智谱GLM-5 esta vez de código abierto, incluso los programadores senior están en peligro...
De verdad, la IA de 2026 está mucho más loca que la de 2025.
Últimamente, incluso yo, que paso 16 horas al día metido en la IA, tengo problemas para seguir el ritmo de la evolución de la IA. Siento que cada vez que abro los ojos, el mundo ha cambiado.
Y ahora, anoche, Zhipu lanzó otro gran movimiento, directamente abriendo el código de su modelo insignia más potente actual: GLM-5.
En la lista autorizada mundial de Artificial Analysis, ¡GLM-5 superó a Gemini y alcanzó el cuarto lugar mundial, el primero de código abierto!
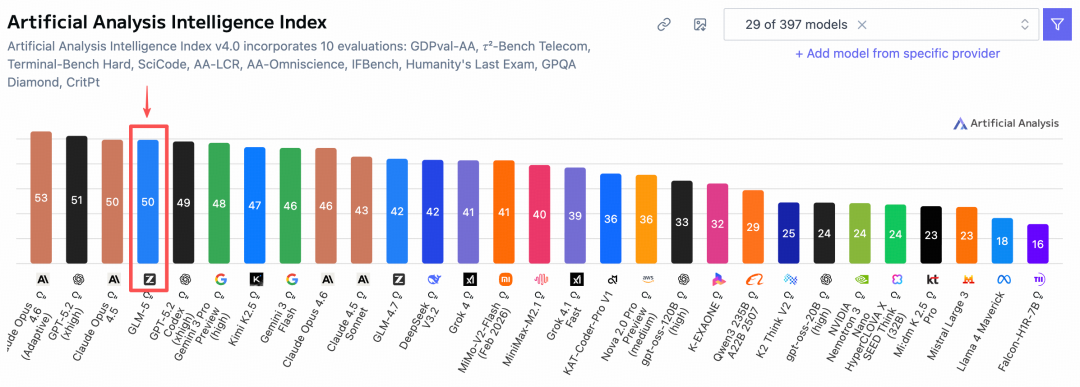
Como predije, recuerdo que cuando se lanzó GLM-4.7, hice una predicción con los hermanos en el artículo: Adivinando a ciegas que GLM-4.8 o GLM-5 se lanzarían antes del Festival de Primavera, no esperaba que realmente llegara, jaja 😄
Y esta vez, el número de versión finalmente no es como las actualizaciones anteriores de 4.5, 4.6, 4.7, esta vez llegó directamente a 5.0.
Esto muestra que no es una pequeña reparación, sino un gran salto en la capacidad de la base.
Primero, permítanme presentarles, ¿qué actualizó GLM-5 esta vez?:
En pocas palabras, los modelos anteriores, todos estaban generalmente enrollando Vibe Coding, que es la llamada generación de una oración, viendo quién genera efectos especiales de página web más geniales, viendo quién puede crear un juego genial con una oración.
Pero GLM-5 esta vez no se enrolla contigo en esto (¡finalmente!), elevó la capacidad del modelo grande de escribir código a poder construir sistemas.
¿Qué significa esto? Su enfoque ya no está en escribir hermosas páginas front-end, sino que ha evolucionado hasta convertirse en un arquitecto de sistemas que puede hacer el trabajo sucio, el trabajo duro y las tareas largas.
Lo que se enfatiza es Agentic Engineering, es decir, la capacidad de ingeniería de agentes inteligentes.
