智谱GLM-5 aquesta vegada de codi obert, fins i tot els programadors avançats estan en perill...
De debò, la IA del 2026 està molt més boja que la del 2025.
Darrerament, jo, que passo 16 hores al dia immers en la IA, tinc problemes per seguir el ritme de l'evolució de la IA. Sento que cada dia que em desperto, el món ha canviat.
Doncs bé, ahir a la nit, Zhipu va fer un altre gran moviment, directament obrint el codi del seu model insígnia més potent actual: GLM-5.
En la llista autoritzada mundial Artificial Analysis, GLM-5 va superar Gemini i va arribar al quart lloc mundial, primer en codi obert!
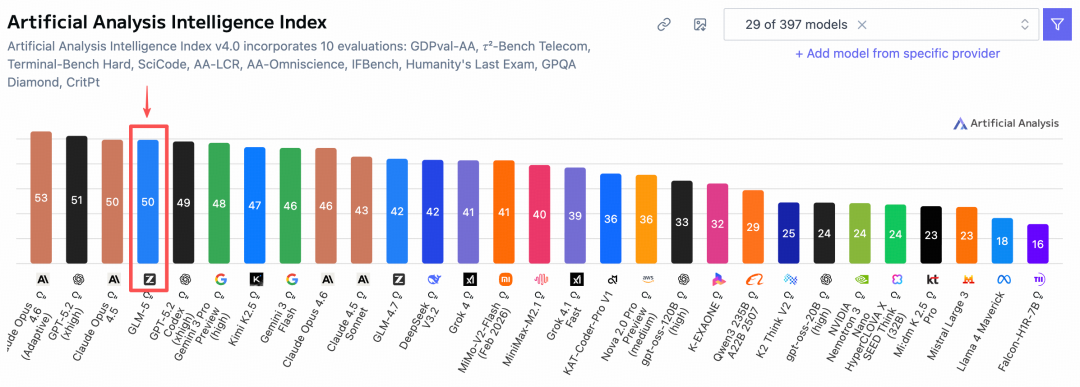
Tal com havia previst, recordo que quan es va llançar GLM-4.7 l'última vegada, vaig fer una predicció als germans en l'article: endevino que GLM-4.8 o GLM-5 es llançarà abans del Festival de Primavera, no esperava que arribés de veritat, haha 😄
A més, el número de versió aquesta vegada finalment no és com les actualitzacions graduals anteriors de 4.5, 4.6, 4.7, aquesta vegada va directament a 5.0.
Això demostra que no és una petita correcció, sinó un gran salt en la capacitat de la base.
Primer, deixeu-me presentar-vos què ha actualitzat GLM-5 aquesta vegada:
En poques paraules, els models anteriors, tothom estava generalment fent Vibe Coding, que és l'anomenada generació d'una frase, per veure qui genera efectes especials de pàgina web més genials, per veure qui pot crear un joc genial amb una frase.
Però GLM-5 aquesta vegada no competeix amb tu en això (finalment!), ha elevat la capacitat del model gran d'escriure codi a poder construir sistemes.
Què vol dir això? El seu focus ja no és escriure pàgines front-end boniques, sinó que ha evolucionat cap a un arquitecte de sistemes que pot fer treballs bruts, treballs pesats i tasques llargues.
Emfatitza Agentic Engineering, és a dir, la capacitat d'enginyeria d'agents intel·ligents.
