智谱GLM-5这次开源,让高级程序员也危险了...
真的,2026年的AI比25年疯太多了。
最近我这个一天16个小时泡在AI里面的人,都有点追不上AI进化的速度。感觉每天一睁眼,世界就变了个样。
这不,昨天深夜,智谱又放了个大招,直接开源了他们目前最强的旗舰模型:GLM-5。
在全球权威的Artificial Analysis榜单里面,GLM-5超越Gemini干到了全球第四、开源第一!
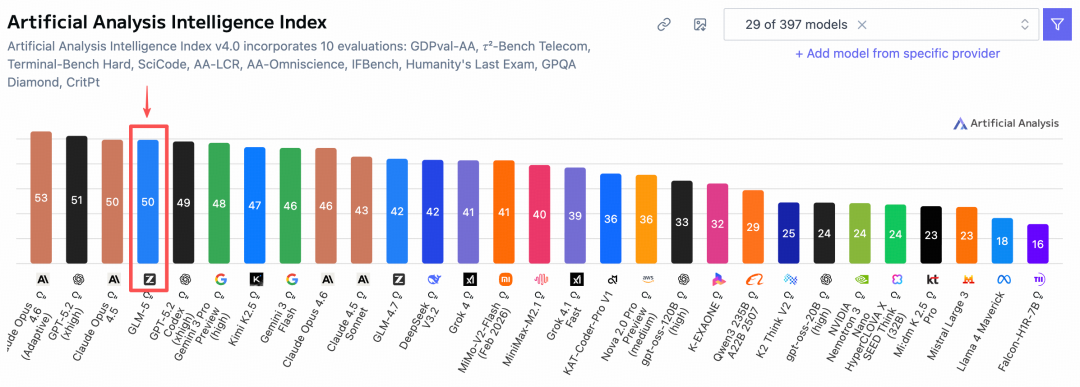
还真是如我所料啊,记得上次GLM-4.7发布的时候,我就在文章里跟兄弟们预测了一波:盲猜GLM-4.8或者GLM-5将在春节前夕发布,没想到真来了,哈哈😄
而且这次的版本号终于不像之前那样4.5、4.6、4.7这样挤牙膏式的更新了,这次直接干到了5.0。
这就说明,不是什么小修小补,是底座能力的大跨越。
先给大家介绍一下,这次GLM-5到底更新了啥:
简单来说,之前的模型,大家普遍都在卷Vibe Coding,就是所谓的一句话生成,看谁生成的网页特效更炫酷,看谁能一句话搓个炫酷的游戏。
但GLM-5这次不跟你卷这个了(终于!),它把大模型的能力从写代码,提升到能构建系统。
什么意思呢?它的重心不再是写漂亮的前端页面,而是进化成了一个能干脏活、累活、做长任务的系统架构师。
强调的是Agentic Engineering,也就是智能体工程能力。
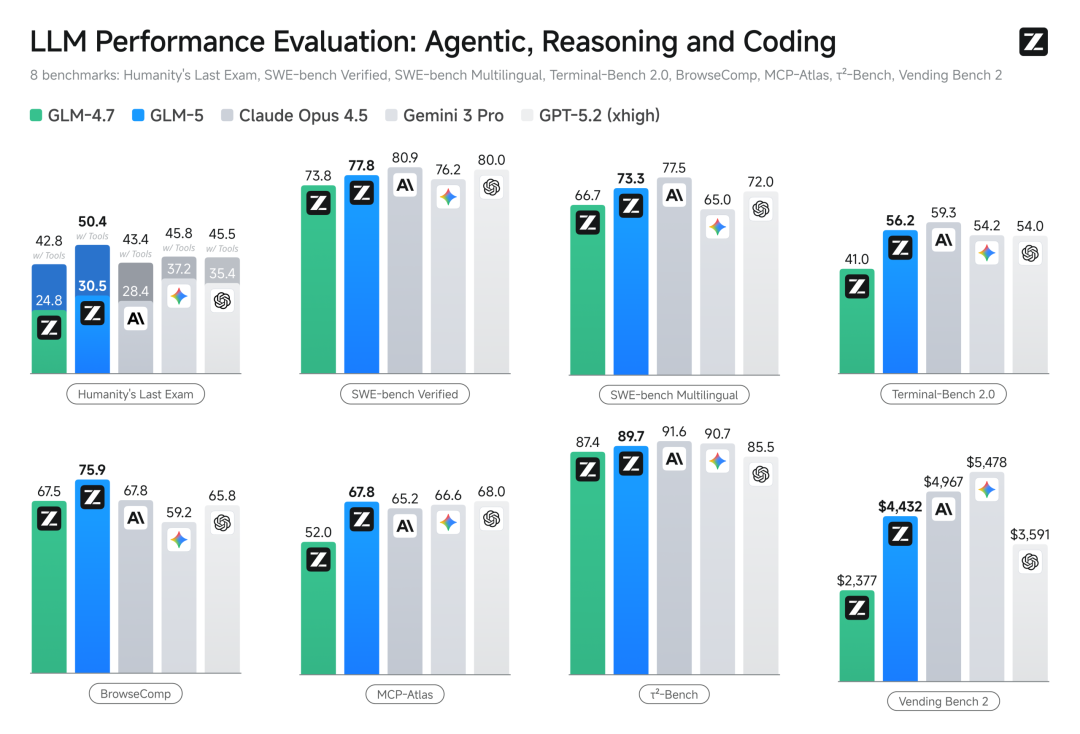
我看了下官方的数据,参数规模从355B干到了744B(激活40),预训练数据从23T提升到了28.5T。
在SWE-bench-Verified这个公认的编程基准测试里,得分77.8,直接把Gemini 3 Pro甩在了身后,和目前公认的最强闭源模型Claude Opus 4.5可以说是不相上下。
目前在z.ai上面就可以免费使用:
开源地址:
GitHub:https://github.com/zai-org/GLM-5
Hugging Face:https://huggingface.co/zai-org/GLM-5
ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5
其实在前几天,X上就突然冒出来一个叫Pony的神秘模型。
当时很多朋友都在猜,这个Pony到底是哪路神仙?众说纷纭
其实代号Pony的模型就是GLM-5,至于为什么叫Pony呢,大概是因为马年快到了吧🤔。
我当时也第一时间从OpenRouter把Pony接入到Claude Code里试用了一下,说实话,真滴很强(在X上热度也是非常高)。
只花了7分钟,一次性生成了一个API中转站!
虽然还是MVP Demo,但是页面功能已经很齐全了,而且包含后端逻辑,以及数据库,数据是动态的,麻雀虽小五脏俱全。
 在深度体验后,我发现GLM-5在制定计划的时候,那种味道,太像Claude Opus了。
在深度体验后,我发现GLM-5在制定计划的时候,那种味道,太像Claude Opus了。
熟悉Claude Opus的朋友都知道,在干活之前,可以用它会给你列一个非常详细、逻辑严密的计划。
GLM-5现在也有了这个能力。
比如,我有一个一直想做,但是因为懒一直没动手的事儿。
我手头有Gemini、ChatGPT、Kimi、智谱等等一堆会员账号。
平时写文章或者查资料的时候,有些问题我经常会想听听多个AI的意见,综合对比一下。 Dann müsste ich mehrere Browserfenster öffnen, kopieren, zwischen verschiedenen Fenstern wechseln, einfügen, senden und das mehrmals, und dann abwechselnd die Fenster wechseln, um die Ergebnisse zu überprüfen.
