智谱GLM-5 desta vez de código aberto, tornando até mesmo programadores seniores perigosos...
Sério, a IA de 2026 é muito mais louca do que a de 2025.
Ultimamente, eu, que passo 16 horas por dia mergulhado em IA, estou tendo um pouco de dificuldade em acompanhar a velocidade da evolução da IA. Sinto que o mundo muda a cada dia que acordo.
E não é que ontem à noite, a Zhipu lançou outro grande trunfo, abrindo o código do seu modelo carro-chefe mais poderoso: GLM-5.
Na lista globalmente reconhecida da Artificial Analysis, o GLM-5 superou o Gemini e alcançou o quarto lugar global e o primeiro lugar em código aberto!
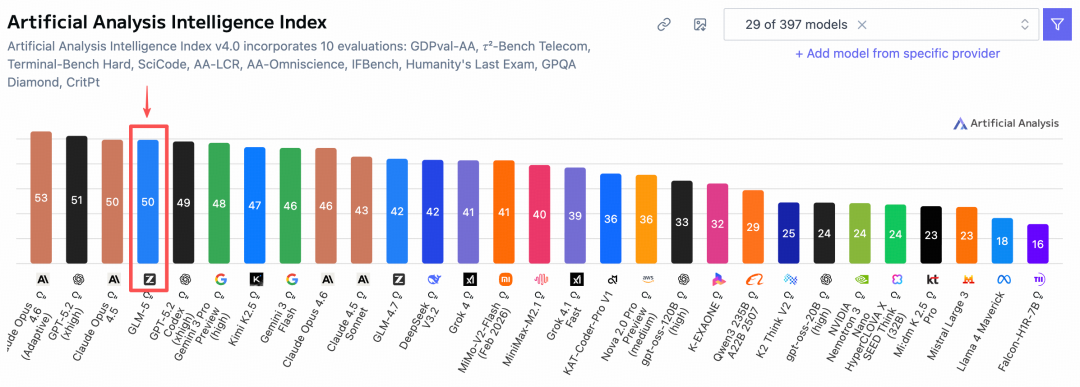
Como eu previa, lembro-me de quando o GLM-4.7 foi lançado, fiz uma previsão para os meus amigos no artigo: adivinhei que o GLM-4.8 ou GLM-5 seria lançado antes do Festival da Primavera, não esperava que realmente acontecesse, haha 😄
E desta vez, o número da versão finalmente não é como as atualizações anteriores de 4.5, 4.6, 4.7, que eram como espremer pasta de dente, desta vez foi direto para 5.0.
Isso mostra que não são pequenos ajustes, mas um grande salto na capacidade da base.
Primeiro, deixe-me apresentar o que o GLM-5 atualizou desta vez:
Simplificando, os modelos anteriores estavam geralmente envolvidos no Vibe Coding, que é a chamada geração de uma frase, para ver quem gera efeitos especiais de página da web mais legais, para ver quem pode criar um jogo legal com uma frase.
Mas o GLM-5 não vai competir com você nisso desta vez (finalmente!), ele elevou a capacidade do modelo grande de escrever código para ser capaz de construir sistemas.
O que isso significa? Seu foco não é mais escrever páginas front-end bonitas, mas evoluiu para um arquiteto de sistema que pode fazer trabalhos sujos, trabalhos pesados e tarefas longas.
A ênfase está na Agentic Engineering, ou seja, na capacidade de engenharia de agentes inteligentes.
Eu olhei para os dados oficiais, a escala de parâmetros saltou de 355B para 744B (ativação 40), e os dados de pré-treinamento aumentaram de 23T para 28.5T.
