智谱GLM-5这次开源,让高级程序员也危险了...
真的,2026年的AI比25年疯太多了。
最近我这个一天16个小时泡在AI里面的人,都有点追不上AI进化的速度。感觉每天一睁眼,世界就变了个样。
这不,昨天深夜,智谱又放了个大招,直接开源了他们目前最强的旗舰模型:GLM-5。
在全球权威的Artificial Analysis榜单里面,GLM-5超越Gemini干到了全球第四、开源第一!
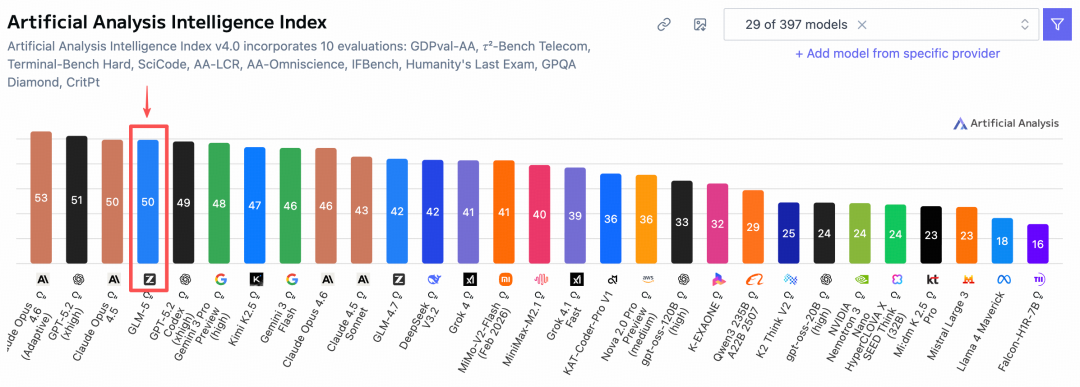
还真是如我所料啊,记得上次GLM-4.7发布的时候,我就在文章里跟兄弟们预测了一波:盲猜GLM-4.8或者GLM-5将在春节前夕发布,没想到真来了,哈哈😄
而且这次的版本号终于不像之前那样4.5、4.6、4.7这样挤牙膏式的更新了,这次直接干到了5.0。
这就说明,不是什么小修小补,是底座能力的大跨越。
先给大家介绍一下,这次GLM-5到底更新了啥:
简单来说,之前的模型,大家普遍都在卷Vibe Coding,就是所谓的一句话生成,看谁生成的网页特效更炫酷,看谁能一句话搓个炫酷的游戏。
但GLM-5这次不跟你卷这个了(终于!),它把大模型的能力从写代码,提升到能构建系统。
什么意思呢?它的重心不再是写漂亮的前端页面,而是进化成了一个能干脏活、累活、做长任务的系统架构师。
强调的是Agentic Engineering,也就是智能体工程能力。
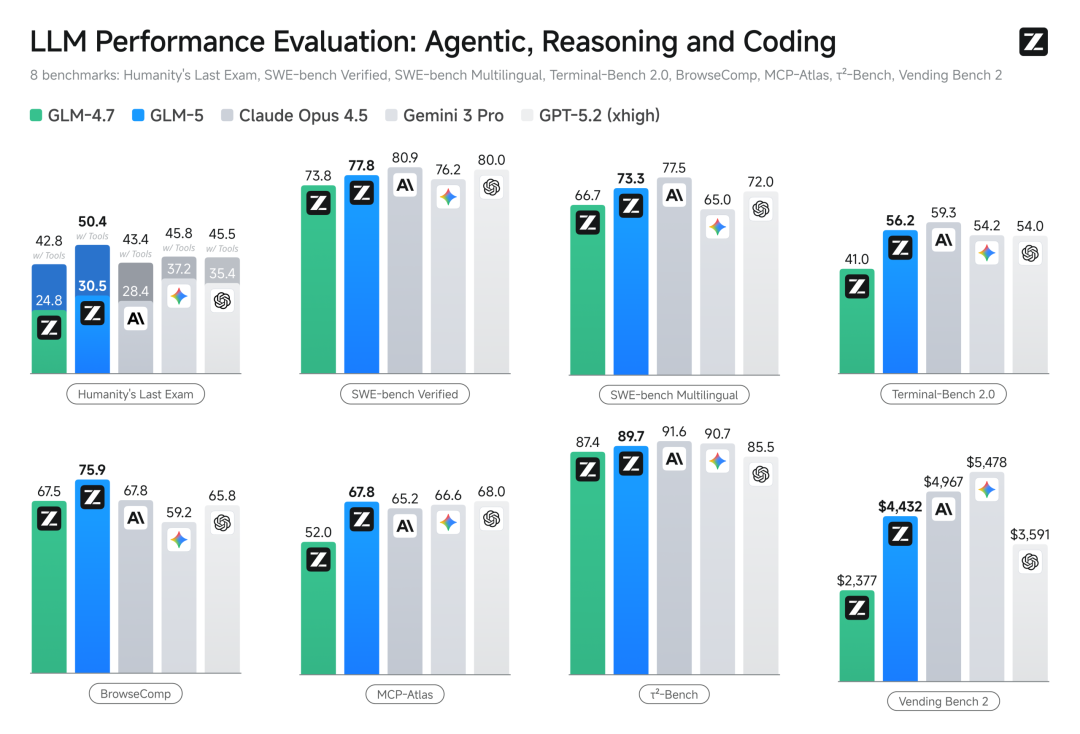
我看了下官方的数据,参数规模从355B干到了744B(激活40),预训练数据从23T提升到了28.5T。
在SWE-bench-Verified这个公认的编程基准测试里,得分77.8,直接把Gemini 3 Pro甩在了身后,和目前公认的最强闭源模型Claude Opus 4.5可以说是不相上下。
目前在z.ai上面就可以免费使用:
开源地址:
GitHub:https://github.com/zai-org/GLM-5
Hugging Face:https://huggingface.co/zai-org/GLM-5
ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5
其实在前几天,X上就突然冒出来一个叫Pony的神秘模型。
当时很多朋友都在猜,这个Pony到底是哪路神仙?众说纷纭
其实代号Pony的模型就是GLM-5,至于为什么叫Pony呢,大概是因为马年快到了吧🤔。
我当时也第一时间从OpenRouter把Pony接入到Claude Code里试用了一下,说实话,真滴很强(在X上热度也是非常高)。
只花了7分钟,一次性生成了一个API中转站!
虽然还是MVP Demo,但是页面功能已经很齐全了,而且包含后端逻辑,以及数据库,数据是动态的,麻雀虽小五脏俱全。
 在深度体验后,我发现GLM-5在制定计划的时候,那种味道,太像Claude Opus了。
在深度体验后,我发现GLM-5在制定计划的时候,那种味道,太像Claude Opus了。
熟悉Claude Opus的朋友都知道,在干活之前,可以用它会给你列一个非常详细、逻辑严密的计划。
GLM-5现在也有了这个能力。
比如,我有一个一直想做,但是因为懒一直没动手的事儿。
我手头有Gemini、ChatGPT、Kimi、智谱等等一堆会员账号。
