Codex? Đừng bỏ lỡ bài phân tích chuyên sâu này!
Bạn muốn hiểu rõ về tác nhân thông minh Codex? Đừng bỏ lỡ bài phân tích chuyên sâu này!
OpenAI vừa mới làm một việc "bất thường".
Thông thường, OpenAI sẽ phát hành các mô hình mạnh hơn (ví dụ như o1), nhưng lần này, họ đã phát hành một bài blog kỹ thuật chuyên sâu 《Unrolling the Codex agent loop》, không chỉ mở mã nguồn lõi của Codex CLI, mà còn hướng dẫn chi tiết cách một tác nhân mã hóa (Coding Agent) trưởng thành hoạt động như thế nào.

Trong bối cảnh Claude Code và Cursor đang thu hút sự chú ý mạnh mẽ, bài viết này của OpenAI không chỉ là phô trương sức mạnh, mà còn là một "hướng dẫn tránh bẫy cho kiến trúc sư Agent". Cho dù bạn muốn sử dụng tốt các công cụ lập trình AI, hay muốn tự phát triển một Agent, bài viết này đều đáng để nghiền ngẫm từng chữ.
Toàn văn hơn 8300 chữ, thời gian đọc khoảng 20 phút.
Đầu tiên, Codex CLI là gì?
Codex CLI là một công cụ Agent mã hóa mã nguồn mở do OpenAI phát hành, có thể chạy trên máy tính cục bộ hoặc cài đặt trong trình soạn thảo mã. Hỗ trợ VS Code, Cursor, Windsurf, v.v.
Địa chỉ mã nguồn mở: https://github.com/openai/codex
Và Agent Loop (vòng lặp tác nhân) được giới thiệu lần này là logic cốt lõi của Codex CLI: chịu trách nhiệm điều phối người dùng, mô hình và các lệnh gọi mô hình, để thực hiện các tương tác có giá trị giữa các công cụ.
Agent Loop (Vòng lặp tác nhân thông minh)
Mô hình chỉ là thành phần, Agent (tác nhân thông minh) mới cấu thành sản phẩm.
Trung tâm của mỗi AI Agent là cái gọi là "vòng lặp tác nhân thông minh (Agent Loop)". Sơ đồ của vòng lặp tác nhân thông minh như sau:
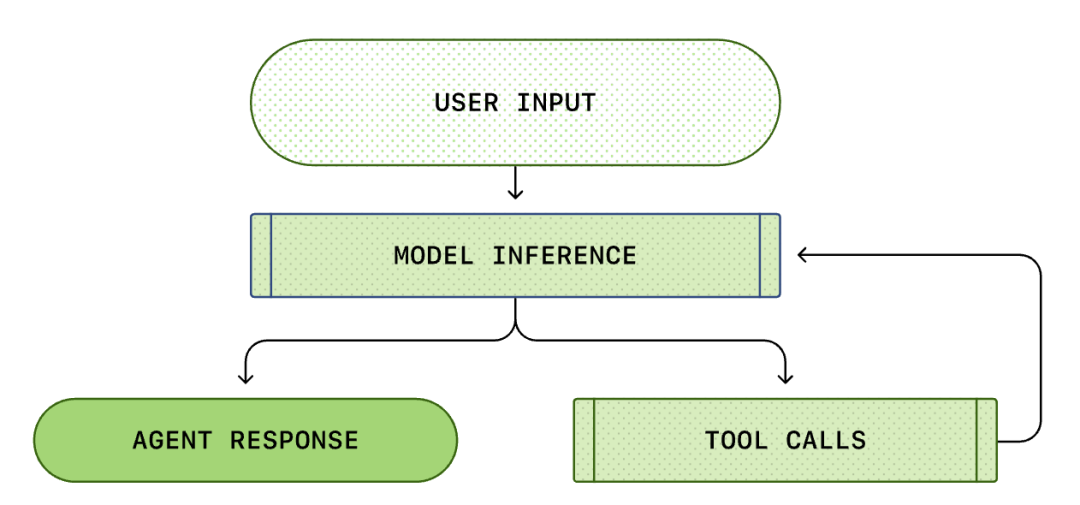
Chúng ta thường nghĩ rằng lập trình AI là: "Tôi hỏi, nó trả lời". Nhưng bên trong Codex CLI, đây là một quá trình lặp vô hạn phức tạp...