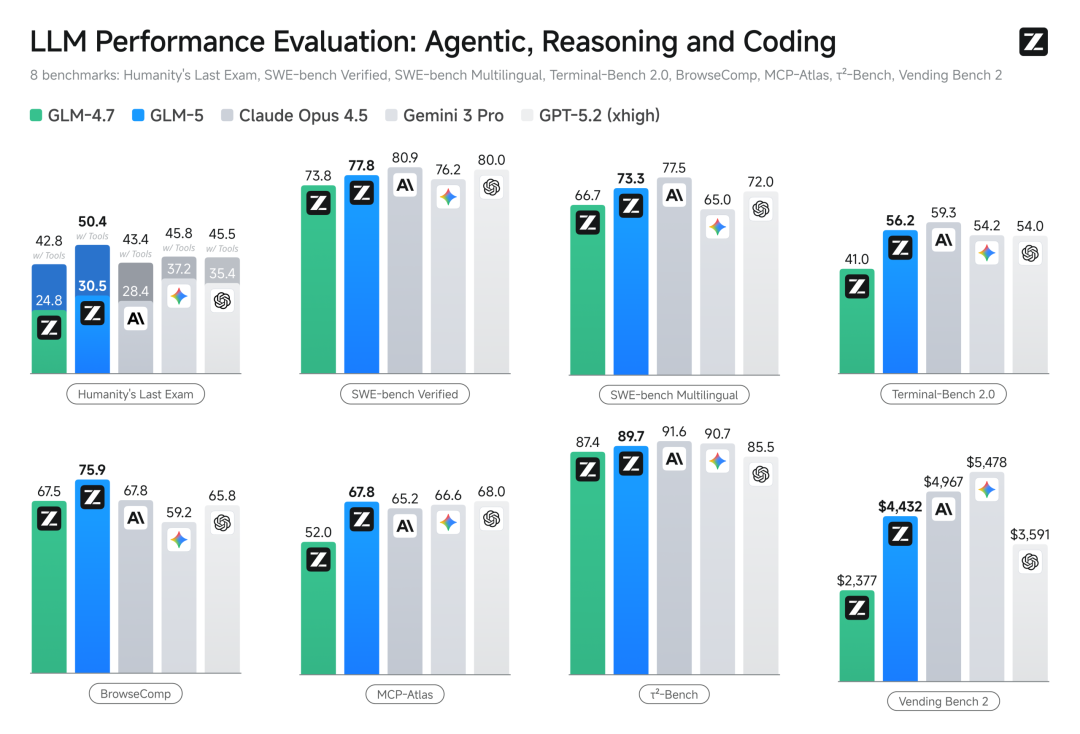
No teste de benchmark de programação reconhecido SWE-bench-Verified, a pontuação foi de 77.8, deixando diretamente o Gemini 3 Pro para trás, e pode-se dizer que está no mesmo nível do modelo de código fechado mais poderoso reconhecido atualmente, Claude Opus 4.5.
Atualmente, pode ser usado gratuitamente em z.ai:
Endereço de código aberto:
GitHub: https://github.com/zai-org/GLM-5
Hugging Face: https://huggingface.co/zai-org/GLM-5
ModelScope: https://modelscope.cn/models/ZhipuAI/GLM-5
Na verdade, há alguns dias, um modelo misterioso chamado Pony apareceu repentinamente no X.
Na época, muitos amigos estavam adivinhando, que tipo de divindade era esse Pony? Havia muitas opiniões diferentes
Na verdade, o modelo com o codinome Pony é o GLM-5, quanto ao porquê de se chamar Pony, provavelmente porque o Ano do Cavalo está chegando 🤔.
Na época, também conectei o Pony ao Claude Code do OpenRouter o mais rápido possível para experimentá-lo, para ser honesto, é realmente muito forte (a popularidade no X também é muito alta).
Levou apenas 7 minutos para gerar uma estação de transferência de API de uma só vez!
Embora ainda seja uma demonstração MVP, as funções da página já estão muito completas e incluem lógica de back-end e banco de dados, os dados são dinâmicos, embora pequeno, é completo.
 Após uma experiência profunda, descobri que o GLM-5 tem um sabor muito parecido com o Claude Opus ao fazer planos.
Após uma experiência profunda, descobri que o GLM-5 tem um sabor muito parecido com o Claude Opus ao fazer planos.
Amigos familiarizados com o Claude Opus sabem que, antes de começar a trabalhar, você pode usá-lo para listar um plano muito detalhado e logicamente rigoroso.
O GLM-5 agora também tem essa capacidade.
Por exemplo, tenho uma coisa que sempre quis fazer, mas nunca fiz por preguiça.
Tenho um monte de contas de membros do Gemini, ChatGPT, Kimi, Zhipu, etc.
Normalmente, ao escrever artigos ou pesquisar informações, muitas vezes quero ouvir as opiniões de várias IAs sobre algumas perguntas e comparar abrangentemente.Então eu teria que abrir várias janelas do navegador, copiar e alternar entre diferentes janelas para colar e enviar várias vezes, e então alternar entre as janelas para verificar os resultados.
Embora não seja grande coisa, é realmente irritante quando feito muitas vezes.
Eu estava pensando, será que posso fazer um plugin de navegador que possa enviar a mesma pergunta para as páginas web desses quatro AIs simultaneamente em uma única janela, e então receber as respostas de forma unificada no plugin?
Mas essa coisa é bem problemática, porque a estrutura de cada site de IA é diferente, e também existem vários mecanismos de proteção, que precisam ser analisados em suas estruturas DOM.