平时写文章或者查资料的时候,有些问题我经常会想听听多个AI的意见,综合对比一下。 Nå måtte jeg åpne flere nettleservinduer, kopiere og bytte mellom forskjellige vinduer for å lime inn og sende flere ganger, og deretter bytte mellom vinduer for å sjekke resultatene.
Selv om det ikke er en stor sak, er det veldig irriterende når det gjøres mange ganger.
Jeg tenkte, kan jeg lage en nettleserutvidelse som kan sende det samme spørsmålet til nettsidene til disse fire AI-ene samtidig i ett vindu, og deretter motta svarene samlet i utvidelsen?
Men dette er ganske vanskelig, fordi strukturen til hver AI-nettside er forskjellig, og det er forskjellige beskyttelsesmekanismer, så jeg må analysere deres DOM-struktur.
Så jeg overlot denne komplekse oppgaven til GLM-5.
Start Claude Code's Plan Mode for å la den lage en plan først
Så vil den samhandle med meg og spørre om mine meninger:
Den endelige planen er veldig detaljert, virkelig for lang, med 633 linjer..
Så begynte den å utføre i henhold til planen, men jeg forventet ikke at det første trinnet med å initialisere prosjektet ville ta mer enn 50 minutter..
I løpet av denne prosessen kalte den automatisk opp Playwright MCP-verktøyet og åpnet nettleseren selv for å besøke de AI-nettsidene.
Det er som en ekte programmerer, som sjekker elementer, analyserer hvor inndataboksen er, hva klassen til sendeknappen er, hvordan man får den returnerte tekststrømmen... hele prosessen er helautomatisk, jeg skrev ikke en eneste kodelinje.