Một Agent Loop tiêu chuẩn bao gồm các bước sau:
- Chỉ thị của người dùng: Một tập hợp các chỉ thị văn bản do người dùng nhập (ví dụ: "tái cấu trúc hàm này").
- Suy luận mô hình: Mô hình quyết định trả lời trực tiếp hay gọi công cụ (Tool Call).
- Gọi công cụ: Nếu mô hình quyết định gọi list files hoặc run shell, CLI sẽ thực thi các lệnh này cục bộ.
- Quan sát (Observation): Kết quả thực thi của công cụ (mã, lỗi, danh sách tệp) được thu thập.
- Vòng lặp: Những kết quả này được thêm vào lịch sử hội thoại và được đưa trở lại cho mô hình. Sau khi nhìn thấy kết quả, mô hình quyết định thao tác tiếp theo.
- Kết thúc: Cho đến khi mô hình cho rằng nhiệm vụ đã hoàn thành, nó sẽ xuất ra phản hồi cuối cùng.
Toàn bộ quá trình từ "đầu vào của người dùng" đến "phản hồi của tác nhân thông minh" được gọi là một lượt hội thoại (được gọi là một luồng trong Codex).
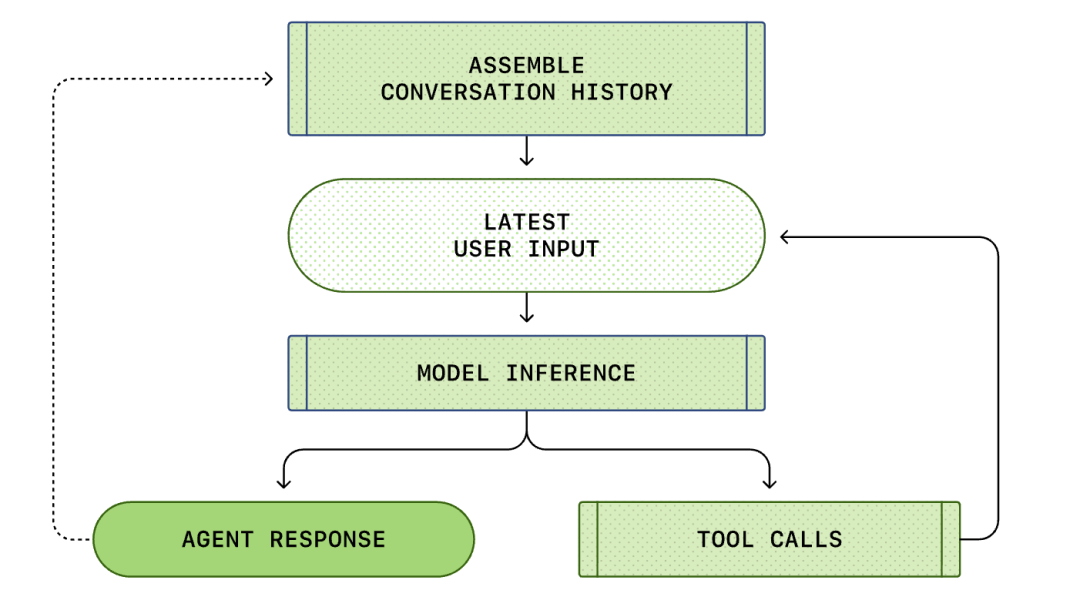
Khi cuộc hội thoại tiếp diễn, độ dài của lời nhắc (Prompt) được sử dụng để suy luận mô hình cũng sẽ tăng lên. Độ dài này rất quan trọng, vì mỗi mô hình đều có một cửa sổ ngữ cảnh, đại diện cho số lượng mã thông báo (tokens) tối đa mà mô hình có thể sử dụng trong một lệnh gọi suy luận.
Suy luận mô hình
Codex CLI gửi yêu cầu HTTP đến Responses API để thực hiện suy luận mô hình. Codex sử dụng Responses API để điều khiển vòng lặp tác nhân.
Responses API là gì?
Responses API là giao diện phát triển tác nhân thông minh thế hệ mới do OpenAI ra mắt vào tháng 3 năm 2025, nhằm thống nhất khả năng xử lý hội thoại, gọi công cụ và đa phương thức, cung cấp cho nhà phát triển trải nghiệm xây dựng ứng dụng AI linh hoạt và mạnh mẽ hơn.
Điểm cuối Responses API mà Codex CLI sử dụng có thể định cấu hình và có thể được sử dụng với bất kỳ điểm cuối nào triển khai Responses API.