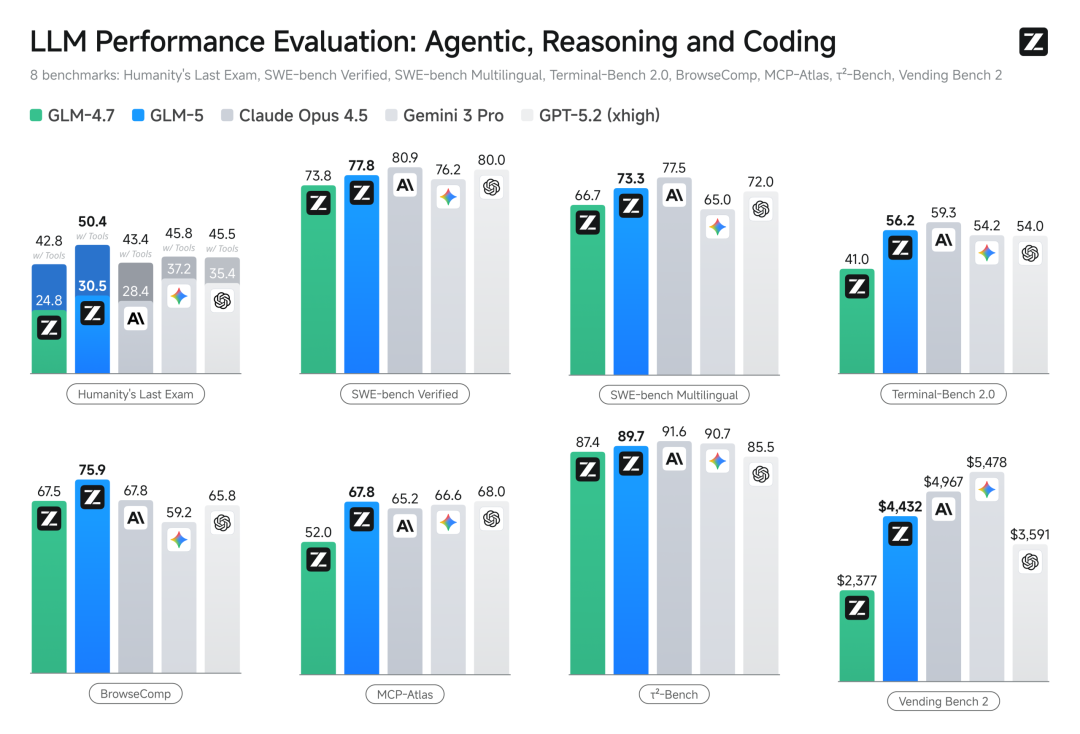
Vaig mirar les dades oficials, l'escala de paràmetres va passar de 355B a 744B (activació 40), les dades de pre-entrenament van passar de 23T a 28.5T.
En el test de referència de programació reconegut SWE-bench-Verified, va obtenir una puntuació de 77.8, deixant directament enrere Gemini 3 Pro, i es pot dir que és comparable al model de codi tancat més potent reconegut actualment, Claude Opus 4.5.
Actualment es pot utilitzar gratuïtament a z.ai:
Adreça de codi obert:
GitHub: https://github.com/zai-org/GLM-5
Hugging Face: https://huggingface.co/zai-org/GLM-5
ModelScope: https://modelscope.cn/models/ZhipuAI/GLM-5
De fet, fa uns dies, va aparèixer de sobte un model misteriós anomenat Pony a X.
En aquell moment, molts amics es preguntaven, qui és aquest Pony? Hi havia moltes opinions.
De fet, el model amb el nom en clau Pony és GLM-5, pel que fa a per què es diu Pony, probablement perquè l'any del Cavall s'acosta 🤔.
També vaig connectar Pony a Claude Code des d'OpenRouter per provar-ho la primera vegada, per ser sincer, és molt fort (la popularitat a X també és molt alta).
Només va trigar 7 minuts a generar una estació de trànsit d'API d'una sola vegada!
Tot i que encara és una demostració MVP, les funcions de la pàgina ja estan completes i inclouen la lògica de backend i la base de dades, les dades són dinàmiques, és petita però completa.
 Després d'una experiència profunda, vaig descobrir que quan GLM-5 fa plans, aquest gust és molt semblant a Claude Opus.
Després d'una experiència profunda, vaig descobrir que quan GLM-5 fa plans, aquest gust és molt semblant a Claude Opus.
Els amics que estan familiaritzats amb Claude Opus saben que abans de treballar, pot fer una llista molt detallada i lògica per a tu.
GLM-5 ara també té aquesta capacitat.
Per exemple, tinc una cosa que sempre he volgut fer, però que no he fet mai per mandra.
Tinc un munt de comptes de membres de Gemini, ChatGPT, Kimi, Zhipu, etc.
Normalment, quan escric articles o busco informació, sovint vull escoltar les opinions de múltiples IA i comparar-les de manera integral.Aleshores hauria d'obrir diverses finestres del navegador, copiar i canviar entre diferents finestres per enganxar i enviar moltes vegades, i després canviar entre les finestres per veure els resultats.
Encara que no és gran cosa, és molt molest quan es fa moltes vegades.
Estava pensant, podria fer un complement de navegador que pugui enviar la mateixa pregunta als quatre llocs web d'IA alhora en una finestra unificada, i després rebre les respostes de manera unificada al complement?
Però això és bastant complicat, perquè l'estructura de cada lloc web d'IA és diferent, i hi ha diversos mecanismes de protecció, que requereixen analitzar les seves estructures DOM.
Així que vaig assignar aquesta complexa tasca a GLM-5.