PS: Glemte å ta opp skjermen, fordi jeg kjørte en annen oppgave i andre vinduer samtidig
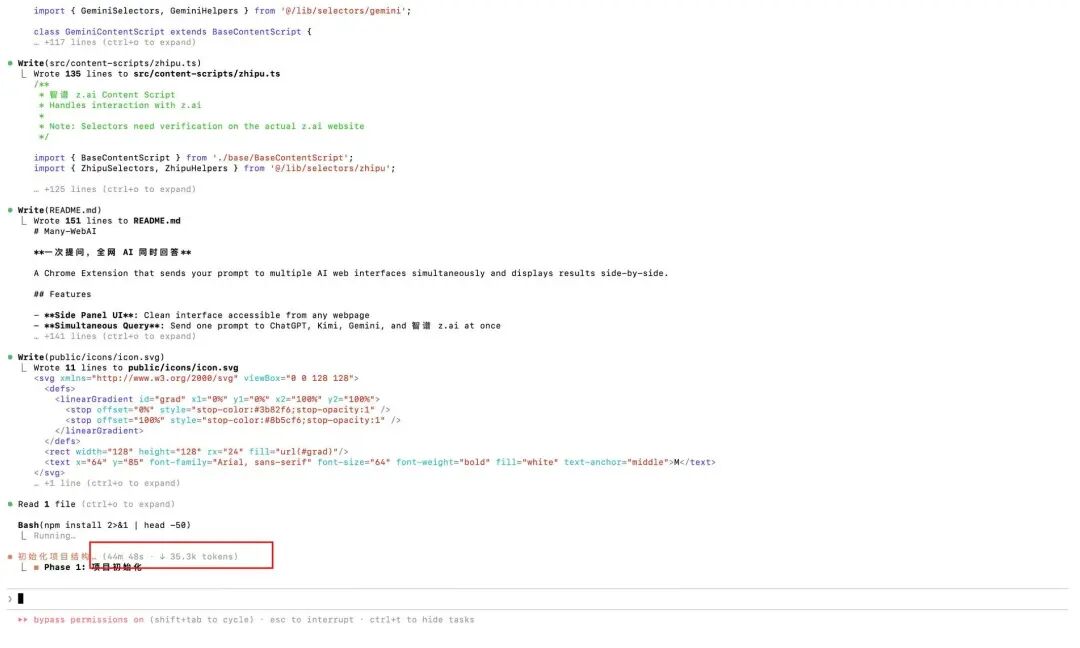 Ventingen er verdt det, utvidelsen jeg ønsket, som lar meg stille ett spørsmål og få svar fra alle AI-ene samtidig, er endelig her.
Ventingen er verdt det, utvidelsen jeg ønsket, som lar meg stille ett spørsmål og få svar fra alle AI-ene samtidig, er endelig her.
Dette er akkurat det jeg trenger~
I tillegg, jeg lagde jo en plattform for å generere digitale markedsføringsvideoer med ett klikk tidligere.
Senere, for å oppnå en bedre opplevelse, omstrukturerte jeg frontenden, og denne omstruktureringen gjorde hele prosjektet til et rot: frontend- og backend-grensesnittene stemte ikke overens, noen gamle backend-logikker fungerte ikke med den nye frontenden, det var mange feil, og det var veldig vanskelig å fikse.
Denne gangen startet jeg plan mode i Claude Code, og overlot oppgaven med å finne og fikse feil i hovedflyten direkte til GLM-5
Først kom det ut en detaljert plan:
Etter å ha bekreftet at planen var korrekt, lot jeg den begynne å utføre (brukte nettleser-mcp for å kontrollere i prosessen).
Utførelseshastigheten er ikke rask.
Men det er ikke modellen som er treg, mange ganger ser jeg at forbruket av Token skyter i været til tusenvis per sekund.
Men fordi oppgaven er for kompleks, må den kontinuerlig reflektere over seg selv, kalle opp verktøy og kjøre tester.
Noe tid brukes også på å laste ned avhengigheter eller utføre kommandoer.
Denne reparasjonsoppgaven tok også hele 40 minutter.
Noen venner vil kanskje si, 40 minutter? Jeg hadde allerede skrevet det ferdig.
Emmm, men i disse 40 minuttene hadde jeg skjermopptak på, så på videoer og til og med gikk tur med hunden.