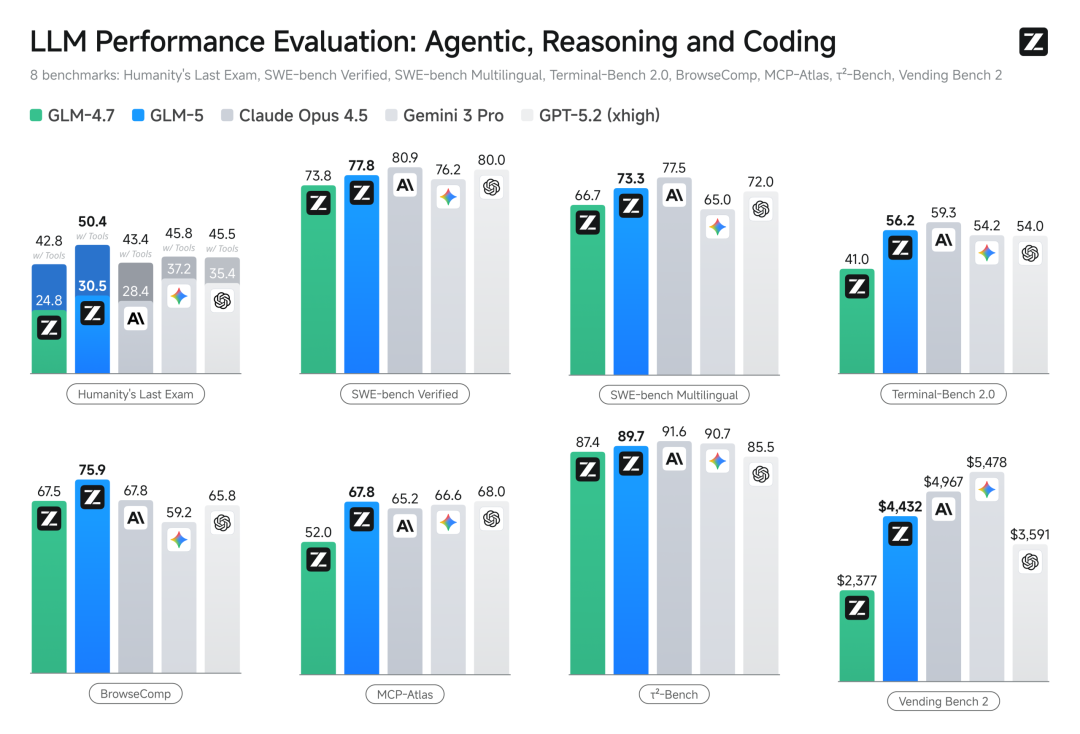
Eché un vistazo a los datos oficiales, la escala de parámetros aumentó de 355B a 744B (activación 40), los datos de preentrenamiento aumentaron de 23T a 28.5T.
En la prueba de referencia de programación reconocida SWE-bench-Verified, la puntuación fue de 77.8, superando directamente a Gemini 3 Pro, y se puede decir que está a la par con el modelo de código cerrado más potente reconocido actualmente, Claude Opus 4.5.
Actualmente, se puede usar gratis en z.ai:
Dirección de código abierto:
GitHub: https://github.com/zai-org/GLM-5
Hugging Face: https://huggingface.co/zai-org/GLM-5
ModelScope: https://modelscope.cn/models/ZhipuAI/GLM-5
De hecho, hace unos días, un modelo misterioso llamado Pony apareció repentinamente en X.
En ese momento, muchos amigos estaban adivinando, ¿qué tipo de dios es este Pony? Había muchas opiniones diferentes.
De hecho, el modelo con el nombre en código Pony es GLM-5, en cuanto a por qué se llama Pony, probablemente porque el Año del Caballo está a la vuelta de la esquina 🤔.
También conecté Pony a Claude Code desde OpenRouter la primera vez para probarlo, para ser honesto, es realmente muy fuerte (la popularidad en X también es muy alta).
¡Solo tomó 7 minutos para generar una estación de retransmisión de API a la vez!
Aunque todavía es MVP Demo, las funciones de la página ya están muy completas e incluyen lógica de backend y base de datos, los datos son dinámicos, aunque pequeño, tiene todo lo necesario.
 Después de una experiencia profunda, descubrí que GLM-5, al hacer planes, ese sabor, es muy parecido a Claude Opus.
Después de una experiencia profunda, descubrí que GLM-5, al hacer planes, ese sabor, es muy parecido a Claude Opus.
Los amigos que están familiarizados con Claude Opus saben que, antes de hacer el trabajo, puede usarlo para enumerar un plan muy detallado y lógicamente riguroso.
GLM-5 ahora también tiene esta capacidad.
Por ejemplo, tengo algo que siempre he querido hacer, pero que no he hecho porque soy perezoso.
Tengo un montón de cuentas de membresía de Gemini, ChatGPT, Kimi, Zhipu, etc.
Por lo general, cuando escribo artículos o busco información, a menudo quiero escuchar las opiniones de múltiples IA sobre algunos problemas y compararlas integralmente.Entonces tendría que abrir varias ventanas del navegador, copiar, cambiar entre diferentes ventanas, pegar y enviar varias veces, y luego cambiar entre las ventanas para ver los resultados.
Aunque no es gran cosa, pero cuando se hace muchas veces, es realmente molesto.
Estaba pensando, ¿se podría hacer un plugin para el navegador que pueda enviar la misma pregunta a las páginas web de estas cuatro IA simultáneamente en una sola ventana, y luego recibir las respuestas de forma unificada en el plugin?
Pero esto es bastante complicado, porque la estructura de cada sitio web de IA es diferente, y también hay varios mecanismos de protección, que requieren analizar sus estructuras DOM.