Então, eu entreguei essa tarefa complexa para o GLM-5.
Ativei o Plan Mode do Claude Code primeiro para deixá-lo fazer um plano
E então ele também interage comigo, perguntando minha opinião:
O plano final obtido é muito detalhado, realmente muito longo, com 633 linhas..
Então comecei a executá-lo passo a passo de acordo com o plano, mas não esperava que o primeiro passo de inicialização do projeto levasse mais de 50 minutos..
Nesse processo, ele chamou automaticamente a ferramenta Playwright MCP, abriu o navegador sozinho e acessou os sites daqueles AIs.
Ele é como um programador de verdade, verificando elementos, analisando onde está a caixa de entrada, qual é a classe do botão de envio, como obter o fluxo de texto retornado... todo o processo é totalmente automático, eu não escrevi uma única linha de código.
PS: Esqueci de gravar a tela, porque eu também estava executando outra tarefa em outra janela ao mesmo tempo
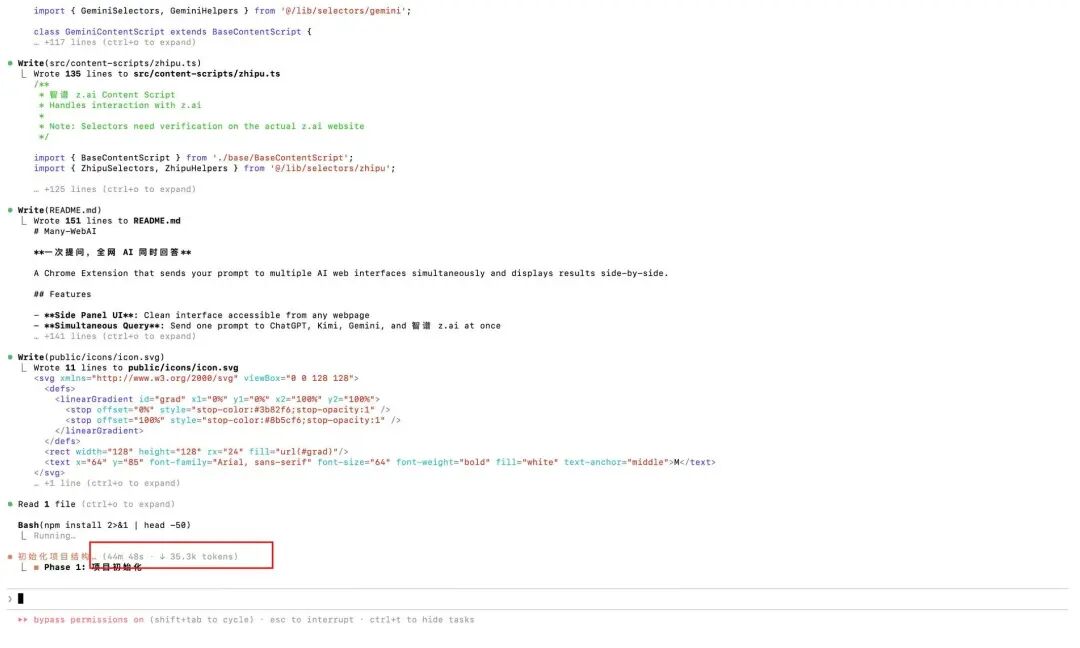 A espera valeu a pena, o plugin que eu queria, com uma pergunta e respostas simultâneas de toda a rede de IA, nasceu assim, quentinho.
A espera valeu a pena, o plugin que eu queria, com uma pergunta e respostas simultâneas de toda a rede de IA, nasceu assim, quentinho.
Isso é exatamente o que eu precisava~
Além disso, eu não tinha feito antes uma plataforma de geração de vídeos de marketing com humanos digitais com um clique?
Mais tarde, para buscar uma melhor experiência, eu refatorei o frontend, e essa refatoração foi um desastre, todo o projeto ficou uma bagunça: as interfaces frontend e backend não correspondiam, algumas lógicas antigas do backend não funcionavam com o novo frontend, havia muitos bugs, e era muito problemático para resolver.
Desta vez, eu ativei o plan mode no Claude Code, e então entreguei diretamente a tarefa de encontrar e corrigir bugs no fluxo principal para o GLM-5
Primeiro, saiu um plano detalhado:
Depois de confirmar que o plano estava correto, eu o deixei começar a executar passo a passo (o navegador mcp foi usado para controlar durante o processo).
A velocidade de execução não é rápida.
Mas não é que o modelo seja lento, muitas vezes, eu vejo a velocidade de consumo de Token, visivelmente saltando para mais de mil em um segundo.