Og den jobbet hardt for å hjelpe meg, og gjorde det mest hodepinefremkallende arbeidet med å finne feil og omstrukturere.
Ikke se på at den utfører sakte, men den endelige effekten er veldig betydelig.
Jeg kjørte den, og jammen, problemene var i utgangspunktet løst.
Se VCR:
Noen av effektene her ble oppdaget av meg selv da jeg testet senere, og jeg lot den fikse og optimalisere dem.
Men når det gjelder å fikse feil og optimalisere funksjoner, er jeg virkelig trygg på å overlate det til den.
Tidligere, da jeg brukte andre AI-er til å fikse feil, var jeg ofte bekymret for at flere og flere feil ville bli introdusert, og at prosjektet ville bli mer og mer rotete, typisk for å ta fra Peter for å betale Paul..
For å unngå dette problemet tidligere, måtte jeg bruke forskjellige ingeniørmetoder for å begrense AI-en.
For eksempel å understreke omfanget hver gang jeg gjorde en endring, eller skrive dette inn i reglene, eller bare endre en feil om gangen, og teste andre funksjoner etter hver endring... uansett, det var veldig vanskelig.
Men opplevelsen av å bruke GLM-5 til å fikse feil er helt annerledes.
Jeg trenger bare å beskrive situasjonen, kaste feilloggene til den og fortelle den hva jeg forventer av effekten.
Den kan nesten fikse det vellykket en gang, og det vil ikke påvirke andre funksjoner i det hele tatt.
Jeg kan til og med kaste alle de fire forskjellige feilene jeg fant i hele prosessen til den i en samtale, og den kan fikse dem en etter en på en ryddig måte.
Denne følelsen av stabilitet er virkelig for behagelig.
Jeg kan nå trygt overlate GLM-5 til å hjelpe meg med å fullføre komplekse utviklingsoppgaver, og det vil i utgangspunktet ikke være noen feil.
Selv om det er problemer av og til, kan jeg like gjerne utføre en tilbakerullingskommando i Claude Code og gå tilbake og starte på nytt.
Etter å ha optimalisert hele prosjektet med GLM-5, er alle prosessene i utgangspunktet løst.Jeg planlegger også å åpne kildekoden for dette prosjektet snart (trenger fortsatt å trekke ut de forskjellige modell-API-ene og gjøre dem om til konfigurasjon).
«Til slutt»
Etter å ha opplevd GLM-5, er min største følelse: Kinesisk AI har virkelig reist seg.
For et par dager siden ble ByteDance sin Seedance 2.0 lansert, noe som beviste at kinesiske modeller innen videogenerering allerede har nådd verdensklasse, og direkte overgår Sora2 og Veo3.1.
Og denne lanseringen av Zhipu GLM-5 leverer et uventet godt svar på et annet hardbarket felt, AI-koding.
Vi pleide å si at kinesiske modeller hadde et gap i logisk resonnement og koding sammenlignet med GPT, Claude Opus og Gemini.
Men i dag forteller GLM-5 oss med konkrete resultater: Dette gapet blir utjevnet.
GLM-5 er ikke bare et leketøy som kan brukes til å lage demoer, det er et produktivitetsverktøy som virkelig kan hjelpe deg med å få ting gjort, bygge systemer og løse lange oppgaver og komplekse problemer.
Det viktigste er at det er åpen kildekode.
Dette betyr at hver utvikler, hver bedrift, kan ha en topp AI-arkitekt til en lavere kostnad.
Og for øyeblikket er GLMs Coding Plan allerede utsolgt. Offisielle kunngjøringer sier at de utvider kapasiteten raskt, og viktigst av alt, denne gangen kobles de til en kinesisk chipbasert klynge med titusenvis av kort.
Men på grunn av den økte investeringen i datakraft, har prisen økt noe, men heldigvis fikk jeg Max-pakken tidligere.
Her kan vi også se at fra chips til modeller, fra underliggende datakraft til applikasjoner på øverste nivå, bygger vi et fullstendig eget, verdensledende AI-teknologistack.
2026 er skjebnebestemt til å bli et år med eksplosjon av AI-applikasjoner, og også et mer vanvittig år.
Hvis du også vil oppleve følelsen av å ha en topp AI-arkitekt, skynd deg og prøv GLM-5.Forutsetningen er at du må kapre Max-pakken, haha.



