智谱GLM-5这次开源,让高级程序员也危险了...
Så ville jeg skulle åbne flere browservinduer, kopiere og skifte mellem forskellige vinduer for at indsætte og sende flere gange, og derefter skifte mellem vinduer for at se resultaterne.
Selvom det ikke er den store ting, er det virkelig irriterende, når det sker mange gange.
Jeg tænkte, om det var muligt at lave en browserudvidelse, der kunne sende det samme spørgsmål til disse fire AI'ers webversioner i et enkelt vindue, og derefter modtage svarene samlet i udvidelsen?
Men det er faktisk ret besværligt, fordi hver AI-hjemmesides struktur er forskellig, og der er forskellige beskyttelsesmekanismer, der skal analyseres deres DOM-struktur.
Så jeg overlod denne komplekse opgave til GLM-5.
Startede Claude Codes Plan Mode for at få den til at lave en plan først
Og så ville den interagere med mig og spørge om min mening:
Den endelige plan var meget detaljeret, virkelig for lang, med 633 linjer...
Så den begyndte at udføre planen, og jeg havde ikke forventet, at det første trin med at initialisere projektet ville tage over 50 minutter...
I løbet af denne proces kaldte den automatisk Playwright MCP-værktøjet, åbnede selv browseren og besøgte de forskellige AI-hjemmesider.
Den var som en rigtig programmør, der inspicerede elementer, analyserede, hvor inputfeltet var, hvad klassen på send-knappen var, hvordan man fik den returnerede tekststrøm... hele processen var fuldautomatisk, jeg skrev ikke en eneste linje kode.
PS: Glemte at optage skærmen, fordi jeg samtidig kørte en anden opgave i et andet vindue
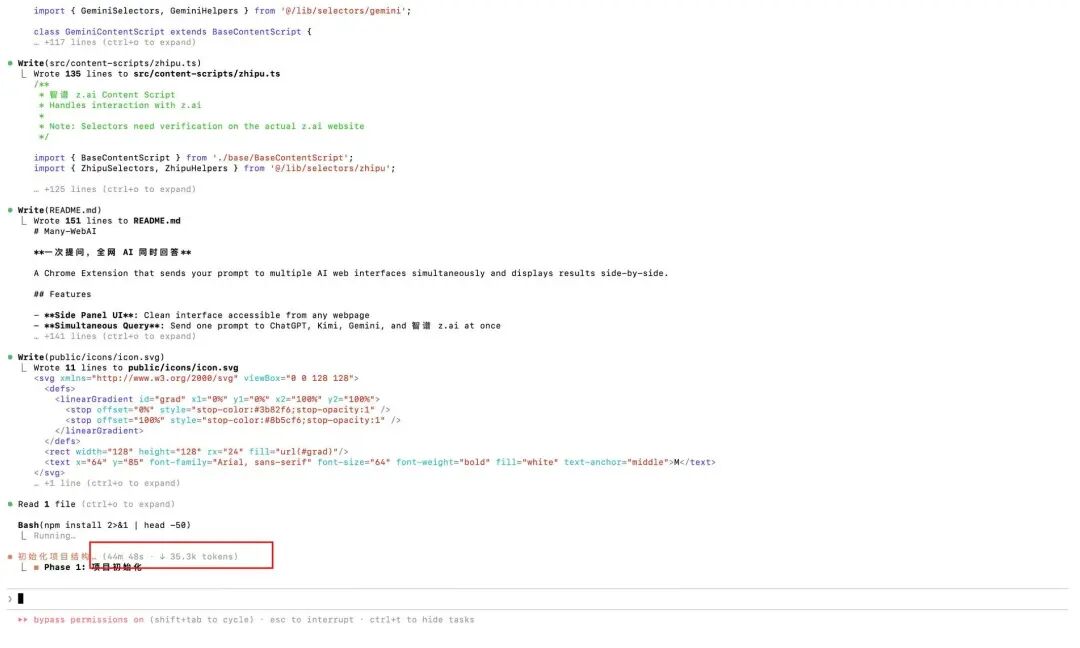
Det var værd at vente, den udvidelse, jeg ønskede, med et enkelt spørgsmål og svar fra alle AI'er på én gang, kom dampende ud af ovnen.
Det er præcis, hvad jeg havde brug for~
Derudover, lavede jeg ikke en platform til et-klik-generering af digitale personmarkedsføringsvideoer før?
Senere, for at opnå en bedre oplevelse, omstrukturerede jeg frontend, og denne omstrukturering var ikke god, hele projektet var et stort rod: frontend- og backend-grænseflader stemte ikke overens, noget af den gamle backend-logik kunne ikke køre på den nye frontend, der var mange fejl, og det var meget besværligt at ordne.
Denne gang startede jeg plan mode i Claude Code og overlod opgaven med at finde og rette fejl i hovedprocessen direkte til GLM-5
Først kom der en detaljeret plan:
Efter at have bekræftet, at planen var korrekt, lod jeg den begynde at udføre (browser-mcp blev brugt til at kontrollere processen).
