智谱GLM-5 deze keer open source, maakt zelfs senior programmeurs onzeker...
Echt waar, de AI van 2026 is veel gekker dan die van 2025.
De laatste tijd kan ik, die 16 uur per dag in AI zit, de evolutie van AI nauwelijks bijhouden. Het voelt alsof de wereld elke dag verandert als ik mijn ogen open.
En ja hoor, gisteravond laat heeft Zhipu weer een grote stap gezet en hun momenteel sterkste vlaggenschipmodel, GLM-5, direct open source gemaakt.
Op de wereldwijd gezaghebbende Artificial Analysis-lijst heeft GLM-5 Gemini overtroffen en de vierde plaats wereldwijd en de eerste open source plaats behaald!
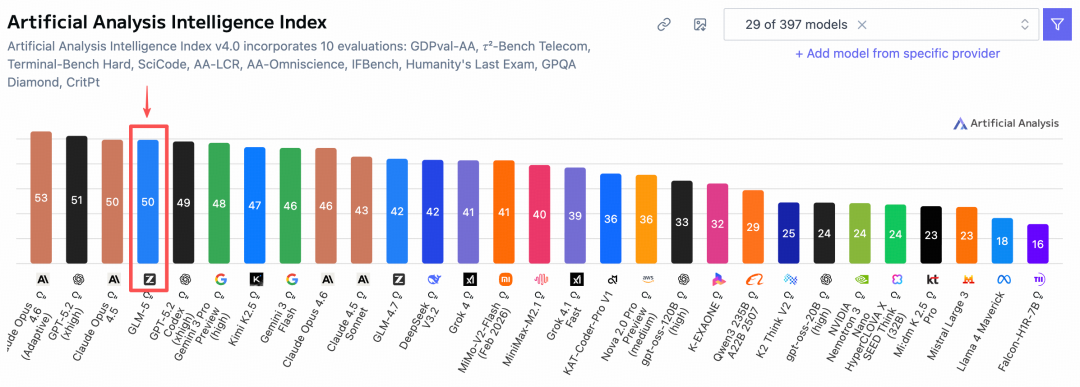
Het is echt zoals ik al dacht, ik herinner me dat toen GLM-4.7 werd uitgebracht, ik in het artikel al voorspelde aan mijn broeders: ik gok dat GLM-4.8 of GLM-5 vlak voor het Lentefestival zal worden uitgebracht, ik had niet verwacht dat het echt zou gebeuren, haha 😄
En deze keer is het versienummer eindelijk niet meer zo'n knijp-tandpasta-achtige update als voorheen met 4.5, 4.6, 4.7, deze keer is het direct 5.0 geworden.
Dit betekent dat het geen kleine aanpassing is, maar een grote sprong voorwaarts in de basiscapaciteit.
Laat me je eerst vertellen wat GLM-5 deze keer precies heeft geüpdatet:
Simpel gezegd, de meeste modellen waren voorheen bezig met Vibe Coding, de zogenaamde one-sentence generation, om te zien wie de meest coole web-special effects kan genereren, om te zien wie met één zin een coole game kan maken.
Maar GLM-5 doet deze keer niet mee aan deze race (eindelijk!), het heeft de mogelijkheden van het grote model uitgebreid van het schrijven van code tot het kunnen bouwen van systemen.
Wat betekent dit? De focus ligt niet langer op het schrijven van mooie front-end pagina's, maar is geëvolueerd tot een systeemarchitect die vuil werk, zwaar werk en lange taken kan uitvoeren.
De nadruk ligt op Agentic Engineering, oftewel de intelligentie-engineeringcapaciteit.
