智谱GLM-5这次开源,让高级程序员也危险了...
真的,2026年的AI比25年疯太多了。
最近我这个一天16个小时泡在AI里面的人,都有点追不上AI进化的速度。感觉每天一睁眼,世界就变了个样。
这不,昨天深夜,智谱又放了个大招,直接开源了他们目前最强的旗舰模型:GLM-5。
在全球权威的Artificial Analysis榜单里面,GLM-5超越Gemini干到了全球第四、开源第一!
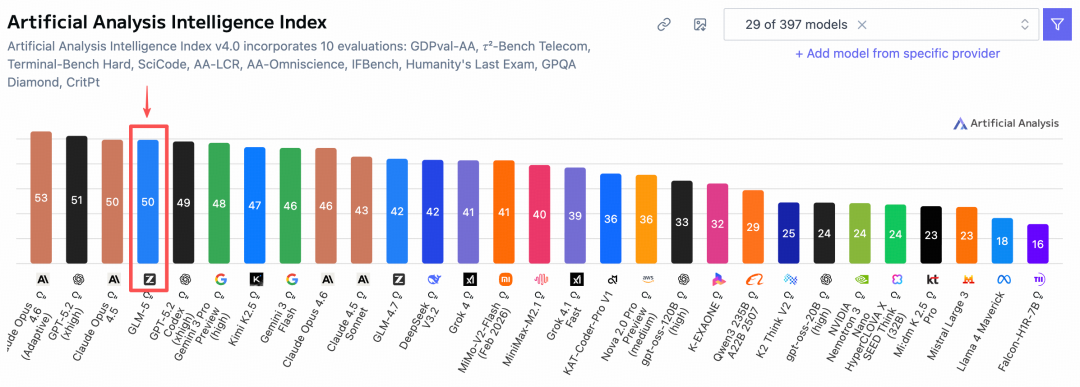
还真是如我所料啊,记得上次GLM-4.7发布的时候,我就在文章里跟兄弟们预测了一波:盲猜GLM-4.8或者GLM-5将在春节前夕发布,没想到真来了,哈哈😄
而且这次的版本号终于不像之前那样4.5、4.6、4.7这样挤牙膏式的更新了,这次直接干到了5.0。
这就说明,不是什么小修小补,是底座能力的大跨越。
先给大家介绍一下,这次GLM-5到底更新了啥:
简单来说,之前的模型,大家普遍都在卷Vibe Coding,就是所谓的一句话生成,看谁生成的网页特效更炫酷,看谁能一句话搓个炫酷的游戏。
但GLM-5这次不跟你卷这个了(终于!),它把大模型的能力从写代码,提升到能构建系统。
什么意思呢?它的重心不再是写漂亮的前端页面,而是进化成了一个能干脏活、累活、做长任务的系统架构师。
强调的是Agentic Engineering,也就是智能体工程能力。
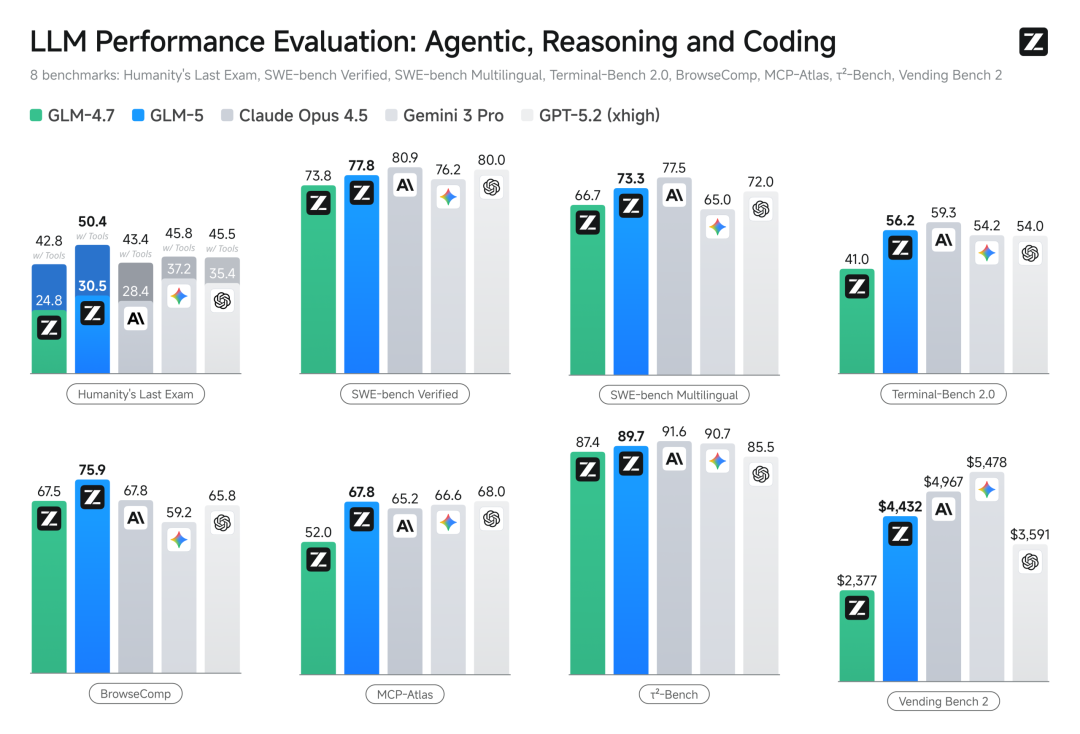
我看了下官方的数据,参数规模从355B干到了744B(激活40),预训练数据从23T提升到了28.5T。
在SWE-bench-Verified这个公认的编程基准测试里,得分77.8,直接把Gemini 3 Pro甩在了身后,和目前公认的最强闭源模型Claude Opus 4.5可以说是不相上下。