Mas como a tarefa é muito complexa, ele precisa constantemente se auto-refletir, chamar ferramentas e executar testes.
Algum tempo também é gasto no download de dependências ou na execução de comandos.
Essa tarefa de correção também levou mais de 40 minutos.
Alguns amigos podem dizer, 40 minutos? Eu já teria terminado de escrever.
emmm, mas nesses 40 minutos, eu estava com a gravação de tela ligada, assistindo vídeos e até levei o cachorro para passear.
E ele estava totalmente concentrado em me ajudar a trabalhar, e estava fazendo o tipo de trabalho mais irritante de encontrar bugs e refatorar.
Não importa que ele execute lentamente, mas o efeito final é muito significativo.
Quando eu executei, nossa, os problemas foram basicamente resolvidos.
Por favor, veja o VCR:
Aqui também há alguns efeitos que eu descobri pequenos bugs ao testar posteriormente, e então deixei ele corrigir e otimizar.
Mas na correção de bugs e otimização de funções, eu realmente confio nele.
Antes, quando usava outras IAs para corrigir bugs, eu sempre me preocupava que mais bugs fossem adicionados, e que o projeto ficasse mais bagunçado, tipicamente tirando de um lado para colocar do outro..
Antes, para evitar esse problema, eu tinha que usar vários meios de engenharia para restringir a IA.
Por exemplo, enfatizar o escopo de cada modificação, ou escrever isso nas regras, ou modificar apenas um bug de cada vez, e depois de cada modificação, eu tinha que testar outras funções... de qualquer forma, era muito problemático.
Mas usar o GLM-5 para modificar bugs, a experiência mudou completamente.
Eu só preciso descrever a situação atual, jogar os logs de erro para ele e dizer a ele qual é o efeito que eu espero.
Ele quase sempre consegue corrigir com sucesso de uma vez, e não afeta outras funções.
Até mesmo, em uma conversa, eu joguei todos os quatro bugs diferentes encontrados em todo o processo para ele de uma vez, e ele conseguiu corrigi-los um por um de forma clara.
Essa sensação de estabilidade é realmente muito confortável.
Agora eu posso confiar no GLM-5 para me ajudar a completar qualquer tarefa de desenvolvimento complexa, basicamente sem erros.
Mesmo que haja problemas ocasionais, no máximo, execute um comando de rollback no Claude Code, volte e comece de novo.
Depois que todo o projeto foi otimizado com o GLM-5, todos os processos foram basicamente resolvidos.Eu também estou me preparando para abrir este projeto em breve (ainda preciso extrair a parte da API de vários modelos e transformá-la em configuração).
"Finalmente"
Depois de experimentar o GLM-5, minha maior sensação é: A IA nacional realmente se levantou.
Há alguns dias, o Seedance 2.0 da ByteDance foi lançado, provando que os modelos nacionais chineses atingiram o nível número um do mundo no campo da geração de vídeo, superando diretamente o Sora2 e o Veo3.1.
E desta vez, o lançamento do Zhupu GLM-5 entregou uma resposta além das expectativas em outra faixa difícil, a IA Coding.
Costumávamos dizer que os modelos nacionais tinham uma lacuna em relação ao GPT, Claude Opus e Gemini em raciocínio lógico e escrita de código.
Mas hoje, o GLM-5 nos diz com desempenho sólido: essa lacuna está sendo eliminada.
O GLM-5 também não é um brinquedo que só pode ser usado para demonstrações, é uma ferramenta de produtividade que realmente pode ajudá-lo a trabalhar, ajudá-lo a construir sistemas, ajudá-lo a resolver tarefas longas e problemas complexos.
O mais importante é que é de código aberto.
Isso significa que cada desenvolvedor, cada empresa, pode ter um arquiteto de IA de primeira linha a um custo menor.
E atualmente o Coding Plan do GLM já está esgotado, o anúncio oficial diz que está expandindo urgentemente e, o mais importante, desta vez está conectado a um cluster de dezenas de milhares de placas de chips nacionais.
No entanto, devido ao aumento do investimento em poder de computação, o preço aumentou um pouco, ainda bem que eu consegui o pacote Max antes.
Isso também mostra que, de chips a modelos, de poder de computação subjacente a aplicações de nível superior, estamos construindo um conjunto de pilha de tecnologia de IA de classe mundial que é totalmente nossa.
2026 está fadado a ser um ano de explosão de aplicações de IA e também um ano mais louco.
Se você também quer experimentar essa sensação de ter um arquiteto de IA de primeira linha, vá experimentar o GLM-5.Pré-requisito: você tem que conseguir o pacote Max, haha.