Dens udførelseshastighed er ikke hurtig.
Men det er ikke modellen, der er langsom, mange gange ser jeg, at forbruget af Token stiger til tusindvis på et sekund med det blotte øje.
Men fordi opgaven er for kompleks, skal den konstant reflektere over sig selv, kalde værktøjer og køre tests.
Noget af tiden bruges også på at downloade afhængigheder eller udføre kommandoer.
Denne reparationsopgave tog også over 40 minutter.
Nogle venner vil måske sige, 40 minutter? Jeg ville have skrevet det færdigt.
emmm, men i disse 40 minutter havde jeg optagelse kørende, så videoer og gik endda ud for at lufte hunden.
Og den var fuldt fokuseret på at hjælpe mig med at arbejde, og det var den slags arbejde, der var mest hovedpinefremkaldende, at finde fejl og omstrukturere.
Selvom den udfører langsomt, er den endelige effekt meget markant.
Da jeg kørte det, var de fleste problemer løst.
Se venligst VCR:
Der er også nogle effekter her, som jeg opdagede små fejl, da jeg testede det senere, og lod den rette og optimere dem.
Men når det kommer til at rette fejl og optimere funktioner, er jeg virkelig tryg ved at overlade det til den.
Før, når jeg brugte andre AI'er til at rette fejl, var jeg ofte bange for, at der ville komme flere og flere fejl, og at projektet ville blive mere og mere rodet, typisk at tage fra Peter for at betale Paul...
For at undgå dette problem før, måtte jeg bruge forskellige ingeniørmæssige metoder til at begrænse AI'en.
For eksempel hver gang jeg ændrede, understregede jeg omfanget, eller skrev disse ind i reglerne, eller ændrede kun en fejl ad gangen, og efter hver ændring måtte jeg teste andre funktioner... det var i hvert fald meget besværligt.
Men oplevelsen af at bruge GLM-5 til at rette fejl er fuldstændig ændret.
Jeg behøver kun at beskrive situationen, smide fejllogfilerne til den og fortælle den, hvad jeg forventer af effekten.
Den kan næsten rette det med succes én gang, og det vil slet ikke påvirke andre funktioner.
Selv, i en samtale, smed jeg direkte alle fire forskellige fejl, der blev fundet i hele processen, til den, og den kunne også rette dem én efter én på en klar måde.
Denne følelse af stabilitet er virkelig behagelig.
Jeg kan nu trygt overlade GLM-5 til at hjælpe mig med at fuldføre enhver kompleks udviklingsopgave, og den vil stort set ikke lave fejl.
Selv hvis der er problemer en gang imellem, kan jeg bare udføre en rollback-kommando i Claude Code og gå tilbage og starte forfra.
Efter at hele projektet er blevet optimeret af GLM-5, er alle processer stort set færdige.
**Jeg planlægger også snart at open source dette projekt (skal stadig udtrække forskellige model-API'er og gøre dem til konfigurationer).** **»Afsluttende«** Efter at have oplevet GLM-5 er min største følelse: **Kinesisk AI er virkelig rejst sig.** For et par dage siden blev ByteDance's Seedance 2.0 frigivet, hvilket beviste, at kinesiske modeller inden for videogenerering allerede har nået verdensklasse og direkte overgår Sora2 og Veo3.1. Og denne gang har Zhipu GLM-5's frigivelse leveret et uventet godt svar på et andet hardcore spor, AI Coding. Vi sagde altid før, at kinesiske modeller halter bagefter GPT, Claude Opus og Gemini inden for logisk ræsonnement og kodning. Men i dag fortæller GLM-5 os med konkrete resultater: Denne kløft bliver udlignet. GLM-5 er heller ikke bare et legetøj, der kan bruges til at lave demoer; det er et produktivitetsværktøj, der virkelig kan hjælpe dig med at arbejde, hjælpe dig med at bygge systemer, hjælpe dig med at løse lange opgaver og komplekse problemer. **Det vigtigste er, at det er open source.** Dette betyder, at enhver udvikler, enhver virksomhed, kan have en top AI-arkitekt til en lavere pris. Og i øjeblikket er GLM's Coding Plan blevet udsolgt. De officielle meddelelser siger, at de hurtigt udvider kapaciteten, og fokus er, at denne gang er det adgang til en kinesisk chip med et klynge af titusindvis af kort. Men på grund af den øgede investering i computerkraft er prisen steget lidt, heldigvis fik jeg Max-pakken før. Her kan vi også se, at vi fra chips til modeller, fra underliggende computerkraft til applikationer på øverste niveau, er ved at opbygge et fuldt ud eget, verdensklasse AI-teknologistak. 2026 er bestemt et år med eksplosion af AI-applikationer og også et mere vanvittigt år. Hvis du også vil opleve følelsen af at have en top AI-arkitekt, så skynd dig at prøve GLM-5.Forudsætningen er, at du skal snuppe Max-pakken, haha.