Obwohl es keine große Sache ist, ist es auf Dauer wirklich nervig.
Ich habe mich gefragt, ob man ein Browser-Plugin erstellen könnte, das in einem einzigen Fenster gleichzeitig dieselbe Frage an die Webseiten dieser vier KIs senden und dann die Antworten in dem Plugin einheitlich empfangen kann?
Aber das ist ziemlich kompliziert, weil die Struktur jeder KI-Website anders ist und es verschiedene Schutzmechanismen gibt, die man analysieren muss, um ihre DOM-Struktur zu verstehen.
Also habe ich diese komplexe Aufgabe an GLM-5 delegiert.
Ich habe den Plan Mode von Claude Code aktiviert, um zuerst einen Plan erstellen zu lassen.
Dann interagiert es auch mit mir und fragt nach meiner Meinung:
Der endgültige Plan ist sehr detailliert, wirklich zu lang, er hat 633 Zeilen..
Dann begann es, den Plan Schritt für Schritt auszuführen, aber unerwartet dauerte der erste Schritt, die Initialisierung des Projekts, mehr als 50 Minuten..
In diesem Prozess rief es automatisch das Playwright MCP-Tool auf und öffnete selbstständig den Browser, um die Websites der KIs zu besuchen.
Es ist wie ein echter Programmierer, der Elemente überprüft, analysiert, wo sich das Eingabefeld befindet, welche Klasse die Sendeschaltfläche hat, wie man den zurückgegebenen Textstrom erhält... Der ganze Prozess ist vollautomatisch, ich habe keine einzige Zeile Code geschrieben.
PS: Ich habe vergessen, den Bildschirm aufzunehmen, weil ich gleichzeitig eine andere Aufgabe in anderen Fenstern ausgeführt habe.