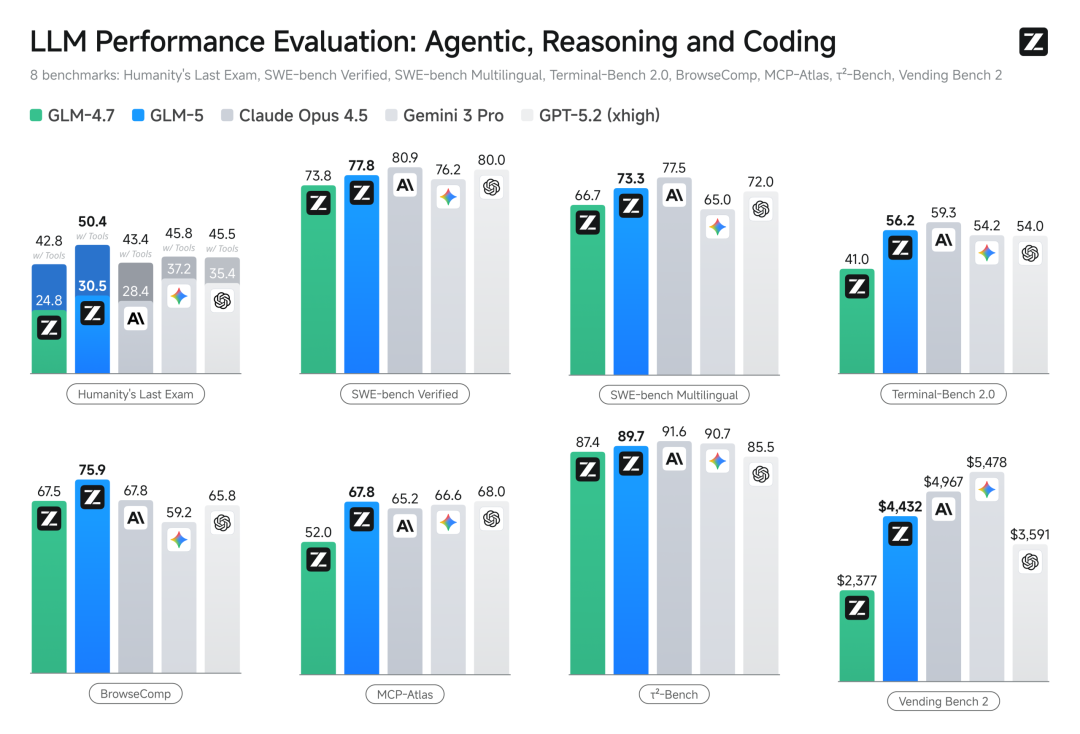
Ik heb de officiële gegevens bekeken, de parameterschaal is gestegen van 355B naar 744B (activering 40), de pre-training data is gestegen van 23T naar 28.5T.
In de algemeen erkende programmeerbenchmarktest SWE-bench-Verified scoort het 77.8, waardoor Gemini 3 Pro direct achter zich wordt gelaten, en het kan worden gezegd dat het vergelijkbaar is met het momenteel algemeen erkende sterkste closed-source model Claude Opus 4.5.
Het kan momenteel gratis worden gebruikt op z.ai:
Open source adres:
GitHub: https://github.com/zai-org/GLM-5
Hugging Face: https://huggingface.co/zai-org/GLM-5
ModelScope: https://modelscope.cn/models/ZhipuAI/GLM-5
In feite dook er een paar dagen geleden plotseling een mysterieus model genaamd Pony op X op.
Veel vrienden vroegen zich toen af, wat voor soort god is deze Pony? Er waren verschillende meningen.
In feite is het model met de codenaam Pony GLM-5, en de reden waarom het Pony wordt genoemd, is waarschijnlijk omdat het jaar van het paard eraan komt 🤔.
Ik heb Pony destijds ook meteen via OpenRouter aangesloten op Claude Code om het uit te proberen, eerlijk gezegd, het is echt heel sterk (de populariteit op X is ook erg hoog).
Het kostte slechts 7 minuten om in één keer een API-transitie station te genereren!
Hoewel het nog steeds een MVP Demo is, zijn de paginafuncties al compleet en bevatten ze backend-logica en een database, de gegevens zijn dynamisch, klein maar fijn.
 Na een diepgaande ervaring ontdekte ik dat GLM-5 bij het maken van plannen die smaak heeft, die erg lijkt op Claude Opus.
Na een diepgaande ervaring ontdekte ik dat GLM-5 bij het maken van plannen die smaak heeft, die erg lijkt op Claude Opus.
Vrienden die bekend zijn met Claude Opus weten dat je het kunt gebruiken om een zeer gedetailleerd en logisch plan te maken voordat je aan het werk gaat.
GLM-5 heeft nu ook deze mogelijkheid.