目前在z.ai上面就可以免费使用:
开源地址:
GitHub:https://github.com/zai-org/GLM-5
Hugging Face:https://huggingface.co/zai-org/GLM-5
ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5
其实在前几天,X上就突然冒出来一个叫Pony的神秘模型。
当时很多朋友都在猜,这个Pony到底是哪路神仙?众说纷纭
其实代号Pony的模型就是GLM-5,至于为什么叫Pony呢,大概是因为马年快到了吧🤔。
我当时也第一时间从OpenRouter把Pony接入到Claude Code里试用了一下,说实话,真滴很强(在X上热度也是非常高)。
只花了7分钟,一次性生成了一个API中转站!
虽然还是MVP Demo,但是页面功能已经很齐全了,而且包含后端逻辑,以及数据库,数据是动态的,麻雀虽小五脏俱全。
 在深度体验后,我发现GLM-5在制定计划的时候,那种味道,太像Claude Opus了。
在深度体验后,我发现GLM-5在制定计划的时候,那种味道,太像Claude Opus了。
熟悉Claude Opus的朋友都知道,在干活之前,可以用它会给你列一个非常详细、逻辑严密的计划。
GLM-5现在也有了这个能力。
比如,我有一个一直想做,但是因为懒一直没动手的事儿。
我手头有Gemini、ChatGPT、Kimi、智谱等等一堆会员账号。
平时写文章或者查资料的时候,有些问题我经常会想听听多个AI的意见,综合对比一下。那我就得打开多个浏览器窗口,复制切换不同窗口粘贴发送多次,然后轮流切换窗口查看结果。
虽然也不是多大的事儿,但次数多了真的很烦。
我就在想,能不能做一个浏览器插件,能统一在一个窗口里面,同时向这四个AI的网页端发送同一个问题,然后在插件里面统一收到回复?