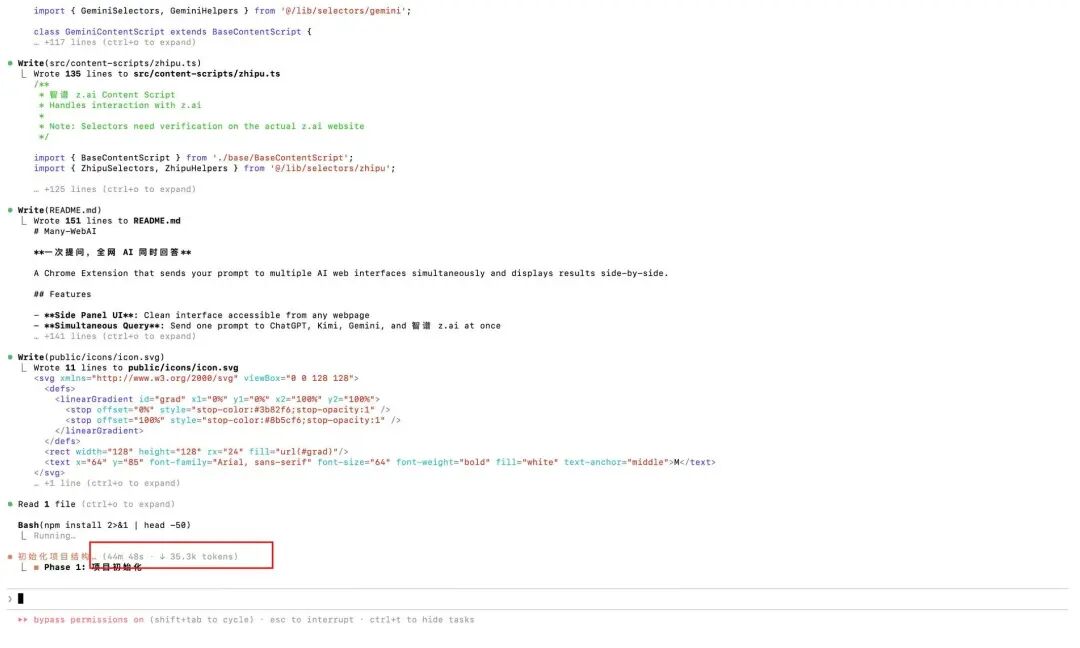 Das Warten hat sich gelohnt, das Plugin, das ich wollte, mit einer einzigen Frage, die gleichzeitig von allen KIs im Internet beantwortet wird, ist soeben entstanden.
Das Warten hat sich gelohnt, das Plugin, das ich wollte, mit einer einzigen Frage, die gleichzeitig von allen KIs im Internet beantwortet wird, ist soeben entstanden.
Das ist genau das, was ich brauche~
Außerdem, ich habe doch zuvor eine Plattform zur automatischen Erstellung von digitalen Marketingvideos erstellt.
Um eine bessere Benutzererfahrung zu erzielen, habe ich das Frontend neu aufgebaut. Dieser Umbau war jedoch problematisch, das gesamte Projekt war ein einziges Chaos: Frontend- und Backend-Schnittstellen stimmten nicht überein, einige alte Backend-Logiken funktionierten im neuen Frontend nicht, es gab viele Bugs, was die Arbeit sehr mühsam machte.
Dieses Mal habe ich in Claude Code den Plan Mode aktiviert und GLM-5 direkt mit der Aufgabe betraut, die Hauptprozesse zu finden und zu beheben.
Zuerst wurde ein detaillierter Plan erstellt:
Nachdem ich den Plan bestätigt hatte, ließ ich ihn Schritt für Schritt mit der Ausführung beginnen (wobei das Browser-MCP zur Steuerung verwendet wurde).
Seine Ausführungsgeschwindigkeit ist nicht hoch.
Aber es liegt nicht an der Langsamkeit des Modells, oft sehe ich, wie die Token-Verbrauchsrate mit bloßem Auge in einer Sekunde auf Tausende steigt.
Da die Aufgabe jedoch zu komplex ist, muss es ständig selbst reflektieren, Tools aufrufen und Tests durchführen.
Einige Zeit wird auch für das Herunterladen von Abhängigkeiten oder das Ausführen von Befehlen aufgewendet.
Diese Reparaturaufgabe dauerte ebenfalls mehr als 40 Minuten.
Manche Freunde mögen sagen: 40 Minuten? Das hätte ich schon fertig geschrieben.
Emmm, aber in diesen 40 Minuten habe ich die Bildschirmaufnahme laufen lassen, Videos geschaut und sogar den Hund ausgeführt.
Und es hat sich voll und ganz darauf konzentriert, mir zu helfen, und zwar bei der Art von Arbeit, die einem die Haare raufen lässt, nämlich dem Finden und Umstrukturieren von Fehlern.
Auch wenn die Ausführung langsam ist, ist das Endergebnis sehr bemerkenswert.
Als ich es ausführte, waren die Probleme im Wesentlichen behoben.