Ik heb bijvoorbeeld iets dat ik altijd al heb willen doen, maar waar ik vanwege luiheid nooit aan ben begonnen.
Ik heb een stapel lidmaatschapsaccounts van Gemini, ChatGPT, Kimi, Zhipu, enz.
Bij het schrijven van artikelen of het opzoeken van informatie, wil ik vaak de meningen van meerdere AI's horen over sommige vragen en ze uitgebreid vergelijken.Dan zou ik meerdere browservensters moeten openen, kopiëren, schakelen tussen verschillende vensters, plakken, meerdere keren verzenden en vervolgens om de beurt van venster wisselen om de resultaten te bekijken.
Hoewel het geen groot probleem is, is het echt vervelend als het vaak gebeurt.
Ik vroeg me af: zou het mogelijk zijn om een browserplug-in te maken die in één venster tegelijkertijd dezelfde vraag naar de webversies van deze vier AI's kan sturen en vervolgens de antwoorden in de plug-in kan ontvangen?
Maar dat is best lastig, omdat de structuur van elke AI-website anders is en er verschillende beschermingsmechanismen zijn. Het is noodzakelijk om hun DOM-structuur te analyseren.
Dus gaf ik deze complexe taak aan GLM-5.
Ik activeerde eerst de Plan Mode van Claude Code om een plan te laten maken.
Daarna zou het met me interageren en mijn mening vragen:
Het uiteindelijke plan was zeer gedetailleerd, echt te lang, met 633 regels..
Daarna begon het volgens het plan te werken, maar de eerste stap, het initialiseren van het project, duurde al meer dan 50 minuten..
Tijdens dit proces riep het automatisch de Playwright MCP-tool aan, opende zelf de browser en bezocht de websites van die AI's.
Het is net een echte programmeur, die elementen inspecteert, analyseert waar het invoerveld is, wat de klasse van de verzendknop is, hoe de geretourneerde tekststroom te verkrijgen... Het hele proces is volledig automatisch, ik heb geen enkele regel code geschreven.
PS: Ik ben vergeten het scherm op te nemen, omdat ik tegelijkertijd een andere taak in andere vensters uitvoerde.
 Het wachten is de moeite waard, de plug-in die ik wilde, waarmee ik één vraag kon stellen en alle AI's tegelijkertijd konden antwoorden, is net vers van de pers.
Het wachten is de moeite waard, de plug-in die ik wilde, waarmee ik één vraag kon stellen en alle AI's tegelijkertijd konden antwoorden, is net vers van de pers.
Dit is precies wat ik nodig heb~
Daarnaast, ik had toch al een platform gemaakt voor het genereren van marketingvideo's met digitale mensen met één klik?
Later, om een betere ervaring na te streven, heb ik de frontend gerefactord. Deze refactoring was niet zonder gevolgen, het hele project was een complete chaos: de frontend- en backend-interfaces kwamen niet overeen, sommige oude backend-logica werkte niet met de nieuwe frontend, er waren veel bugs en het was erg lastig om op te lossen.
Deze keer activeerde ik de plan mode in Claude Code en gaf ik de taak om bugs te vinden en te repareren in het hoofdproces direct aan GLM-5.
Eerst kwam er een gedetailleerd plan:
Nadat ik had bevestigd dat het plan correct was, liet ik het beginnen met werken (tijdens het proces werd de browser mcp gebruikt om te controleren).
De uitvoeringssnelheid is niet hoog.
Maar het model is niet traag, vaak zie ik de snelheid waarmee de Token wordt verbruikt, met het blote oog stijgt het in een seconde naar duizenden.
Maar omdat de taak te complex is, moet het voortdurend zelf reflecteren, tools aanroepen en tests uitvoeren.
Een deel van de tijd wordt besteed aan het downloaden van afhankelijkheden of het uitvoeren van commando's.
Deze reparatietaak duurde ook meer dan 40 minuten.
Sommige vrienden zeggen misschien: 40 minuten? Dat had ik al lang geschreven.
Emm, maar in die 40 minuten had ik de schermopname aan, keek ik video's en liet ik zelfs de hond uit.
En het was geconcentreerd bezig met mijn werk, en dan nog wel het soort werk dat het meest frustrerend is: het vinden van bugs en het refactoren.
Hoewel het langzaam werkt, is het uiteindelijke effect zeer significant.