Así que le encargué esta compleja tarea a GLM-5.
Activé el Plan Mode de Claude Code para que hiciera un plan primero.
Luego también interactuó conmigo, preguntándome mi opinión:
El plan final obtenido fue muy detallado, realmente muy largo, con 633 líneas..
Luego comenzó a ejecutarlo según el plan, pero no esperaba que el primer paso de inicialización del proyecto tardara más de 50 minutos...
En este proceso, llamó automáticamente a la herramienta Playwright MCP, abrió el navegador por sí mismo y visitó los sitios web de esas IA.
Es como un verdadero programador, revisando los elementos, analizando dónde está el cuadro de entrada, cuál es la clase del botón de envío, cómo obtener el flujo de texto de retorno... todo el proceso es completamente automático, no escribí ni una sola línea de código.
PD: Olvidé grabar la pantalla, porque también estaba ejecutando otra tarea en otra ventana al mismo tiempo.
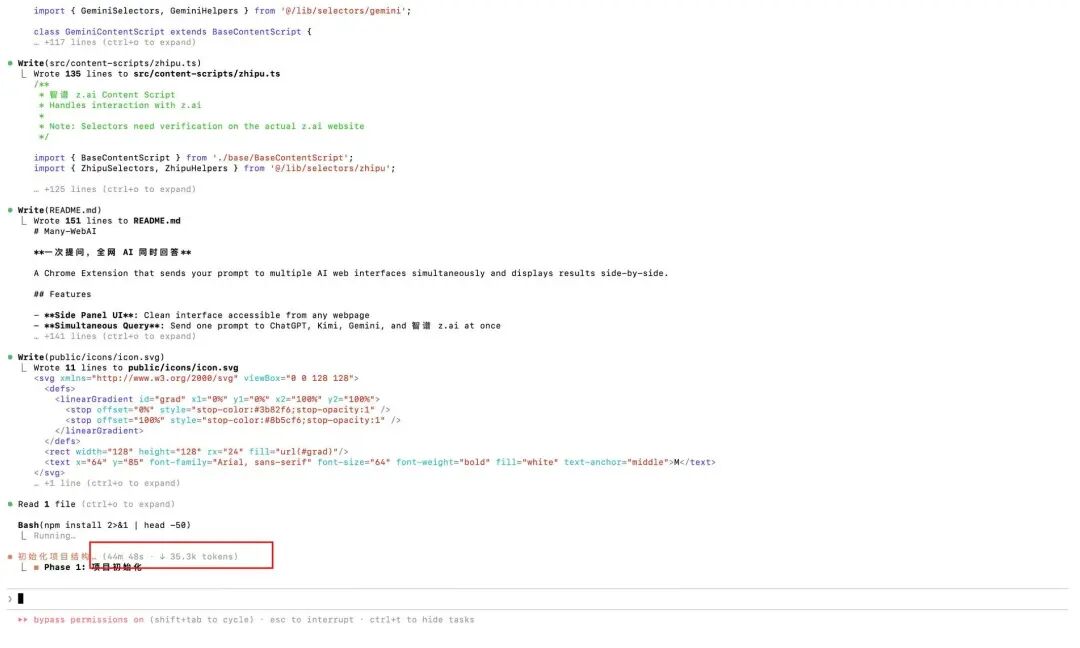 La espera valió la pena, el plugin que quería, que me permitiera hacer una pregunta y obtener respuestas de todas las IA de la red al mismo tiempo, salió recién hecho.
La espera valió la pena, el plugin que quería, que me permitiera hacer una pregunta y obtener respuestas de todas las IA de la red al mismo tiempo, salió recién hecho.
Esto es exactamente lo que necesitaba~
Además, antes había hecho una plataforma para generar videos de marketing con humanos digitales con un solo clic.
Más tarde, para buscar una mejor experiencia, reestructuré el frontend, y esta reestructuración causó un gran caos en todo el proyecto: las interfaces del frontend y el backend no coincidían, algunas lógicas antiguas del backend no funcionaban con el nuevo frontend, había muchos errores, y era muy complicado arreglarlo.
Esta vez, activé el plan mode en Claude Code, y le encargué directamente a GLM-5 la tarea de encontrar y corregir errores en el flujo principal.
Primero salió un plan detallado:
Después de confirmar que el plan era correcto, lo dejé empezar a ejecutarlo (en el proceso se utilizó el navegador mcp para controlar).
Su velocidad de ejecución no es rápida.
Pero no es que el modelo sea lento, muchas veces, veo que la velocidad de consumo de Token se dispara a miles por segundo a simple vista.