Vaig activar el mode de pla de Claude Code per fer un pla primer
Després també interactuarà amb mi, demanant la meva opinió:
El pla final obtingut és molt detallat, realment massa llarg, amb 633 línies.
Després va començar a executar-se segons el pla, però no esperava que el primer pas d'inicialització del projecte trigaria més de 50 minuts...
Durant aquest procés, va cridar automàticament l'eina Playwright MCP, va obrir el navegador ell mateix i va visitar els llocs web d'IA.
És com un programador real, que comprova els elements de la clau, analitza on és el quadre d'entrada, quin és el Class del botó d'enviament, com obtenir el flux de text retornat... Tot el procés és automàtic, no he escrit ni una línia de codi.
PS: Vaig oblidar gravar la pantalla, perquè també estava executant una altra tasca en altres finestres alhora
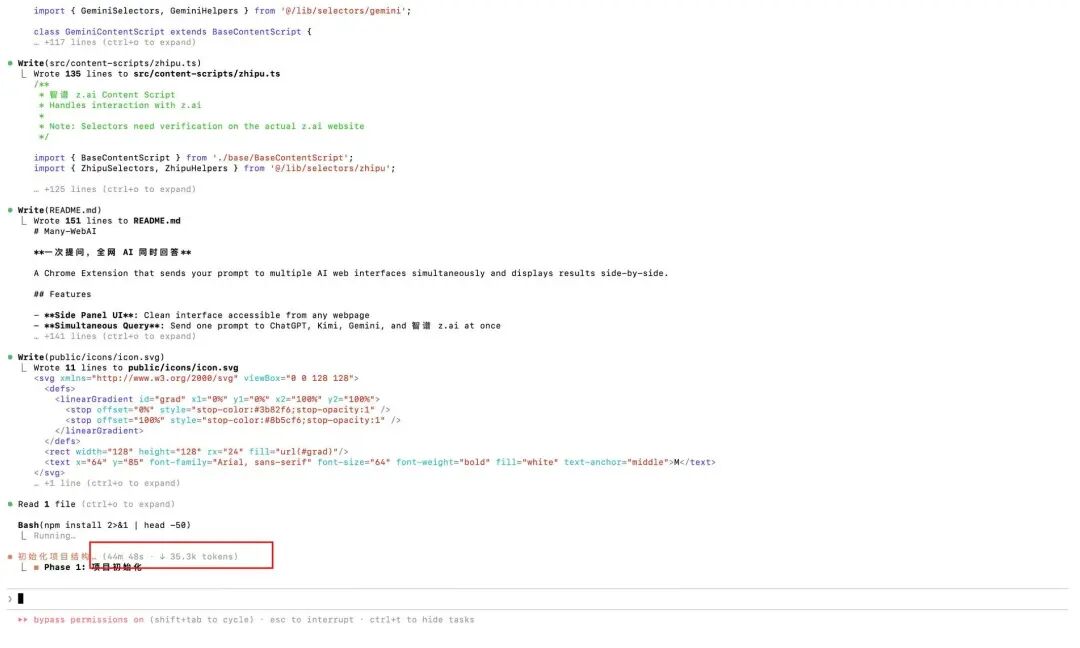 L'espera val la pena, el complement que volia per fer una pregunta i obtenir respostes de tota la xarxa d'IA ha sortit calent.
L'espera val la pena, el complement que volia per fer una pregunta i obtenir respostes de tota la xarxa d'IA ha sortit calent.
Això és exactament el que necessitava~
A més, no havia fet abans una plataforma de generació de vídeos de màrqueting de persona digital amb un sol clic?
Més tard, per buscar una millor experiència, vaig reestructurar el frontend, i aquesta reestructuració va fer que tot el projecte fos un caos: les interfícies frontend i backend no coincidien, algunes lògiques antigues del backend no funcionaven davant del nou frontend, hi havia molts errors i era molt molest de solucionar.
Aquesta vegada, vaig activar el mode de pla a Claude Code, i després vaig assignar directament la tasca de trobar i corregir errors del flux principal a GLM-5
Primer va sortir un pla detallat:
Després de confirmar que el pla era correcte, el vaig deixar començar a executar-se (durant el procés es va utilitzar el navegador mcp per controlar).
La seva velocitat d'execució no és ràpida.
Però no és que el model sigui lent, moltes vegades, veig que la velocitat de consum de Token puja a milers per segon a ull nu.
Però com que la tasca és massa complexa, necessita autoreflexionar-se constantment, cridar eines i executar proves.
També hi ha temps que es consumeix en la descàrrega de dependències o l'execució d'ordres.