Bitte sehen Sie sich das VCR an:
Einige der Effekte habe ich erst später beim Testen selbst entdeckt und es dann reparieren und optimieren lassen.
Aber in Bezug auf die Fehlerbehebung und Funktionsoptimierung vertraue ich ihm wirklich.
Früher, als ich andere KIs zur Fehlerbehebung einsetzte, hatte ich oft Angst, dass immer mehr Fehler auftauchen und das Projekt immer chaotischer wird, typisch für das Stopfen von Löchern an einer Stelle, indem man an einer anderen Stelle etwas wegnimmt..
Um dieses Problem zu vermeiden, musste man die KI mit verschiedenen Engineering-Methoden einschränken.
Zum Beispiel, indem man jedes Mal den Umfang der Änderung betonte, oder diese in Regeln schrieb, oder jedes Mal nur einen Fehler behob und nach jeder Änderung andere Funktionen testete... Auf jeden Fall war es sehr mühsam.
Aber die Erfahrung mit der Fehlerbehebung mit GLM-5 hat sich völlig verändert.
Ich musste nur den aktuellen Zustand beschreiben, ihm die Fehlerprotokolle geben und ihm sagen, welches Ergebnis ich erwarte.
Es konnte fast immer erfolgreich reparieren, ohne andere Funktionen zu beeinträchtigen.
Ich habe sogar in einem Gespräch alle vier verschiedenen Fehler, die ich im gesamten Prozess gefunden habe, auf einmal hineingeworfen, und es konnte sie alle klar und deutlich nacheinander beheben.
Dieses Gefühl der Stabilität ist wirklich angenehm.
Ich kann GLM-5 jetzt getrost mit der Erledigung komplexer Entwicklungsaufgaben betrauen, ohne dass es zu Fehlern kommt.
Selbst wenn es gelegentlich Probleme gibt, kann ich einfach den Rollback-Befehl in Claude Code ausführen und von vorne beginnen.
Nachdem das gesamte Projekt mit GLM-5 optimiert wurde, sind alle Prozesse im Wesentlichen abgeschlossen.Ich bereite mich auch darauf vor, dieses Projekt bald als Open Source zu veröffentlichen (ich muss noch verschiedene Modell-API-Bereiche extrahieren und in eine Konfiguration umwandeln).
„Zum Schluss“
Nachdem ich GLM-5 ausprobiert habe, ist mein größtes Gefühl: Chinesische KI ist wirklich aufgestanden.
Vor ein paar Tagen wurde Seedance 2.0 von ByteDance veröffentlicht, was bewies, dass chinesische Modelle im Bereich der Videogenerierung bereits das weltweit führende Niveau erreicht haben und Sora2 und Veo3.1 direkt übertreffen.
Und die Veröffentlichung von Zhipu GLM-5 hat in einem anderen Hardcore-Bereich, AI Coding, eine unerwartet gute Antwort geliefert.
Wir sagten früher immer, dass chinesische Modelle in Bezug auf logisches Denken und das Schreiben von Code immer noch eine Lücke zu GPT, Claude Opus und Gemini haben.
Aber heute sagt uns GLM-5 mit konkreten Ergebnissen: Diese Lücke wird geschlossen.
GLM-5 ist auch kein Spielzeug, das nur für Demos verwendet werden kann, sondern ein Produktivitätstool, das Ihnen wirklich bei der Arbeit helfen, Systeme aufbauen, lange Aufgaben lösen und komplexe Probleme bewältigen kann.
Das Wichtigste ist, dass es Open Source ist.
Dies bedeutet, dass jeder Entwickler, jedes Unternehmen, einen erstklassigen KI-Architekten zu geringeren Kosten haben kann.
Und derzeit ist der GLM Coding Plan bereits ausverkauft. Die offizielle Ankündigung besagt, dass die Kapazität dringend erweitert wird, und der Schwerpunkt liegt darauf, dass diesmal ein Cluster mit zehntausend Karten von inländischen Chips angeschlossen wird.
Aufgrund der erhöhten Investitionen in die Rechenleistung ist der Preis jedoch etwas gestiegen. Zum Glück habe ich vorher das Max-Paket bekommen.
Hier kann man auch sehen, dass wir, vom Chip bis zum Modell, von der zugrunde liegenden Rechenleistung bis zur oberen Anwendung, einen vollständig eigenen, erstklassigen KI-Technologie-Stack aufbauen.
2026 wird definitiv ein Jahr der Explosion von KI-Anwendungen und auch ein verrückteres Jahr sein.
Wenn Sie auch das Gefühl haben möchten, einen erstklassigen KI-Architekten zu haben, probieren Sie GLM-5 aus.Voraussetzung ist, dass du dir das Max-Paket sichern kannst, haha.