Pero debido a que la tarea es demasiado compleja, necesita auto-reflexionar constantemente, llamar a herramientas y ejecutar pruebas.
También hay algo de tiempo que se consume en la descarga de dependencias o en la ejecución de comandos.
Esta tarea de reparación también tardó más de 40 minutos.
Algunos amigos podrían decir, ¿40 minutos? Ya lo habría escrito.
emmm, pero en estos 40 minutos, estuve viendo la grabación de pantalla, viendo videos e incluso paseando al perro.
Y él estaba concentrado en ayudarme a hacer el trabajo, y además haciendo el tipo de trabajo más doloroso de encontrar errores y reestructurar.
No importa que se ejecute lentamente, pero el efecto final es muy significativo.
Lo ejecuté, y ¡vaya!, los problemas estaban básicamente resueltos.
Por favor, vean el VCR:
También hay algunos efectos que descubrí cuando probé pequeños errores más tarde, y luego le pedí que los reparara y optimizara.
Pero en la reparación de errores y la optimización de funciones, realmente me siento seguro de dejarlo en sus manos.
Antes, cuando usaba otras IA para corregir errores, a menudo me preocupaba que se crearan más errores, y que el proyecto se volviera más caótico, típicamente tapando un agujero y abriendo otro..
Antes, para evitar este problema, tenía que usar varios medios de ingeniería para restringir la IA.
Por ejemplo, enfatizar el alcance de cada modificación, o escribir esto en las reglas, o solo corregir un error cada vez, y después de cada modificación, tenía que probar otras funciones... de todos modos, era muy molesto.
Pero usar GLM-5 para corregir errores, la experiencia ha cambiado por completo.
Nunca necesito más que describir la situación actual, darle los registros de errores y decirle cuál es el efecto que espero.
Casi siempre puede repararlo con éxito de una sola vez, y no afecta en absoluto a otras funciones.
Incluso, en una conversación, le lancé directamente los cuatro errores diferentes que encontré en todo el proceso, y pudo arreglarlos uno por uno de forma clara.
Esta sensación de estabilidad es realmente muy cómoda.
Ahora puedo confiar en GLM-5 para que me ayude a completar cualquier tarea de desarrollo compleja, básicamente sin errores.
Incluso si hay problemas ocasionales, puedo ejecutar un comando de reversión en Claude Code y volver a empezar.
Después de optimizar todo el proyecto con GLM-5, todos los procesos están básicamente resueltos.También planeo hacer este proyecto de código abierto muy pronto (todavía necesito extraer la parte de la API de varios modelos y convertirla en configuración).
«Finalmente»
Después de experimentar GLM-5, mi mayor sentimiento es: La IA china realmente se ha puesto de pie.
Hace unos días, se lanzó Seedance 2.0 de ByteDance, lo que demuestra que los modelos chinos nacionales han alcanzado el nivel número uno del mundo en el campo de la generación de video, superando directamente a Sora2 y Veo3.1.
Y esta vez, el lanzamiento de GLM-5 de Zhipu ha entregado una respuesta inesperada en otra pista central, la codificación de IA.
Solíamos decir que los modelos nacionales tenían una brecha con GPT, Claude Opus y Gemini en el razonamiento lógico y la escritura de código.
Pero hoy, GLM-5 nos dice con un rendimiento sólido: esta brecha se está cerrando.
GLM-5 no es solo un juguete que se puede usar para demostraciones, es una herramienta de productividad que realmente puede ayudarlo a hacer el trabajo, ayudarlo a construir sistemas y ayudarlo a resolver tareas largas y problemas complejos.
Lo más importante es que es de código abierto.
Esto significa que cada desarrollador, cada empresa, puede tener un arquitecto de IA de primer nivel a un costo menor.
Y actualmente, el Plan de Codificación de GLM ya se ha agotado. Los funcionarios han anunciado que se están expandiendo urgentemente, y el punto clave es que esta vez se está accediendo a un clúster de diez mil tarjetas de chips nacionales.
Sin embargo, debido al aumento de la inversión en potencia informática, el precio ha aumentado un poco, pero afortunadamente obtuve el paquete Max antes.
Aquí también podemos ver que, desde los chips hasta los modelos, desde la potencia informática subyacente hasta las aplicaciones de nivel superior, estamos construyendo un conjunto de pila de tecnología de IA de clase mundial que es completamente nuestra.
2026 está destinado a ser un año de explosión de aplicaciones de IA, y también un año más loco.
Si también quieres experimentar la sensación de tener un arquitecto de IA de primer nivel, date prisa y prueba GLM-5.El requisito es que puedas conseguir el paquete Max, jaja.