Toen ik het uitvoerde, waren de problemen in principe opgelost.
Bekijk de VCR:
Er zijn ook enkele effecten die ik later zelf heb getest en kleine bugs heb gevonden, die ik vervolgens heb laten repareren en optimaliseren.
Maar op het gebied van het repareren van bugs en het optimaliseren van functies vertrouw ik het echt toe aan het.
Vroeger, toen ik andere AI gebruikte om bugs te repareren, was ik vaak bang dat er steeds meer bugs zouden komen en dat het project steeds chaotischer zou worden, typisch het ene gat dichten en het andere openen..
Om dit probleem te vermijden, moest ik verschillende engineeringmethoden gebruiken om de AI te beperken.
Bijvoorbeeld, elke keer dat ik de reikwijdte benadrukte, of deze in de regels schreef, of elke keer slechts één bug repareerde, en elke keer dat ik klaar was met repareren, moest ik andere functies testen... Het was in ieder geval erg lastig.
Maar het gebruik van GLM-5 om bugs te repareren, is een heel andere ervaring.
Ik hoef alleen maar de huidige situatie te beschrijven, de foutenlogboeken naar het te gooien en te vertellen wat ik verwacht.
Het kan het bijna allemaal in één keer repareren en het heeft absoluut geen invloed op andere functies.
Sterker nog, in één gesprek gooide ik alle vier de verschillende bugs die ik in het hele proces had gevonden in één keer naar het toe, en het kon ze allemaal systematisch repareren.
Dit gevoel van stabiliteit is echt te comfortabel.
Ik kan GLM-5 nu met een gerust hart complexe ontwikkelingstaken laten uitvoeren, zonder dat er in principe fouten worden gemaakt.
Zelfs als er af en toe een probleem is, kan ik in Claude Code een rollback-commando uitvoeren en opnieuw beginnen.
Nadat het hele project met GLM-5 is geoptimaliseerd, zijn alle processen in principe voltooid.Ik ben ook van plan om dit project binnenkort open source te maken (ik moet nog het model API-gedeelte eruit halen en omzetten in een configuratie).
"Tot slot"
Mijn grootste gevoel na het ervaren van GLM-5 is: Chinese AI staat echt op.
Onlangs bracht ByteDance Seedance 2.0 uit, wat bewijst dat Chinese modellen op het gebied van videogeneratie het beste niveau ter wereld hebben bereikt, en Sora2 en Veo3.1 direct overtreffen.
En deze release van Zhipu GLM-5 heeft een onverwacht goed antwoord gegeven op een andere hardcore track, AI Coding.
Vroeger zeiden we altijd dat er een kloof was tussen Chinese modellen en GPT, Claude Opus en Gemini op het gebied van logisch redeneren en code schrijven.
Maar vandaag vertelt GLM-5 ons met concrete prestaties: deze kloof wordt gedicht.
GLM-5 is ook geen speeltje dat alleen kan worden gebruikt voor demo's, het is een productiviteitstool die je echt kan helpen met je werk, je kan helpen systemen te bouwen, je kan helpen lange taken en complexe problemen op te lossen.
Het belangrijkste is dat het open source is.
Dit betekent dat elke ontwikkelaar, elk bedrijf, een top AI-architect kan hebben tegen lagere kosten.
En momenteel is het GLM Coding Plan al uitverkocht, de officiële aankondiging zegt dat ze de capaciteit dringend uitbreiden, en de focus ligt op het feit dat deze keer een cluster van tienduizenden kaarten van Chinese chips is aangesloten.
Vanwege de verhoogde investeringen in rekenkracht is de prijs echter iets gestegen, gelukkig heb ik eerder het Max-pakket gekregen.
Hieruit kunnen we ook zien dat we, van chips tot modellen, van onderliggende rekenkracht tot applicaties op de bovenste laag, een complete set van onze eigen AI-technologiestack van wereldklasse aan het bouwen zijn.
2026 is voorbestemd om een jaar van explosie van AI-toepassingen te worden, en ook een gekker jaar.
Als je ook het gevoel wilt ervaren van het hebben van een top AI-architect, ga dan GLM-5 proberen.Voorwaarde is dat je het Max-pakket moet bemachtigen, haha.