Mô hình lấy mẫu (tạo phản hồi)
Yêu cầu HTTP được gửi đến Responses API sẽ khởi động "lượt" đầu tiên trong cuộc hội thoại Codex. Máy chủ sẽ trả về phản hồi theo luồng thông qua Server-Sent Events (SSE).
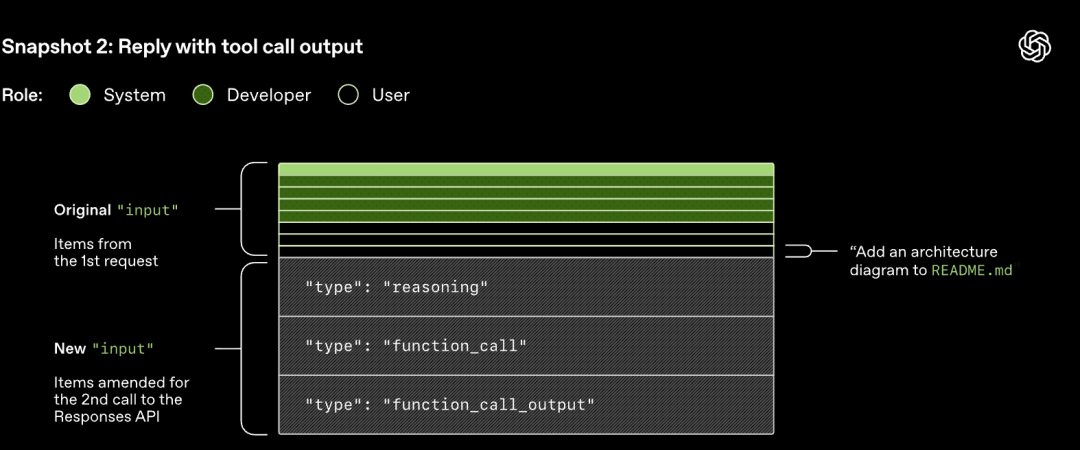
Lưu ý rằng lời nhắc của lượt trước là tiền tố chính xác của lời nhắc mới. Thiết kế này có thể cải thiện đáng kể hiệu quả của các yêu cầu tiếp theo - có thể tận dụng cơ chế bộ nhớ cache lời nhắc.

Ảnh hưởng của việc lời nhắc tăng lên liên tục theo lượt
1. Về hiệu suất
- Tăng chi phí lấy mẫu mô hình: Việc lời nhắc liên tục kéo dài sẽ làm tăng chi phí lấy mẫu mô hình, vì quá trình lấy mẫu cần xử lý nhiều dữ liệu hơn, dẫn đến tăng khối lượng tính toán.
- Giảm hiệu quả bộ nhớ cache: Khi lời nhắc liên tục kéo dài theo lượt, độ khó của việc khớp tiền tố chính xác tăng lên, làm giảm khả năng bộ nhớ cache được sử dụng.
2. Về quản lý cửa sổ ngữ cảnh
- Dễ cạn kiệt cửa sổ ngữ cảnh: Việc lời nhắc liên tục kéo dài sẽ làm cho số lượng mã thông báo trong cuộc hội thoại tăng nhanh chóng, một khi vượt quá ngưỡng của cửa sổ ngữ cảnh, có thể dẫn đến cạn kiệt cửa sổ ngữ cảnh.
- Tăng tính cần thiết của thao tác nén: Để tránh cạn kiệt cửa sổ ngữ cảnh, cần nén cuộc hội thoại khi số lượng mã thông báo vượt quá ngưỡng.
3. Về rủi ro bỏ lỡ bộ nhớ cache
- Nhiều thao tác dễ gây ra bỏ lỡ bộ nhớ cache: Nếu việc kéo dài lời nhắc liên quan đến việc thay đổi các công cụ có sẵn của mô hình, mô hình mục tiêu, cấu hình hộp cát, v.v., sẽ làm tăng thêm rủi ro bỏ lỡ bộ nhớ cache.
- Công cụ MCP làm tăng sự phức tạp: Máy chủ MCP có thể thay đổi động danh sách các công cụ được cung cấp, việc phản hồi các thông báo liên quan trong các cuộc hội thoại dài có thể dẫn đến bỏ lỡ bộ nhớ cache.
Thông tin tham khảo: 《Unrolling the Codex agent loop》Nguồn: OpenAI