Aquesta tasca de reparació també va trigar més de 40 minuts.
Potser alguns amics diran, 40 minuts? Ja ho hauria escrit.
Emmm, però durant aquests 40 minuts, vaig obrir la gravació de pantalla, vaig veure vídeos i fins i tot vaig treure el gos a passejar.
I ell estava concentrat ajudant-me a treballar, i estava fent el tipus de treball més dolorós de trobar errors i reestructurar.
No mireu que s'executa lentament, però l'efecte final obtingut és molt significatiu.
Quan l'executo, bé, bàsicament tots els problemes estan resolts.
Si us plau, mireu el VCR:
Aquí també hi ha alguns efectes que vaig descobrir quan vaig provar petits errors més tard, i després el vaig deixar reparar i optimitzar.
Però en la reparació d'errors i l'optimització de funcions, realment estic tranquil de deixar-ho a ell.
Abans, quan utilitzava altres IA per corregir errors, sovint em preocupava que cada cop hi hagués més errors i que el projecte fos cada cop més caòtic, típicament desmuntant una paret per reparar-ne una altra...
Abans, per evitar aquest problema, havia d'utilitzar diversos mitjans d'enginyeria per restringir la IA.
Per exemple, cada vegada que modificava, emfatitzava l'àmbit, o escrivia això a les regles, o només corregia un error cada vegada, i després de cada modificació, havia de provar altres funcions... De totes maneres, era molt molest.
Però utilitzar GLM-5 per modificar errors, l'experiència ha canviat completament.
Només necessito descriure la situació actual, llançar-li els registres d'errors i dir-li quin és l'efecte que espero.
Gairebé sempre pot reparar-ho amb èxit una vegada, i no afectarà gens altres funcions.
Fins i tot, en una conversa, vaig llançar directament els quatre errors diferents trobats en tot el procés, i ell també els va poder reparar un per un de manera clara.
Aquesta sensació d'estabilitat és realment molt còmoda.
Ara puc deixar que GLM-5 m'ajudi a completar qualsevol tasca de desenvolupament complexa amb tranquil·litat, bàsicament sense errors.
Fins i tot si hi ha problemes de tant en tant, puc executar una ordre de reversió a Claude Code i tornar enrere per començar de nou.
Després que tot el projecte s'hagi optimitzat amb GLM-5, bàsicament tots els processos estan resolts.També em preparo per obrir aquest projecte aviat (encara necessito extreure la part de diverses API de models i convertir-la en configuració).
«Finalment»
Després d'experimentar amb GLM-5, la meva major sensació és: La IA xinesa realment s'ha aixecat.
Fa uns dies, es va llançar Seedance 2.0 de ByteDance, demostrant que el model xinès nacional ha assolit el primer nivell mundial en el camp de la generació de vídeo, superant directament Sora2 i Veo3.1.
I aquest llançament de Zhipu GLM-5 ha donat una resposta que supera les expectatives en una altra pista dura, la codificació d'IA.
Abans sempre dèiem que els models xinesos tenien una bretxa amb GPT, Claude Opus i Gemini en raonament lògic i escriptura de codi.
Però avui, GLM-5 ens diu amb un rendiment sòlid: aquesta bretxa s'està esborrant.
GLM-5 tampoc és una joguina que només es pot utilitzar per fer demostracions, és una eina de productivitat que realment pot ajudar-te a fer la feina, a construir sistemes, a resoldre tasques llargues i problemes complexos.
El més important és que és de codi obert.
Això significa que cada desenvolupador, cada empresa, pot tenir un arquitecte d'IA de primer nivell a un cost menor.
I actualment, el pla de codificació de GLM s'ha venut molt, l'oficial ha anunciat que s'està expandint urgentment i, el més important, aquesta vegada s'està connectant a un clúster de desenes de milers de targetes de xips xinesos.
No obstant això, a causa de l'augment de la inversió en potència de càlcul, el preu ha augmentat una mica, però per sort abans vaig aconseguir el paquet Max.
Aquí també es pot veure que, des dels xips fins als models, des de la potència de càlcul subjacent fins a les aplicacions de nivell superior, estem construint un conjunt de pila de tecnologia d'IA de primer nivell mundial que és completament nostre.
El 2026 està destinat a ser un any d'explosió d'aplicacions d'IA, i també un any més boig.
Si també vols experimentar la sensació de tenir un arquitecte d'IA de primer nivell, afanya't i prova GLM-5.Condició prèvia: has d'aconseguir el paquet Max, haha.