但是这玩意儿还挺麻烦的,因为每个AI网站的结构都不一样,还有各种保护机制,需要去分析它们的DOM结构。
于是,我就把这个复杂的任务交给了GLM-5。
开启Claude Code的Plan Mode先让它做个计划
然后它还会跟我互动,询问我的意见:
最终得到的计划非常详细,真的太长了,有633行。。
然后就按照计划开始吭哧吭哧执行了,没想到第一步初始化项目就跑了50多分钟..
在这个过程中,它自动调用了Playwright MCP工具,自己打开浏览器,去访问那几个AI的网站。
它就像一个真的程序员一样,去键检查元素,去分析输入框在哪里,发送按钮的Class是什么,怎么获取返回的文本流...整个过程全自动,我一行代码都没写。
PS:忘记录屏了,因为我同时还在其他窗口跑另一个任务
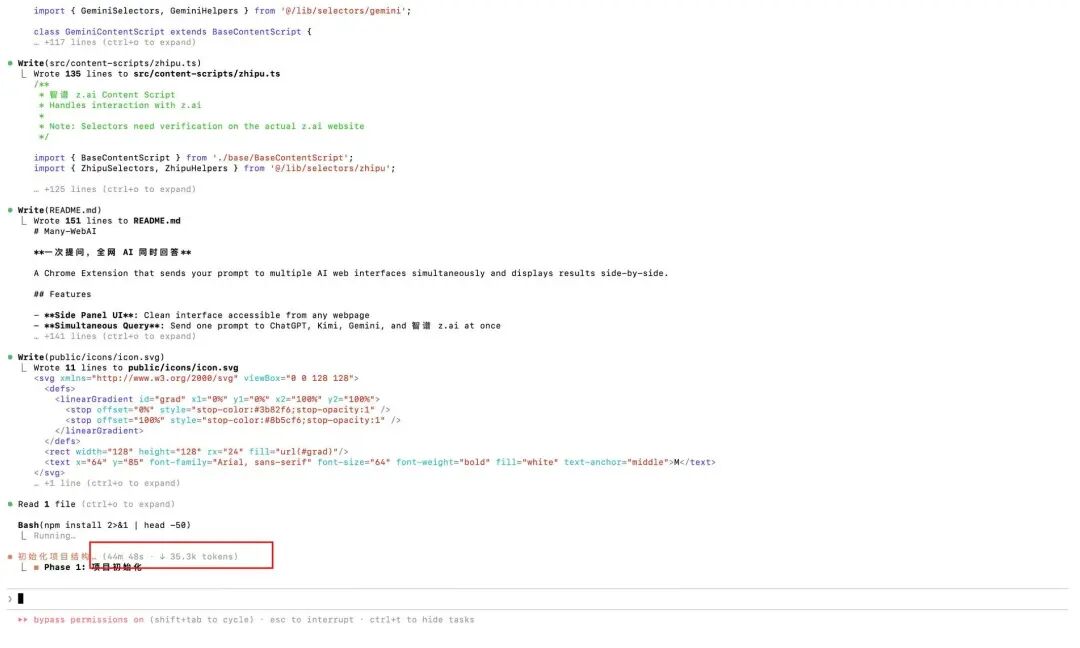 等待是值得的,我想要的一次提问、全网AI同时回答的插件,就这么热气腾腾地出炉了。
等待是值得的,我想要的一次提问、全网AI同时回答的插件,就这么热气腾腾地出炉了。
这完全就是我需要的东西~
另外,我之前不是做了一个数字人营销视频一键生成平台嘛。
后来为了追求更好的体验,我重构了一下前端,这一重构不要紧,整个项目可以说是乱成了一锅粥:前后端接口对不上,后端的一些老旧逻辑在新前端面前跑不通,Bug非常多,搞起来很麻烦。
这次,我在Claude Code开启plan mode,然后直接把主流程找bug,改bug的任务甩给了GLM-5
先出来一份详细的计划:
确认计划无误后,我就让它吭呲吭呲开始执行了(过程中用到了浏览器mcp来控制)。
它的执行速度并不快。
但并不是模型慢,很多时候,我看那个Token的消耗速度,肉眼可见地一秒钟就窜到上千了。
但是因为任务太复杂,它需要不断地自我反思、调用工具、运行测试。
也有一些时间是消耗在依赖下载,或者命令执行上。
这个修复任务,也整整执行了40多分钟。
可能有的朋友会说,40分钟?我都写完了。
emmm,但这40分钟里,我就开着录屏,刷视频,甚至去遛了狗。
而它是在全神贯注帮我干活,而且是干那种最让人头秃的找Bug和重构的活。
别看它执行得慢,但是最终得到的效果是非常显著的。
我一运行,好家伙,问题基本都搞定了。
请看VCR:
这里面也有一些效果是我后续自己测的时候发现小Bug,然后让它修复并优化的。
但是在修Bug和优化功能这块,我是真的放心交给它。
以前用别的AI改Bug,经常是担心bug越改越多,项目越改越乱,典型的拆了东墙补西墙..
之前为了规避这个问题,得用各种工程化的手段去约束AI。
比如每次修改 强调范围,或者把这些写到规则里面,或者每次只改一个bug,每次改完,还得测一下别的功能...反正很麻烦。
但是用GLM-5修改Bug,体验完全变了。
我从来就是只需要描述现状,把报错日志丢给它,告诉它我期望的效果是什么。
它几乎都能一次修复成功,而且完全不会影响别的功能。
甚至,我在一次对话中,直接把整个流程中发现的四个不同的Bug,一股脑全扔给它,它也能条理清晰的一个个修好。
这种稳健的感觉,真的太舒服了。
我现在可以放心交给GLM-5帮我完成任何复杂的开发任务,基本不会出错。
即便偶尔有问题,大不了在Claude Code里面执行一下回滚命令,倒回去重来就好了。
整个项目用GLM-5优化了一圈之后,所有流程基本都搞定了。Também estou me preparando para abrir este projeto em breve (ainda preciso extrair a parte da API de vários modelos e transformá-la em configuração).
"Finalmente"
Depois de experimentar o GLM-5, meu maior sentimento é: A IA nacional realmente se levantou.
Há alguns dias, o Seedance 2.0 da ByteDance foi lançado, provando que os modelos nacionais chineses atingiram o nível número um do mundo no campo da geração de vídeo, superando diretamente o Sora2 e o Veo3.1.
E o lançamento do Zhipu GLM-5 desta vez entregou uma resposta além das expectativas em outra faixa hardcore, o AI Coding.
Costumávamos dizer que os modelos nacionais tinham uma lacuna em relação ao GPT, Claude Opus e Gemini em raciocínio lógico e escrita de código.
Mas hoje, o GLM-5 nos diz com desempenho sólido: essa lacuna está sendo eliminada.
O GLM-5 também não é um brinquedo que só pode ser usado para demonstrações, é uma ferramenta de produtividade que realmente pode ajudá-lo a trabalhar, ajudá-lo a construir sistemas, ajudá-lo a resolver tarefas longas e problemas complexos.
O mais importante é que é de código aberto.
Isso significa que cada desenvolvedor e cada empresa pode ter um arquiteto de IA de primeira linha a um custo menor.
E atualmente o Coding Plan do GLM já está esgotado, o anúncio oficial diz que está sendo expandido urgentemente e, o mais importante, desta vez está conectado ao cluster de dez mil cartões de chips nacionais.
No entanto, devido ao aumento do investimento em poder de computação, o preço aumentou um pouco, felizmente eu consegui o pacote Max antes.
Isso também pode ser visto que, de chips a modelos, de poder de computação subjacente a aplicações de camada superior, estamos construindo um conjunto de pilha de tecnologia de IA de classe mundial que é totalmente nossa.
2026 está destinado a ser um ano de explosão de aplicações de IA e também um ano mais louco.
Se você também quiser experimentar a sensação de ter um arquiteto de IA de primeira linha, vá e experimente o GLM-5.Pré-requisito é conseguir o pacote Max, haha.



